
你是否曾经觉得某个大模型的回答得“很有道理”,但就是不够吸引人?或者某个大模型的回答“非常漂亮”,却缺乏实质性内容?最近,Chatbot Arena 的一项研究揭示了其背后的秘密:风格与实质的较量。今天,我们就来聊聊这项有趣的研究,看看排版如何影响大模型的排名。
风格 vs 实质
在 Chatbot Arena 的文章中,大模型的表现不仅取决于它们回答的准确性(实质),还取决于它们的表达方式(风格)。比如,一个模型可能回答得非常简洁准确,但只有非常简陋的排版;而另一个模型输出长篇大论、格式精美的 Markdown 文档,美观的布局赢得了用户的青睐。
 而在难度较高的任务中,Claude 3.5 Sonnet 的表现大幅提升,甚至接近 ChatGPT-4o-latest ,这也进一步证明了其实力。
而在难度较高的任务中,Claude 3.5 Sonnet 的表现大幅提升,甚至接近 ChatGPT-4o-latest ,这也进一步证明了其实力。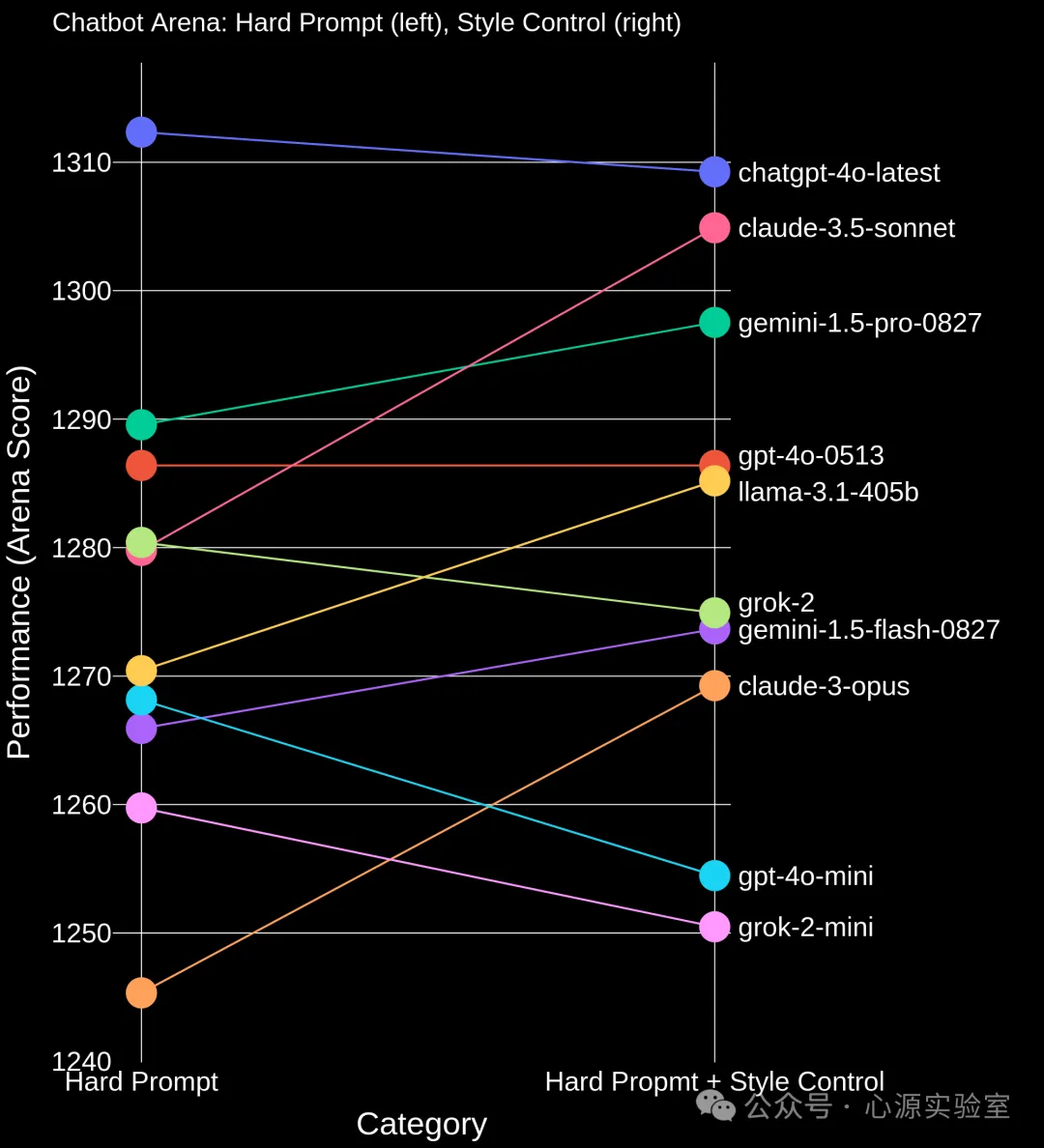
风格控制
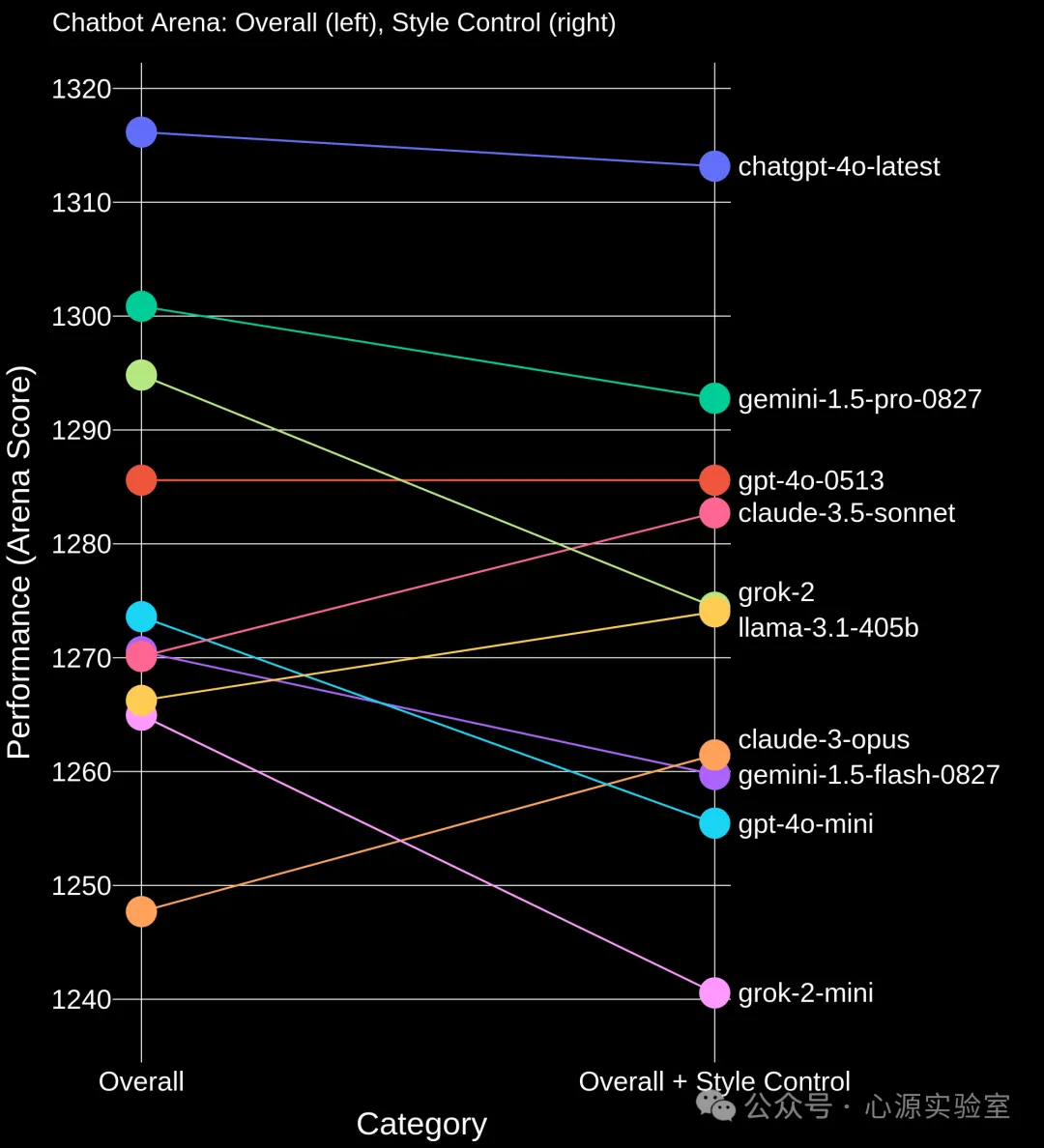
为了分离风格与实质的影响,研究人员使用了 Bradley-Terry 回归模型,将风格特征(如回答长度、Markdown 格式)作为独立变量加入模型中,从而分离出风格对排名的影响。简单来说,这个模型就像是一个“比赛评分系统”,通过比较不同模型的“比赛得分”来评估它们的实力,而风格特征则像是“裁判的偏好”。通过控制这些偏好,我们就能更准确地评估模型的真实实力。风格控制前后的模型排名对比如下: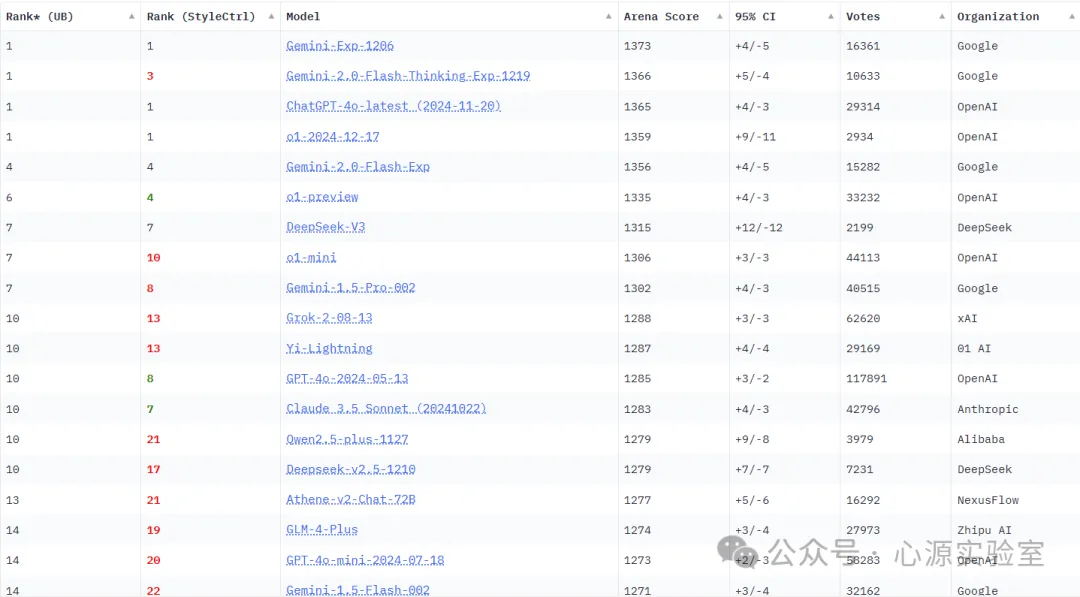 从图中可以看到,在控制风格特征后,大部分模型的排名都发生了变化,这说明风格特征会在较大程度上影响模型的排名。
从图中可以看到,在控制风格特征后,大部分模型的排名都发生了变化,这说明风格特征会在较大程度上影响模型的排名。风格与实质的平衡
这项研究告诉我们,风格与实质在AI模型的表现中都扮演着重要角色。虽然“外表”可能更吸引人,但“内涵”才是长久之计。对于开发者来说,如何在两者之间找到平衡,将是未来 AI 模型优化的关键。这项研究在 AI 大模型的评测之路上迈出了重要的一步,但研究人员也指出了局限性。例如,大模型的回答长度可能与回答质量存在正相关,而这种潜在的混淆因素尚未被完全排除。该团队计划将在未来引入因果推断和随机试验,以进一步优化风格与实质的分离。
您可以在下方页面查看该研究的更多信息↓https://blog.lmarena.ai/blog/2024/style-control/
心源实验室目前也在做国内外大模型的能力评测,您可以点击“阅读原文”进行查看


