
文章主题:基于P-Tuning v2, ChatGLM2-6B, 微调实践, SFT监督微调
原标题:基于 P-Tuning v2 进行 ChatGLM2-6B 微调实践 | 京东云技术团队
微调类型简介
在SFT监督微调方法中,我们主要针对那些在源任务中表现出较高性能的模型进行微调,其学习率相对较小。这类常见的任务包括中文实体识别、语言模型训练以及UIE模型微调等。这种方法的优点在于能够迅速地适应不同的目标任务,然而,它也可能需要较长的时间和大量的数据来进行训练。
在LoRa微调过程中,我们采用高阶矩阵秩分解的方法来降低微调参数的数量,同时保持预训练模型参数不变,并增加了一些新的参数。这种方法的优势在于,它既减少了微调所需的参数数量,降低了调整的成本,又保持了与全模型微调相近的效果。
P-tuning v2微调是一种新方法,它在P-tuning v1的基础上引入了prefix-tuning的思路。在每一层都加入了prefix,并采用了多任务学习的方式,这一改变成功地解决了P-tuning v1中序列标注任务效果不佳和普遍性差的问题。该方法的参数对象是各层的prefix,具有较好的通用性,可以应用于多任务学习。然而,需要注意的是,由于其设计主要针对序列标注任务,因此在自然语言理解任务上的表现可能会略显不足。
Freeze微调是一种针对大型语言模型进行调整的方法,主要通过后几层的神经网络来提取语义特征,而前几层则负责提取文本的表层特征。这种方法的优势在于其高效的参数利用以及 ability to extract specific levels of features.
在总结中,我们可以看到各种微调方法各有所长,能够适应多种场景和任务需求。其中,SFT监督微调方法在迅速应对新的目标任务方面表现出色;LoRA则具有降低参与数量和成本的优势;P-tuning v2在处理多任务学习问题时表现出卓越能力;而Freeze方法则擅长提取特定层次的特征。因此,根据具体应用场景选择合适的微调方法至关重要。
1.下载glm2训练脚本
要获取ChatGLM2-6B聊天机器人项目的源代码,您可以执行以下命令:git clone https://github.com/THUDM/ChatGLM2-6B.git。这将创建一个名为“ChatGLM2-6B”的本地仓库,其中包含项目文件。如果您想在此基础上进行更改或添加新功能,您可以随时进行修改并提交这些更改。
2.然后使用 pip 安装依赖
在Python项目中,安装所需的依赖包是非常重要的一步。本文将介绍如何通过pip安装需求文件并从Douban PyPI仓库获取最新版本的方法。首先,打开终端或命令提示符,然后执行以下命令:“`pip install -r requirements.txt“`这个命令的作用是读取requirements.txt文件中的依赖包列表,并自动安装这些依赖包。如果某些依赖包已经安装过,但版本不匹配,pip会自动更新到最新版本。接下来,添加Douban PyPI仓库的url:“`pip install -i https://pypi.douban.com/simple/“`这个命令的作用是从Douban PyPI仓库下载最新版本的依赖包。通过添加这个url,我们可以确保安装的依赖包版本是最新的。总之,通过以上两个命令,我们可以在Python项目中成功安装所需的所有依赖包,并且确保它们都是最新的。
运行行微调除 ChatGLM2-6B 的依赖之外,还需要安装以下依赖
要安装Rouge中文的pipeline,我们需要借助nltk、jieba和transformers库。为了更方便地获取这些库,我们可以通过PyPI来安装它们。具体操作步骤如下:首先,我们需要安装nltk库,这是一个用于自然语言处理的库。可以通过以下命令来安装:“`shell$ pip install nltk“`接下来,我们要安装jieba分词工具。它可以帮助我们对文本进行精确的分词。通过以下命令可以完成安装:“`shell$ pip install jieba“`最后,我们需要安装transformers库,这个库提供了预训练的深度学习模型。我们可以通过以下命令来安装:“`shell$ pip install transformers torch“`此外,为了让我们可以从PyPI中获取所需的包,我们需要先创建一个Python虚拟环境。具体操作如下:“`shell$ python -m venv myenv“`然后激活虚拟环境:- On Windows:“`shell$ .\myenv\Scripts\activate“`- On macOS/Linux:“`shell$ source myenv/bin/activate“`现在我们已经完成了所需的库的安装,接下来就可以使用pip来安装Rouge中文的pipeline了。通过以下命令可以实现:“`shell$ pip install rouge_chinese nltk jieba transformers[torch] -i https://pypi.douban.com/simple/“`
3.下载样例数据或者自己构建样例
{“content”: “类型#裙*材质#网纱*颜色#粉红色*图案#线条*图案#刺绣*裙腰型#高腰*裙长#连衣裙*裙袖长#短袖*裙领型#圆领”, “summary”: “这款连衣裙,由上到下都透出女性魅力,经典圆领型,开口度恰好,露出修长的脖颈线条,很是优雅气质,短袖设计,这款对身材有很好的修饰作用,穿起来很女神;裙身粉红色花枝重工刺绣,让人一眼难忘!而且在这种网纱面料上做繁复图案的绣花,是很考验工艺的,对机器的要求会更高,更加凸显我们的高品质做工;”}
可以根据以上格式,构建自己的训练样本,我们可以用一些行业生产数据,如会话记录对模型进行训练,
官方示例数据下载:
https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
4.根据自己的环境修改训练脚本中对应的文件地址 PRE_SEQ_LEN=128 #序列的预设长度为128 LR=2e-2 #学习率为0.02 NUM_GPUS=4 #用几颗GPU进行训练 torchrun –standalone –nnodes=1 –nproc_per_node=$NUM_GPUS main.py \ –do_train \ –train_file /export/data/train.json \ #设置训练数据文件的目录 –validation_file /export/data/validation.json \ #设置验证文件的目录 –preprocessing_num_workers 10 \ –prompt_column content \ –response_column summary \ –overwrite_cache \ –model_name_or_path /opt/tritonserver/python_backend/models/chatglm2-6b \ #模型目录 –output_dir /export/models/trained-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \ #训练后的模型目录 –overwrite_output_dir \ –max_source_length 64 \ –max_target_length 128 \ –per_device_train_batch_size 1 \ –per_device_eval_batch_size 1 \ –gradient_accumulation_steps 16 \ –predict_with_generate \ –max_steps 3000 \ –logging_steps 10 \ –save_steps 1000 \ –learning_rate $LR \ –pre_seq_len $PRE_SEQ_LEN \ –quantization_bit 4 5.开始训练吧
sh train.sh

训练中
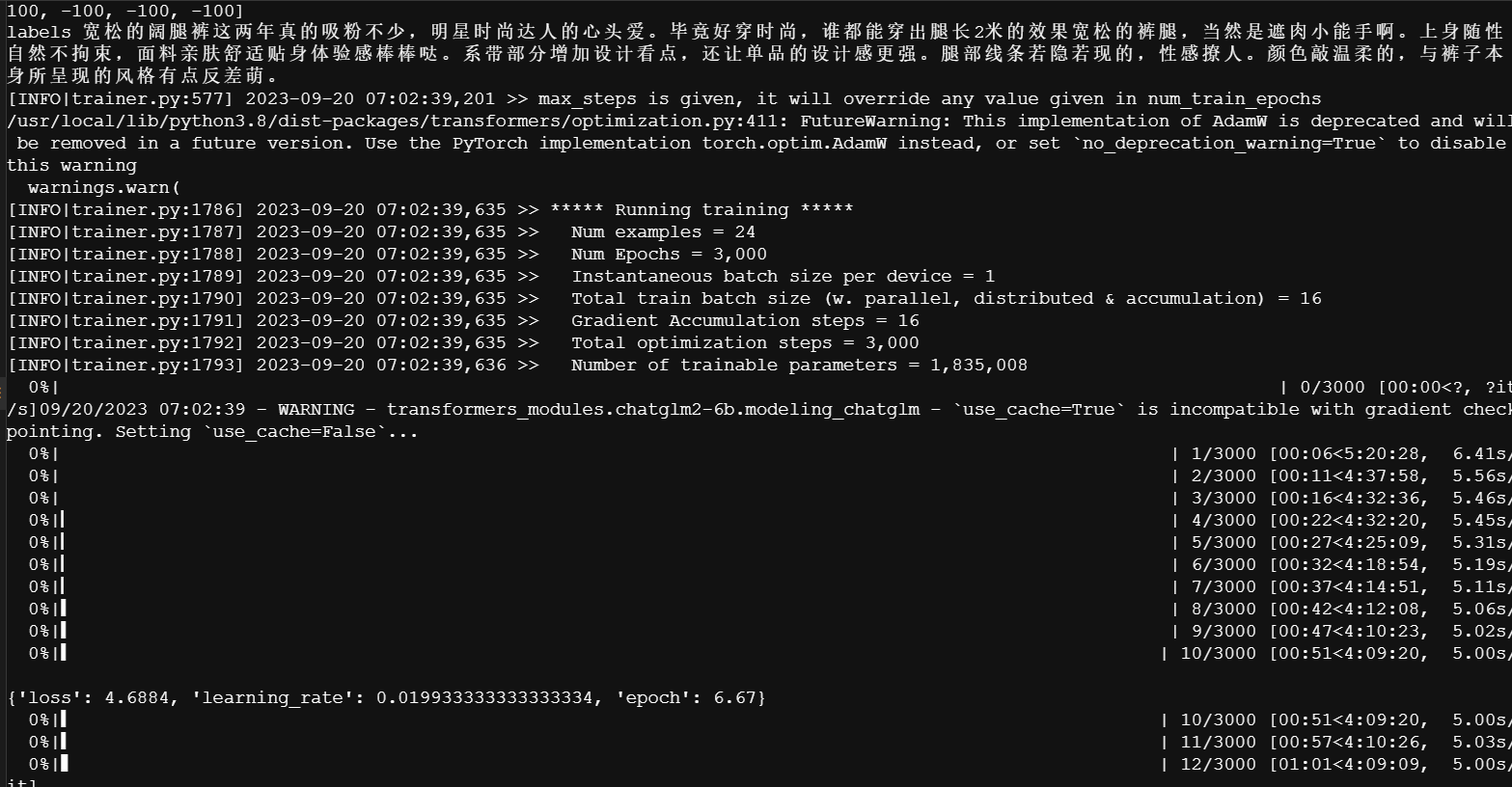
快要训练完成

6.训练完成
Training completed. Do not forget to share your model on huggingface.co/models =)
{train_runtime: 4598.3849, train_samples_per_second: 41.754, train_steps_per_second: 0.652, train_loss: 0.1287700497706731, epoch: 2400.0}
100%|██████████| 3000/3000 [1:16:37
基于P-Tuning v2, ChatGLM2-6B, 微调实践, SFT监督微调

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!


