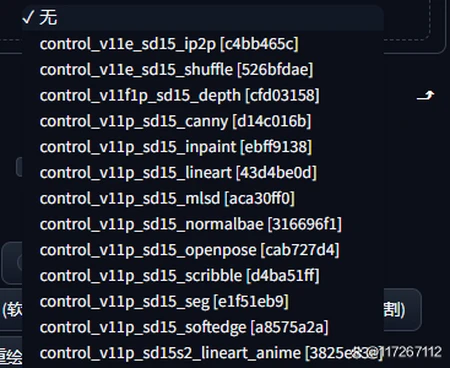
Stable Diffusion stablediffusion的ControlNet插件:让创作更加可控 Stable diffusion的插件ControlNet,其功能类似盲盒,能控制创作中的人...