Baichuan
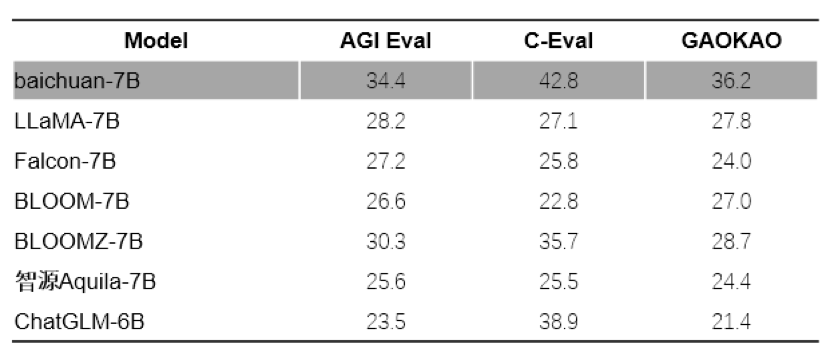
作者 | 程茜 编辑 | 心缘 智东西12月19日报道,今天,百川智能宣布开放基于搜索增强的Baichuan2-Turbo系列API,包含Baichuan2-Turbo-192K及Baichuan2-Turbo,并增加了搜索增强知识库。 官网接口说明:https://platform.baichuan-ai.com/playground 百川智能创始人、CEO王小川谈道,搜索增强是大模型时代的必由之路,能够有效解决大模型幻觉、时效性差、专业领域知识不足等核心问题。 百川智能以Baichuan2大模型为核心,将搜索增强技术与大模型深度融合,结合此前推出的192k超长上下文窗口,构建了一套大模型+搜索增强的完整技术栈,实现了大模型和领域知识、全网知识的连接。 目前,行业大模型在应用落地方面仍面临诸多问题,如企业的训练成本、人才储备等。一方面,百川智能的搜索增强技术可以提升大模型的性能,同时让其“外挂硬盘”,拥有互联网实时信息和企业的自有知识库;另一方面,搜索增强技术能够帮助大模型理解用户的意图,在企业的知识库文档中找到相应的知识,然后对结果进行总结提炼生成结果。 百川智能联席总裁洪涛告诉智东西,他们并不否定行业大模型,但从技术的视角看,绝大部分场景下百川智能的搜索增强方案可以替代行业大模型。 一、大模型落地难题:幻觉、时效性差、专有知识不足 现阶段,大模型仍存在很多问题,也是其走向行业落地必须面对的挑战。 首先,大模型存在幻觉,目前一些玩家通过训练更大的模型去减少幻觉,但这伴随着成本变高。 其次,大模型的数据库是静态的,王小川认为,大模型是一个时效性较差的系统。 第三,大模型商业落地的过程中专业知识不足,这是因为每个企业都有自己的私域数据,且需要实时更新。 因此,王小川认为,解决这三个问题,光靠模型本身做的大是不够的。 目前,行业里有一大策略就是,大模型加搜索才能构成完整的技术栈,王小川谈道,此前百川智能做大模型比较快的原因就是,掌握搜索技术能更好收集数据。这是因为,大模型的数据、算法、算力都和搜索相关,搜索技术不仅能帮他们更快做出大模型,大模型+搜索还能完整形成模型加商业应用的逻辑闭环。 借助搜索增强,大模型和领域知识、全网知识形成全新的完整技术栈,有利于大模型真正实现落地。 王小川展示了一个行业里公认的表达,大模型是新时代的计算机。下面这张图就将大模型比做计算机,大语言模型就是中央处理器、上下文窗口就是内存、搜索增强就是硬盘。 不过更大内存、更强的处理器,依然不能解决大模型幻觉、外部知识引入、时效性等问题。王小川谈道,在用户指令和输出中,就可以通过搜索引擎将互联网实时信息和企业完整知识库,像硬盘一样装进去,也就是大模型加硬盘能即插即用,这就使得大模型在很多领域里更实用。 广告 胆小者勿入!五四三二一…恐怖的躲猫猫游戏现在开始! × ▲百川智能大模型支持实时信息更新 在学术界,也有一些知识注入等类似理念提出,可以将外部知识挂硬盘,也就是RAG(检索增强生成),谷歌、OpenAI等也在提出类似的理念。 二、人才、算力、时间、效果……行业大模型落地挑战众多 目前而言,企业满足自身需求的做法是搭建向量数据库。王小川谈道,向量数据库实际上是搜索里的一部分功能,搜索为了保证召回进度和效率会采用向量数据库。因此,做搜索的公司已经完整掌握了向量数据库这项技术,现在,百川智能对其经过新的研发后,让更大的模型实现更好的对接。 如今模型走向落地,一些企业落地应用大模型时很多需求没解决,所以需要打造行业大模型。王小川举了个例子,如常说的L0就是标准模型,L1就是在此之上经过垂直行业数据改造的行业大模型。 然而,用行业大模型来解决企业应用的过程中,仍然面临很多问题,包括人力、算力、时间、效果、更新、升级。 在改造的过程中,需要企业有非常多的经验积累,高质量的人才才能保证系统的可靠性和稳定性。与此同时,算力方面对于企业来说也是巨大的挑战,再加上训练周期长,还需要考虑基座模型升级的影响。 因此,王小川认为,行业大模型目前并没有良好的实践案例,还面临很多问题。 三、长文本、向量数据库是基操,百川智能提出差异化解决方案 在行业模型之外,常规的解决方法是向量数据库和长窗口,王小川谈道,这两个事情是基操,百川的解决方案还包括独有的:实现稀疏检索与向量检索并行、搜索系统和大模型对齐。 其中,稀疏检索就是原来他们原来做搜索引擎时用到的机遇符号系统的方式,这种情况下向量检索语义会更加贴近。 另一大特点就是搜索系统和大模型对齐,他解释说,以前用户提问会通过一个关键词表达一个词或者短剧,今天用户提问是一个完整的问题,如何通过稀疏检索、向量检索跟这套系统相对接,就是新的技术点。 搜索和长窗口模型产生的技术挑战包括,用户场景变化,用户会提出上下文相关的prompt,与传统搜索不同;第二为如何实现高召回、高准确的搜索系统;第三为长窗口在容量、性能、成本和效率方面的问题;第四是长窗口结合搜索,对搜索召回精度要求极高。 面对这些挑战,百川智能提出了一系列解法。 今年10月,百川智能发布了Baichuan2-192k大模型,可以支持一次性输入35万字。同时,百川智能在中文语义向量综合表征能力评测C-MTEB中排名第一。 同时,该公司还实现了稀疏检索和向量检索并行,通过调优后比向量检索的可用率从80%提到95%。王小川谈道,这件事意味着将向量检索带到了新的高度。 在搜索系统和大模型对齐方面,有prompt2query和doc2query两种方案,能够对齐用户的需求。 通过这样一系列的操作,百川智能的解决方案就解决了行业大模型不可行的问题。同时大模型的外存加内存能提升两个数量级的信息处理量,大模型的处理速度更快、成本更低。王小川谈道,这种解决方案提升了几百倍的检索量后,比单用长窗口的成本更低、速度更快。 四、解决行业大模型不可行难题,文本规模达到5000tokens 总的来看,王小川认为,相比于行业大模型,百川智能的搜索增强方案在人力、算力、时间、效果、更新、升级方面都更有优势。 此前企业要自己学行业模型,需要稀有的大模型人才,并使用大量算力训练很长时间,现在只需要挂上“外部硬盘”就可以直接调用大模型能力,同时还能保证模型的可靠性及应用稳定性。...