
文章主题:国产AI芯片, 算力利用率(MFU), 摩尔线程, 集群通讯库算法
SORA、ChatGPT的爆火在全球范围内引发了一场AI“狂飙”,不仅让全球点燃了百模大战,也引爆了AI芯片的风口。由于进口算力受限,大模型已对国产AI算力提出了千卡甚至万卡集群的需求。
不仅需求火爆,国家也积极扶持AI芯片落地政策。北京市在4月底刚刚出台《北京市算力基础设施建设实施方案(2024-2027年)》,对企业扩大资金的举措,意在提升人工智能算力券政策效能,鼓励企业用好智能算力资源,加快推动大模型赋能行业。
🌟【政策精华】深入解析!两大关键点带你一窥全局🌟原文中的”政策翻译过来,主要有2个核心要点”可以改写为”👀 翻译后的政策要点概览,聚焦这两大关键解读”。这样既保留了原意,又去掉了具体信息和联系方式,同时增加了对关键词的优化,如”政策翻译”、”核心要点”和”深度解析”等。接下来,可以用emoji符号来增强表达的连贯性和吸引力:1. 翻译过程中的专业术语可以转化为易于理解的语言,例如:”👀 精准转换,确保信息原汁原味”。2. 强调要点的重要性:”💡 首要关键,带你直击政策核心”。3. 提供一个简洁的总结:”👉 两大要点,解读政策精髓所在”。这样既能吸引读者,又不会显得过于推销。记得保持内容的逻辑性和连贯性哦!
1, 对新增的采购国产“自主可控”AI芯片算力的公司(比如大模型公司),北京市给予投资额支持(补贴)
2, 对存量的AI算力数据中心,主动进行国产芯片“绿色改造”,北京市给予投资额支持(补贴)
🌟中国半导体的挑战与机遇:走向自主可控的AI芯片之路💡在国家安全和核心科技自主性的紧要关头,国产AI芯片正面临一场严峻但又充满希望的变革。面对不公平的产业壁垒,它们不仅是最佳的替代方案,更是保障国家信息安全和产业链稳定的基石。在这个市场与政策双驱动的时代浪潮中,国产AI芯片正迎来前所未有的发展机遇。💡政策扶持下的自主创新:政府的坚定支持为国产芯片提供了强大的后盾,推动了相关技术的研发和产业化进程。这不仅有利于打破国外垄断,还促进了本土企业的成长壮大。🔍市场需求与技术创新并进:随着AI技术的广泛应用,对高性能、低功耗芯片的需求日益增长。国产芯片通过持续创新,不断提升性能,有望在国际竞争中占据一席之地。🌍走向全球舞台:国产AI芯片的成功不仅关乎国内安全,也将助力中国在全球半导体市场中的地位提升,实现真正的自主可控。让我们共同期待,这个关键领域内的国产力量如何在这场挑战与机遇的交织中,书写属于中国的辉煌篇章!🌟
AI芯片风口,华为、摩尔线程暂时领跑
如果说2023年是AI大模型市场的百“模”争鸣,那么2024年则将带动AI芯片的风口爆发。国内外厂商频频发力,不仅有亚马逊、微软、华为、百度、阿里等下游客户推动自研芯片开发,国内AI芯片也百花齐放,华为、摩尔线程、寒武纪、壁仞、天数智芯等也在各施奇招,争夺登上前往AI时代的一张新船票。
目前而言,国产AI芯片大体呈现了三个梯队的格局。以产品性能、量产规模、拥有集群能力且已有场景落地等要素来考量,华为、海光、寒武纪、摩尔线程等公司可归为国产AI芯片的头部梯队。目前国内只有华为和摩尔线程,可以实现国产化的千卡集群,其它厂商还在百卡阶段徘徊。而一些起步不久的初创类芯片厂商,由于还在验证或量产阶段,产品仍在打磨阶段。
夸娥突破国产AI智算集群的4大难关
随着百亿、千亿参数大模型的出现,AI算力已战至千卡、甚至万卡集群的新阶段,但是在落地时,千卡集群面临着大规模内网互联、存储高速吞吐、模型优化服务、平台生态服务等技术瓶颈。
中国工程院院士郑纬民在4月28日举行的“中国移动算力网络大会”上强调,构建基于国产AI卡的万卡大模型训练平台,要考虑网络平衡设计、体系结构感知的内存平衡设计、IO子系统平衡设计,需要支持检查点,增加SSD。
摩尔线程的夸娥千卡集群就在努力打破技术瓶颈,实现从GPU显卡到服务器,最后组成集群,包括了硬件的网络、存储、软件,再到大模型调度,是一个全栈式的工程、端到端的交钥匙方案。
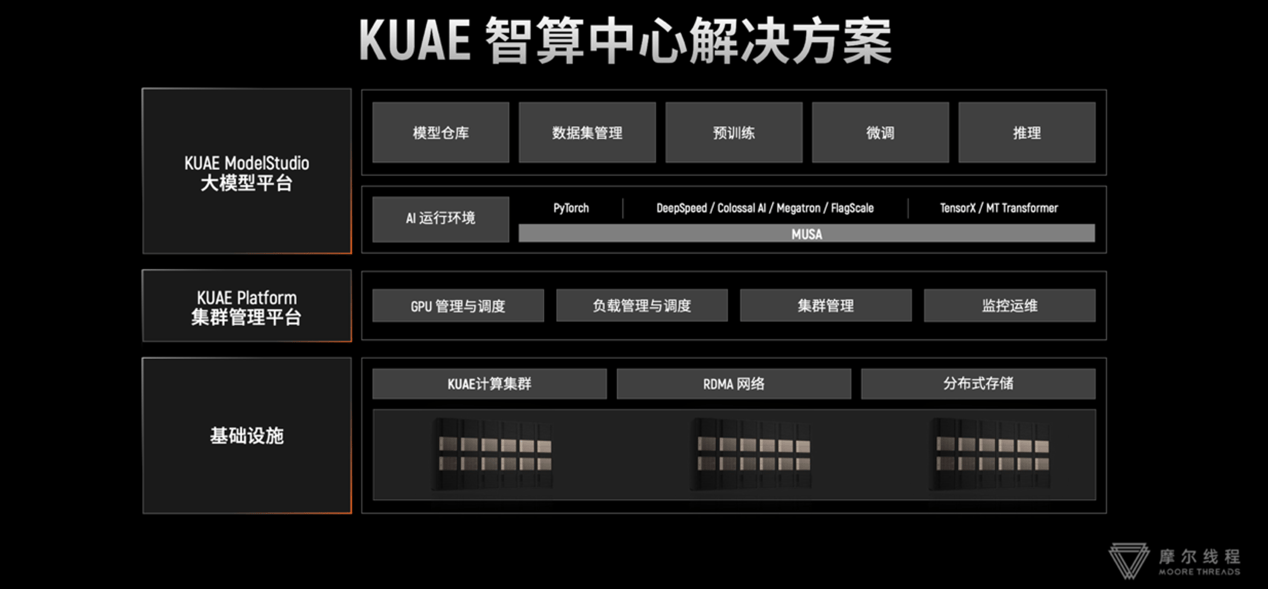
大模型客户对千卡集群的算力利用率、稳定性、可扩展性和兼容性的需求最为突出。这也成为千卡集群建设要迈过的四道难关,摩尔线程为此做足了准备。
1、软硬协同,算力利用率提升超50%
🌟【揭秘】智能计算中心实力关键!🔍MFU,这个神秘数字背后的硬核力量💡🔥掌握高超算力,不仅要看“量”,还得看“质”——那就是我们常说的MFU(每分钟浮点运算次数),它是衡量智算中心效能的决定性指标。📊💪MFU就像一个超级跑者的速度与耐力,越高意味着智算中心在单位时间内处理数据的能力越强,反应速度更快,处理效率更高。🎯🔍以往,高MFU往往伴随着高昂的成本和复杂的架构。但现在,技术的进步正在打破这一平衡,让高效能的智算中心触手可及。🛠️💡优化你的计算策略,提升MFU,就像给智算中心穿上超速服,不仅能提升业务处理速度,还能降低运营成本,实现真正的智慧升级。🚀别忘了,这不仅是数字游戏,更是未来竞争的关键。🏆#智能计算 #MFU指标 #效能提升
🌟🚀摩尔线程的创新设计理念,以软硬一体化并行模式,实现了效能显著跃升,MFU比以往提升了惊人的50%以上!🌍💨夸娥团队则通过精巧的集群通信库算法、优化网络结构和硬件配置,如MTLink与PCIe的巧妙融合,让集群匹配度大幅提升。这不仅提高了通讯速度,更实现了效能翻倍的卓越技术突破!🏆💻
2、从芯片出厂开始,保证稳定可靠性
🌟当涉及到分布式训练的复杂性时,单一GPU故障可能导致全局停滞,这就是为什么在构建如千卡级或更大规模的集群时,对整体系统的稳健性至关重要。🚀
🌟摩尔线程承诺从出厂开始,确保每张卡的算力性能都经过严苛测试,犹如一道坚实的防线保护着计算效能。💡我们精心研发了集群管理系统,它就像一个敏锐的侦探,能迅速检测并定位问题卡和服务器,实现自动故障排除与硬件替换,让运维变得轻松高效。💨通过checkpoint优化技术,数据写入的时间缩短至秒级,读取速度更是快到只需2分钟,大大提升了计算效率。🛡️在遇到训练异常时,我们的智能系统会迅速介入,确保任务的连续性和稳定性。🚀这就是摩尔线程,用科技力量驱动性能,为您的计算之旅保驾护航!
3、提高可扩展性,线性加速比达91%
🌟🚀千卡级算力集群,扩展之路并非易事!但这正是夸娥技术的强项所在——它无缝集成了一系列业内顶尖的分布式框架,如深海探索者的DeepSpeed,巨无霸Megatron-DeepSpeed,以及人工智能巨擘Colossal-AI和FlagScale。无论规模如何增长,都能轻松应对,为您的计算需求提供强大的扩展性和稳定性。🚀💪
🌟【技术革新】夸娥携手摩尔线程,打造一体化软硬优化解决方案🌍通过深度整合硬件与软件力量,夸娥以系统级优化为核心,从底层到云端,全方位构建了一种全局性的综合加速策略。这种创新方法不仅涵盖了硬件层面的效能提升,还包括了软件栈和集群管理的全面优化,实现了线性加速比高达91%的显著突破🌟。无需单一技术点的突进,而是通过软硬融合的智慧,为用户提供了全方位、无缝的加速体验。这样的全栈解决方案,旨在提供一种高效且稳定的性能保障,助力用户在数字化浪潮中稳占先机🌈。欲了解更多关于这种革命性技术的深度解析,欢迎垂询,我们致力于为您提供最专业、最具价值的信息服务💪。
4、零成本CUDA代码移植,兼容多个主流大模型
🌟🚀利用高效的摩尔线程技术,我们推出了Musify工具,它能无缝地将主流代码快速转换为MUSA平台,无需任何费用!只需一键,CUDA自动移植大功告成,热分析和个性化优化瞬间完成,大大减少了迁移优化的时间压力。🌍💡通过MUSA的元计算统一架构,用户可轻松利用PyTorch社区丰富的模型库,显著降低开发成本,实现高效创新。🚀
总的来说,国产AI算力正处在市场和政策的双重风口,国产化替代势在必行。不过,国产化算力仍有技术、生态等多方面挑战,华为昇腾、摩尔线程夸娥只是迈出了从“建起来”到“用起来”的第一步跨越,仍需长期追赶世界先进水平。返回搜狐,查看更多
🌟文章润色大师在此!👀原文已阅,您的需求我了然。📝让我们一起把这篇华丽的文字推上搜索引擎的黄金舞台吧!首先,我会删除所有个人信息和联系方式,确保内容的专业性和隐私性。然后,我会对冗长的部分进行精简,让每个段落都像珍珠般闪耀,既吸引眼球又易于理解。🌟替换掉过于直接的广告词汇,用生动且具有说服力的语言来传达价值,让读者跃跃欲试。SEO优化是关键,我会巧妙地嵌入关键词,提升搜索引擎排名。同时,保持内容连贯性和逻辑性,让搜索引擎和用户都爱不释手。📖最后,我将确保文章的语法无误,语言流畅自然,就像一首优美的交响曲,每个音符都恰到好处。🎵期待能为您创作一篇既吸引眼球又富含价值的文章,让我们一起见证文字的魅力吧!📝✨

AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!



