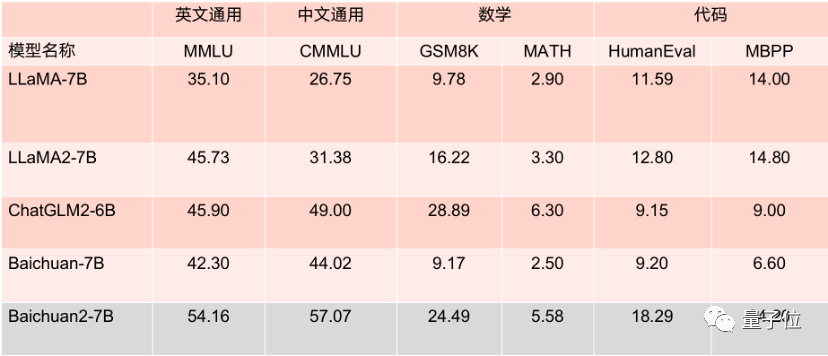
Baichuan
#城市心跳计划# 今天,百川智能宣布已完成3亿美元的A1轮战略融资,阿里、腾讯、小米等科技巨头及多家顶级投资机构均参投了本轮融资,公司正式跻身科技独角兽行列,创下国内大模型初创企业最快晋升独角兽的记录。 投资界独家获悉,“本土VC之王”深创投也是本轮投资方之一。不久前,百川智能创始人王小川出席在深圳举行的深创投2023投资年会,以被投企业身份发表了主题演讲。此笔投资,极具意味——深圳正在重注AI产业。 说起来,创投圈对王小川并不陌生。1996年,王小川被点招入清华大学计算机系,研究生毕业后便加入搜狐。从搜狐到搜狗,王小川在互联网时代留下了不少记忆。直到今年4月,他官宣自己的大模型创业之旅,旨在打造中国版OpenAI。 今年以来,AI大模型成为了国内一级市场最火爆的赛道之一,挤满了形形色色的投资人。不止如此,城市也加入了——如深圳一般,国内几乎各大城市都悄悄投身这场未来超级产业之战。 第二次创业 王小川干出10亿美元估值 这是王小川的第二次创业。 出生于1978年,王小川从小学习优异,尤其在数学和计算机竞赛中成绩不俗。1990年,他以成都市第一名的成绩考入成都七中数学实验班,三年后又以全国数学联赛一等奖被保送入成都七中高中部。 即将升入高三的那个暑假,王小川偶然有机会亲身进入清华大学计算机系实验室,看到了研究生在里面做实验。“我第一感觉是高级、神秘,这就是科研在我心中代表的至高无上的方向。”王小川曾在清华计算机系的采访中回忆道。 这次近距离接触,最终引领王小川来到了清华计算机系。1996年,他凭借国际奥林匹克信息学竞赛金牌,被点招入清华大学计算机系,在清华先后获得工学学士、工学硕士、EMBA学位。 在本科期间,王小川加入华人青年社区ChinaRen创业项目实习,首次接触到了“搜索”,甚至开发了提问式搜索引擎“孙悟空搜索”。而随着次年搜狐收购了ChinaRen,王小川由此进入了搜狐。完成研究生学业后,他正式加入搜狐,先是担任高级技术经理,做出了第三代中文搜索引擎——搜狗,在2005年晋升为搜狐当时最年轻的副总裁。 2006年搜狗输入法面世,紧接着推出了搜狗浏览器,与搜狗搜索构成了“三级火箭”,让王小川和搜狗声名鹊起。2010年,搜狗从搜狐分拆单独运营,王小川成为搜狗公司CEO。时隔三年,腾讯以占比36.5%的股份、4.48亿美元战略入股搜狗,后者也在王小川的带领下于2017年登陆纽交所。 转折点发生在2020年7月,腾讯向搜狗发出全资收购要约,这笔11.8亿美元的收购案最终在2021年10月尘埃落定,王小川宣布卸任搜狗CEO。 直到今年4月,王小川再次亮相,官宣了自己的大模型创业之旅——和前搜狗COO、清华1998级校友茹立云联合创立人工智能公司——百川智能。据王小川介绍,百川本意是众多的河流汇集奔赴海洋,象征着众多数据、行业知识汇聚成为一个强大的智能体系,生生不息。 谈及新的创业,王小川直言,要比当年搜索引擎时候的成就感更大,现在做大模型与搜索的模型做了一定程度的结合,事情比原来更吸引人。“其实挺愉悦的,我们的进度是在一个快乐的状态。” 此后,王小川与百川智能动作迅速,成立半年,便接连发布baichuan-7B/13B,Baichuan2-7B/13B四款开源可免费商用大模型及Baichuan-53B、Baichuan2-53B两款闭源大模型。其中Baichuan-7B/13B两款大模型在多个权威评测榜单均名列前茅,累积下载量突破六百万次。Baichuan 2更是在各维度全面领先Llama 2,引领了中国开源生态发展。8月31日百川智能率先通过《生成式人工智能服务管理暂行办法》,是唯一一家今年创立的大模型公司。9月25日,百川智能开放Baichuan API接口,正式进军To B领域,开启商业化进程。 百川智能表示,Baichuan大模型,融合了意图理解、信息检索以及强化学习技术,结合有监督微调与人类意图对齐,在知识问答、文本创作领域表现突出。目前已有阿里云、腾讯云、火山引擎、浪潮、顺丰科技等超过300家合作伙伴使用Baichuan大模型。 随着融资消息发布,百川智能也宣布启动2024届校园招聘并发起“星耀计划”。本次校招将面向海内外学生,同时覆盖北上广深等多个城市多所高校,目前百川智能是2024届校园招聘规模最大的大模型初创企业。 据介绍,“星耀计划”是百川智能面向全球精英科技人才的专项校园招聘计划。岗位涵盖了自然语言处理、计算机视觉、强化学习、基础架构等多个人工智能关键技术方向,旨在寻找有技术理想,热爱AI领域的精英。 成立之初,王小川曾透露,公司早前已获得5000万美元启动资金,来自自己与业内好友的个人支持。而在今年8月初的一次媒体交流中,王小川再度表示百川智能第一次融资时,估值已超过5亿美元。如今,百川智能成立不到半年时间便跻身科技独角兽行列,创下国内大模型初创企业晋升独角兽速度之最。 AI崛起一支清华系 排队宣布融资 不只是王小川,眼下最火的AI大模型赛道,清华系可谓是一骑绝尘。 这当中,王慧文率先打破平静。今年年初,王慧文宣布进军人工智能领域,为自己参与创立的AI公司光年之外招揽人才,本人率先出资5000万美元。作为清华老同学,王兴鼎力支持,参与了光年之外的A轮投资,并出任董事。 期间,光年之外还与一流科技达成并购,后者成立于2017年,创始人兼CEO袁进辉同样为清华校友,是该校计算机系工学博士,曾任微软亚洲研究院主管研究员。但可惜的是,王慧文在6月底被曝出因病离岗,光年之外随后也被美团全资收购。 最新案例则是大模型创业公司月之暗面——由清华大学交叉信息学院、智源青年科学家杨植麟教授领衔,两位联合创始人周昕宇和吴育昕也均出身清华。投资界获悉,公司已获得红杉、今日资本、砺思资本、真格基金等知名机构近20亿元投资。 同样来自清华系的深言科技也备受关注。今年6月,公开信息显示,北京深言科技有限责任公司发生工商变更,股东新增腾讯旗下广西腾讯创业投资有限公司等。据了解,深言科技创始人兼CEO岂凡超为清华大学计算机系博士,是孙茂松教授的学生;联合创始人兼COO李潇翔则是清华大学电子系博士。 稍早前的4月份,面壁智能完成由知乎领投的数千万元天使轮融资,种子轮股东智谱AI继续跟投。这同样是一家清华系AI公司,创始团队来自于清华大学计算机系自然语言处理与社会人文计算实验室,联合创始人刘知远为清华大学计算机系长聘副教授,智源青年科学家;联合创始人以及CTO曾国洋为悟道·文源中文预训练模型团队骨干成员。 值得注意的是,本轮跟投方智谱AI同样出自清华,由清华大学计算机系知识工程实验室的技术成果转化而来。核心团队中,CEO张鹏毕业于清华计算机系,董事长刘德兵系中国工程院高文院士弟子,总裁王绍兰为清华创新领军博士,清华大学计算系教授唐杰也参与孵化。此前,智谱AI获得数亿元B轮融资,由启明创投、君联资本联合领投,身处大模型风口之上,公司估值水涨船高。 再早之前,聆心智能宣布完成Pre-A轮融资,由 SEE Fund 领投,老股东超额跟投。公司成立于2021年11月,孵化自清华大学计算机系,致力于打造“超拟人大模型”。联合创始人黄民烈师从于清华大学计算机系教授、博士生导师朱小燕,他也曾参与智源“悟道”大模型的研发。 为何清华系AI创业者备受投资人的青睐? 在同样是清华校友的源码资本合伙人王星石看来,清华系AI创业者拥有强烈的科技创新愿景,善于深度探究事物的本质和规律,践行上坚守务实态度。 这离不开清华的底层文化。王星石说,清华一直推崇务实与创新,秉持为国家持续输出优秀高科技人才的理念,鼓励创业创新。因此在整体文化和氛围的烘托下,更容易催生和激发创业意识。“当一些行业如AI有创业创新机会时,这些专业知识过硬,又有创新思维和创业精神的同学,就会抓住机会,从而冲出不少顶尖创业者。” 为何会是深圳? 1000亿人工智能基金群 深创投此次出手百川智能,并非偶然。 这背后是深圳重注AI产业的一抹缩影。其实自2017年以来,深创投及管理基金累计推动260余家科技企业签约落户深圳。尤其近年来,深创投也围绕深圳市委、市政府重大战略部署,加大服务“20+8”产业集群发展支持力度。“国家需要什么,深创投就投资什么。”一定意义上来说,“深圳需要什么,深创投也投什么。” 而如今,AI正成为深圳的一张“新名片”,更是坐拥两个“全国最多”——《中国人工智能产业图鉴》公布的数据显示,截至2022年底,深圳人工智能企业的存续数量达到63763家,全国最多;从2016年至2022年期间,深圳人工智能产业链相关企业增长总量为42598家,全国最多。...