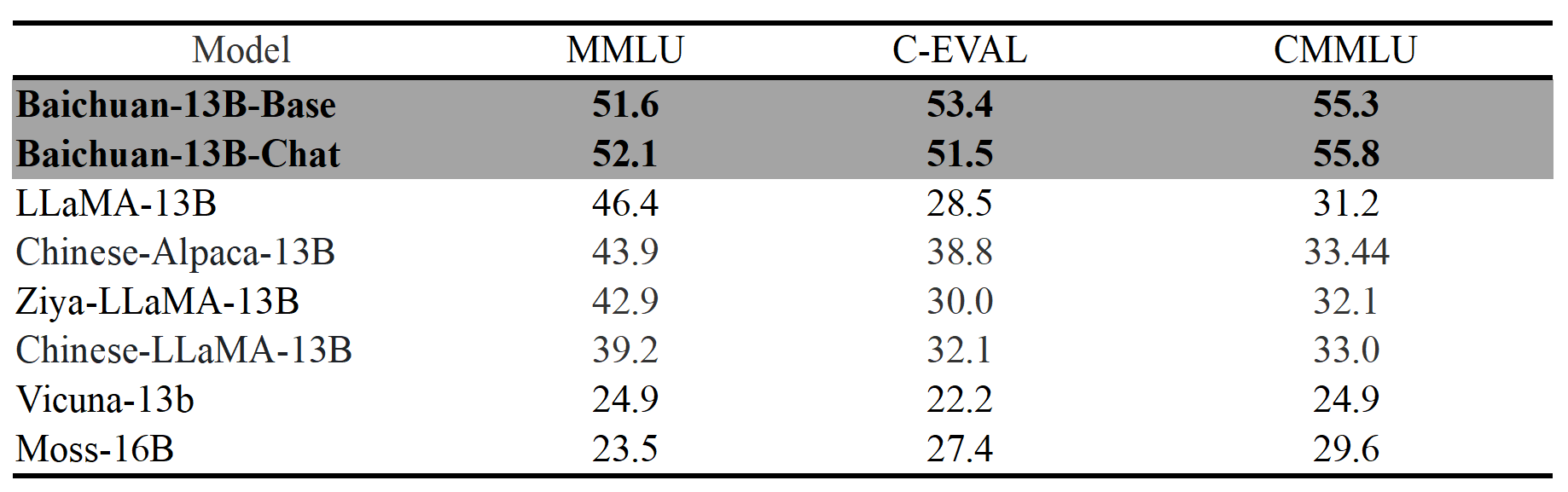
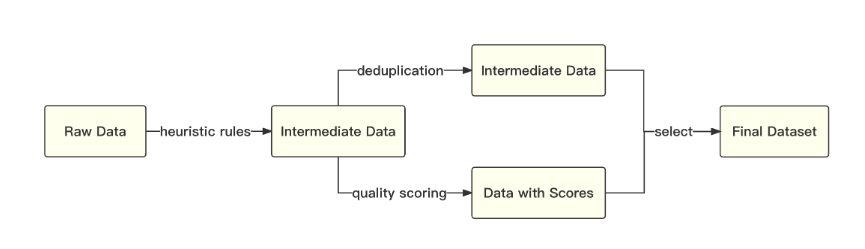
Baichuan 《百川智能发布通用大语言模型Baichuan-13B-Base及对话模型Baichuan-13B-Chat》 7 月 11 日,百川智能公司发布通用大语言模型 Baichuan-13B-Base、对话模...