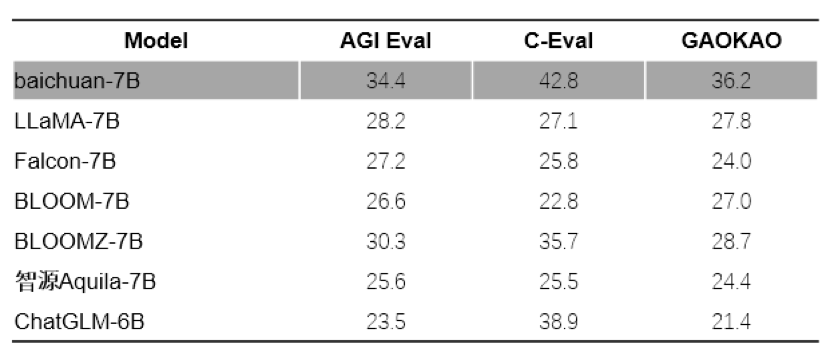
Baichuan 百川智能公司合作开发更加先进的模型;随着科技的发展,人工智能的应用领域越来越广泛,其中语言模型在自然语言处理、机器翻译、语音识别等方面发挥着重要作用预训练大 本文介绍了一种名为"百川-7B"的中文预训练大模型,该模型在C-Eval、AGIEval和G...