文章主题:自然语言处理, GitHub, 大语言模型, 文档上传
1 搭建Ollama
1.1 安装ollama
https://github.com/ollama/ollama
1.2 安装llama2
# ollama安装完毕之后,打开后,执行下面的命令 # 命令 ollama run llama2-chinese:13b # 输出 pulling manifest pulling 8359bebea988… 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 7.4 GB pulling 65c6ec5c6ff0… 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 45 B pulling dd36891f03a0… 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 31 B pulling f94f529485e6… 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 382 B verifying sha256 digest writing manifest removing any unused layers success # 至此llama2-chinese:13b模型拉取完毕。2 搭建MaxKB
2.1 安装MaxKB
https://github.com/1Panel-dev/MaxKB
# Docker安装,这个是坑1:好多教程都说执行这个命令,但中国内却获取不到镜像,在此跳过这个坑,请执行我的下面的命令 docker run -d –name=maxkb -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data 1panel/maxkb # docker镜像拉取的坑,使用下面的命令可以搞定 docker run -d –name=maxkb -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data dockerproxy.com/1panel/maxkb # 用户名: admin # 密码: MaxKB@123..
3 设置MaxKB
3.1 重设密码
登陆进去后,可以修改下admin的密码,比如:admin123456
3.2 系统设置
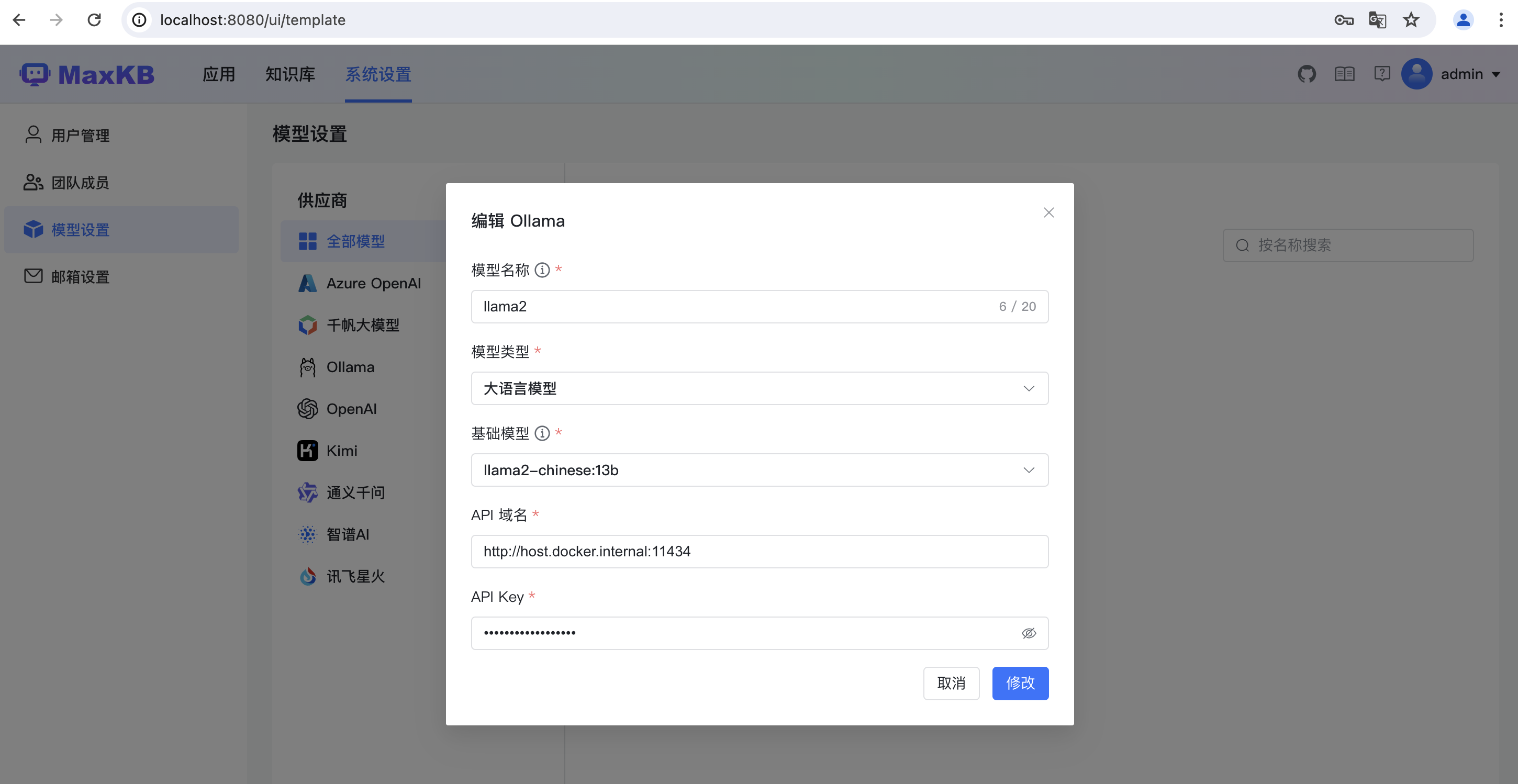
🌟🚀文章写作大师在此!🔥✨选择你的文案神器!💡模型定制无界限,大语言模型为你打造,LLAMA2-CHINESE的13B级力量等你驾驭。🔍🎉隐藏的宝藏?没错!-API域名那一栏,藏着不为人知的秘密(坑二)哦,但别担心,我会帮你巧妙避开,确保流畅体验,就像春风拂过你的指尖。🍃📝立即行动,让创新文字燃烧起来!🔥无论需求多复杂,LLAMA2都能精准应答,带你开启知识探索的新篇章。📚记得,内容为王,优化SEO,我们是行家!🏆你的成功,我来见证。💌#模型定制 #大语言模型 #LLAMA2-13B #API域名秘籍
http://host.docker.internal:11434,API Key随便填。3.3 知识库设置

🌟分享你的智慧库吧!🚀向我们贡献你常遇到的问题与解决方案,无论是简洁的Markdown笔记还是详细的PDF文档,甚至是.docx格式的文件,都能轻松上阵!只需一个点击,把你的知识宝典提交给我们,接下来的回答工作就交给我们来搞定。别忘了,所有内容都将匿名处理,确保安全且利于学习交流。📚💪
3.4 创建应用
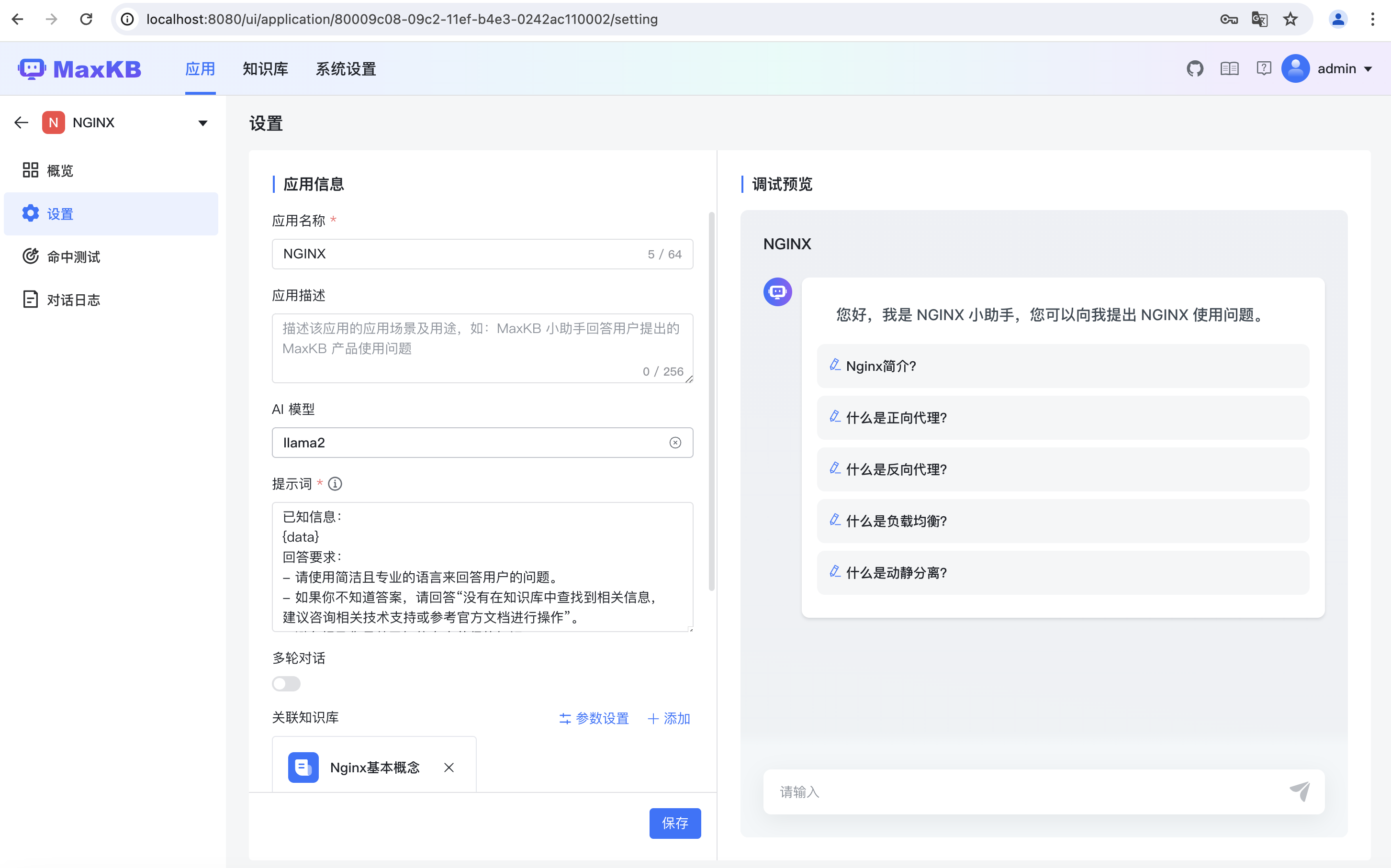
创建应用,然后关联已经上传的文件,可以修改文案信息,可以指定问题,然后保存即可。
4 测试及使用
4.1 测试
测试入口:应用 -> 演示
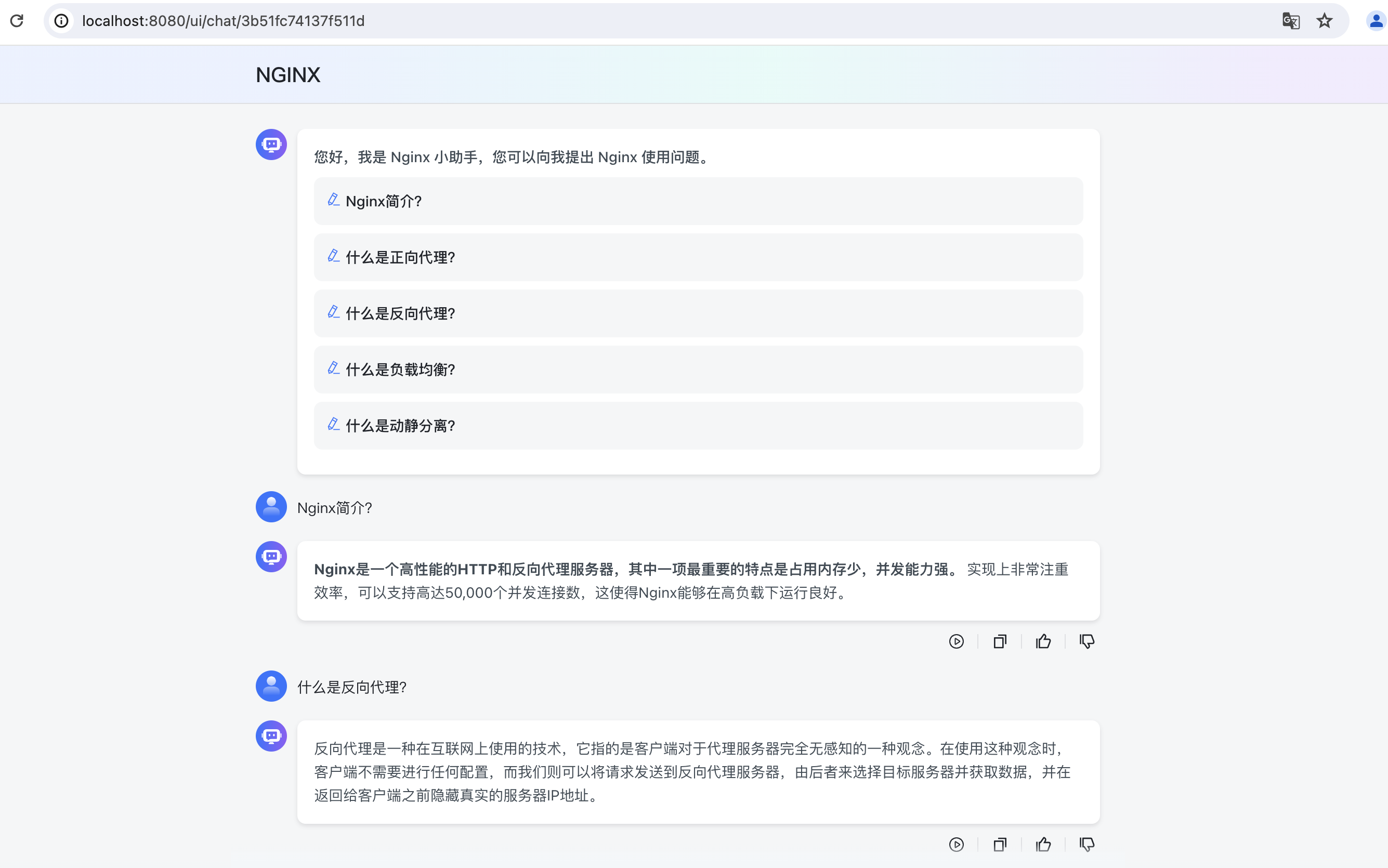
这个上面的答案其实已经和我们上传的文档答案很相似了,比如第一个有50000这个数据,而我们的实际文档中也有这个信息,说明已经在用我们自定义的库了。
4.2 使用
嵌入第三方的两种形式,大家可以随便选。
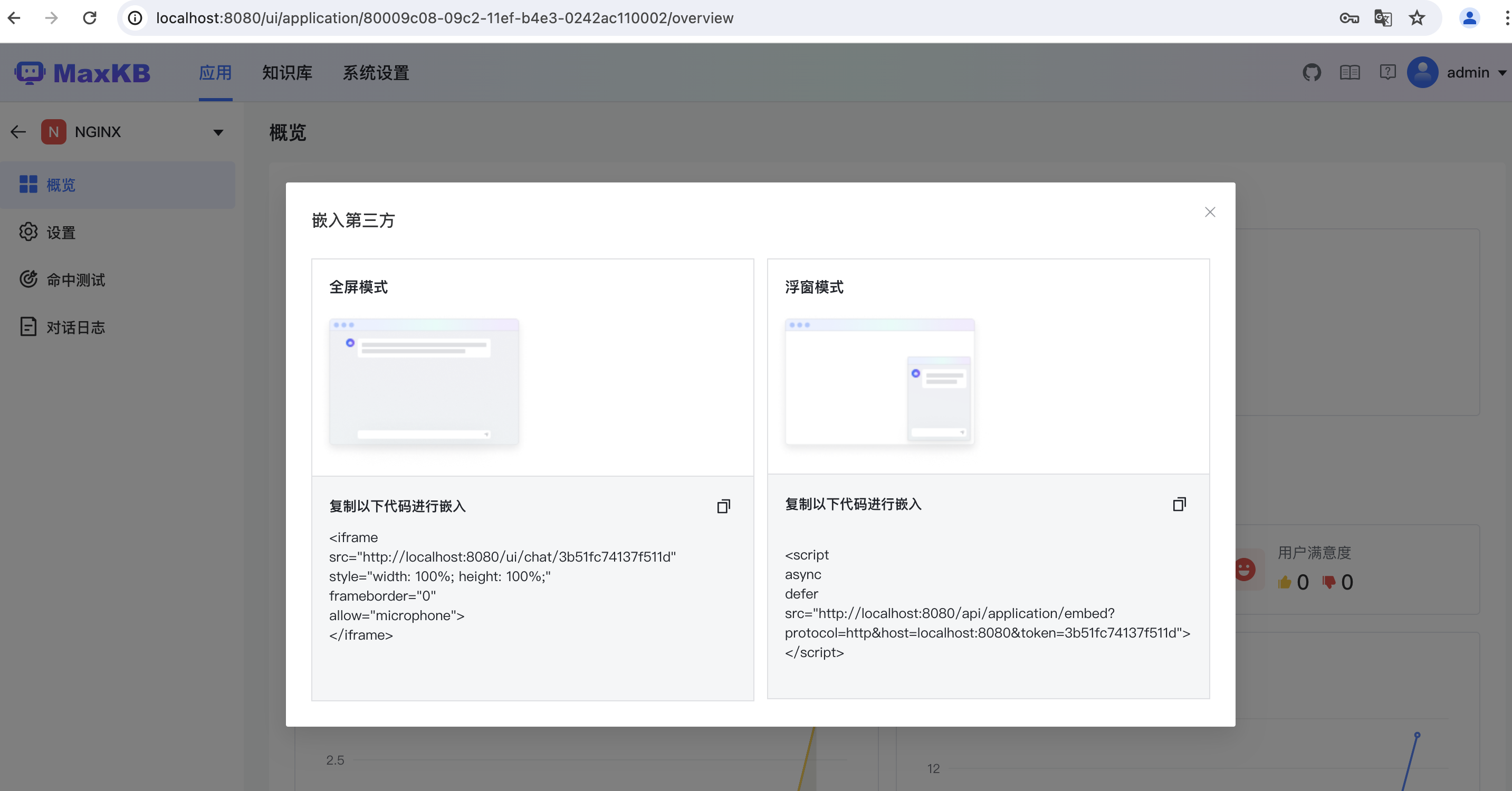
编辑页面引用:
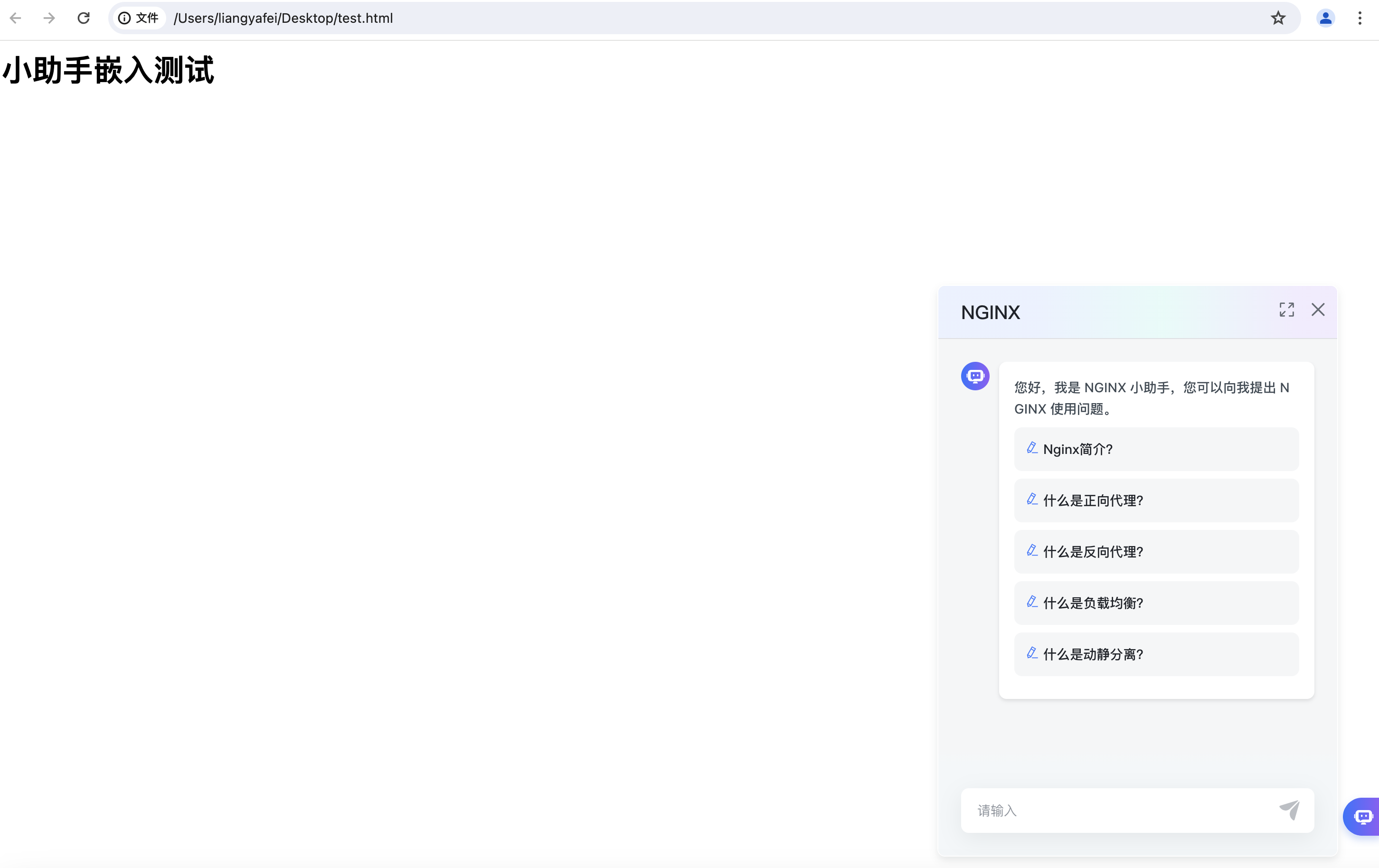
<html> <body> <h1>小助手嵌入测试</h1> </body> <script async defer src=“http://localhost:8080/api/application/embed?protocol=http&host=localhost:8080&token=3b51fc74137f511d”> </script> </html>效果如下图:
总结
虽然网上有很多关于大模型私有化部署的文档,但是真正像我一样去执行的却很少,因为只要执行都会发现坑,我在部署的时候发现了两个坑,也花了点时间处理,在文中也已经标明,希望大家在部署的时候少走些坑,如果在部署过程中遇到了其他问题,欢迎留言相互学习,感谢大家支持。
【温馨提示】
点赞+收藏文章,关注我并私信回复【面试题解析】,即可100%免费领取楼主的所有面试题资料!

AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!