文章主题:
5秒的声音片段就可以克隆一个人的声音,AI神器GPT-SoVITS已经到了如此牛逼的境界。
我在与网友用微信语音聊天的时候,他说通过我发的几个语音就可以克隆我的声音,我当时就警觉起来。声音克隆这个技术在AI中已经不新鲜了,只是考虑到安全的问题,克隆自己的声音,尽量在本地克隆。
GPT-SoVITS这个AI神器是开源的,所以可以在本地部署。对显卡要求也不高(至少4G显存),我这边测试的时候是采用3060,12G显存。二手的3060挺便宜的,建议入手3060以上,因为还有其他的大模型等着我们来体验。

🎉【超值性价比】🔥5000元左右,打造顶级性能!🚀🔍 专业级配置,轻松驾驭!💻想要电脑流畅如飞?不需要昂贵的价格!💰 这款配置,让你以实惠的价格享受顶级体验。💪💻 快速响应,高效工作 🚀无论是日常办公还是项目处理,它都能迅速响应,提升你的工作效率。💼 不再因硬件限制而烦恼,这款配置是你理想的选择。💻🎨 游戏娱乐,畅快无阻 🎮想要在游戏世界里驰骋?它的性能足以让你轻松应对各种挑战。🔥 无论是热门大作还是小型精品,都能流畅运行,带给你极致享受。🎮🔍 精打细算,品质不打折 🛍️5000元左右的价格,却能提供超出想象的性能。🎁 这不仅仅是一台电脑,更是你智慧和效率的最佳伙伴。💪👉 想要了解更多?私信我!👩💻 我们的专业团队随时为你解答疑问,确保你的购买决策无误。💌别犹豫了,让这台超值配置开启你的高效生活吧!🚀SEO优化词汇:#性价比之选 #低价高能 #电脑配置升级 #流畅办公娱乐
设备(也可以租算力服务器,很便宜)搞定之后,就可以开始下载、安装体验了,操作还是比较简单,这里给个简易教程。如果想详细了解参考github项目中的GPT-SoVITS指南,这算是官方文档,非常详细了。
如果你需要帮助检查或安装Python环境,首先建议你自行查阅相关教程或者在线资源,确保系统已经兼容最新版本。如果在操作过程中遇到困难,可以尝试使用Python的官方网站或者其他权威社区寻求解答,他们会提供详细的指导和帮助。关于具体的安装步骤,由于这里是非广告内容,我无法直接给出链接或联系方式,但是一般来说,大部分操作系统都有其官方的Python安装指南,按照指示进行即可。如果在安装过程中遇到问题,记得附上错误信息以便更好地协助你。记得,学习编程最重要的是实践和探索,加油!💪
1、下载安装。从指南里的百度网盘下载整合包,公众号回复关键词声音克隆。网盘的版本是1月份的版本,在github上下载最新的源码,手动覆盖,再执行以下更新:
打开cmd,进入GPT-Sovits文件夹,然后输入runtime\python -m pip install -r requirements.txt,回车看结果就行。
2、启动。默认目录是有版本号(如GPT-Sovits-beta0217),把后面的版本号去掉,然后进入目录GPT-Sovits。双击go-webui.bat,启动之后没报错就可以了。然后打开浏览器,输入http://localhost:9874,就可以看到操作界面了。

3、数据集处理。
🌟音频录制秘籍🌟想要提升文章质量?音频是个不容忽视的秘密武器!🚀只需几个简单的步骤,你就能轻松创作出专业级的声音作品。首先,找一个静谧的小角落,让思绪如流水般顺畅。找个安静的房间,关闭所有电子设备干扰,用纯净的声音记录你的想法。📱无论是手机录音还是电脑操作,确保音频清晰无杂音。接下来,选择合适的格式。mp3或wav?两者皆可,但wav能保留更多细节,适合需要高度保真度的内容。📝记得,内容为王!你的声音应该与文字一样,充满力量和说服力。不要忘了,有时候,听到比读到更能触动人心。💖最后,编辑和完善。录音后,花点时间剪辑不必要的部分,让音频更加精炼。用专业的音频处理软件,提升音质,让你的声音更有吸引力。👩💻分享你的作品,让听众在听觉的盛宴中感受你的智慧和独特见解。不要忘了,版权保护是关键哦!💪现在,就开始你的声音创作之旅吧!🚀#音频写作 #内容创作 #SEO优化
(2)用自带的UVR5处理音频。点击“是否开启UVR5-WebUI”,等几秒会弹出自带的UVR5界面,然后上传音频(可以输入目录)、选择模型、导出格式选择wav,然后点击转换,右边提示success就可以了。
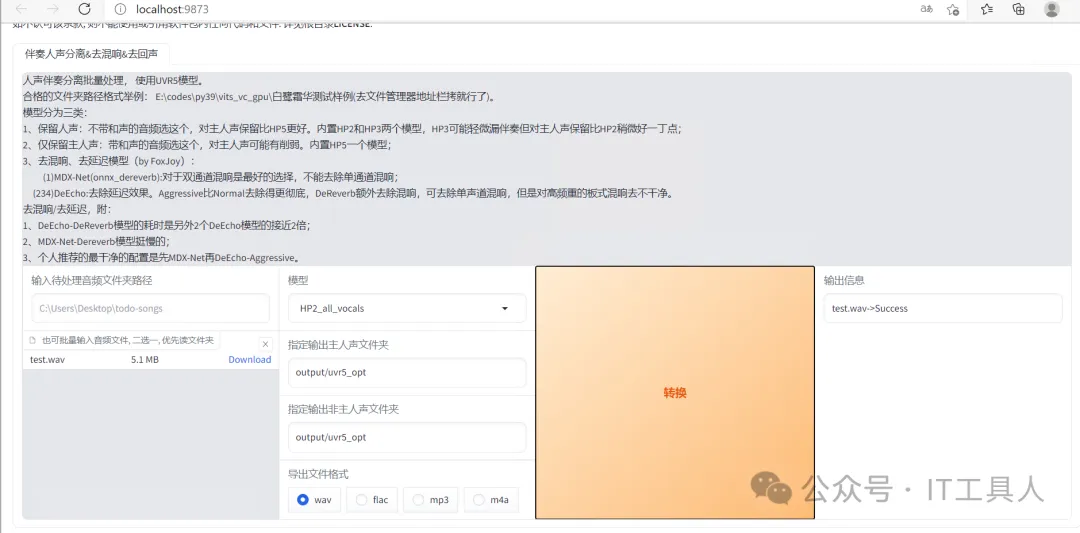
执行之后,在output\uvr5_opt可以看到结果
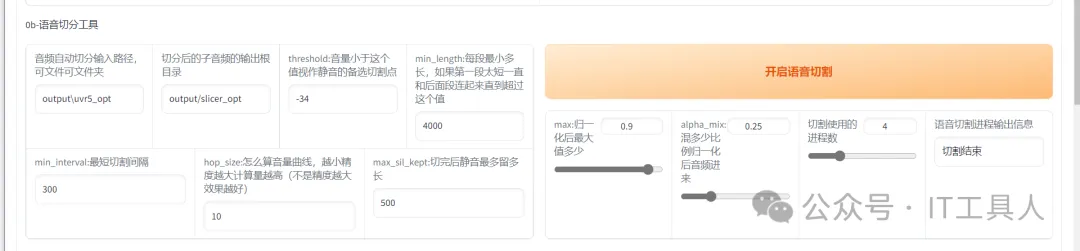
(3)语音切分工具。在输入路径输入output\uvr5_opt或具体的文件夹,然后点击开启语音切割,生成结果将在output/slicer_opt中展示。
(4)语音降噪。如果声音很干净,这一步完全可以跳过去,不要执行。把上一步的输出文件夹作为这一步的输入文件夹output\slicer_opt,然后点击开启语音降噪。这时候后台会有进度条,等到web界面提示任务完成时,可以看下后台是否有报错。输出结果是在output\denoise_opt。
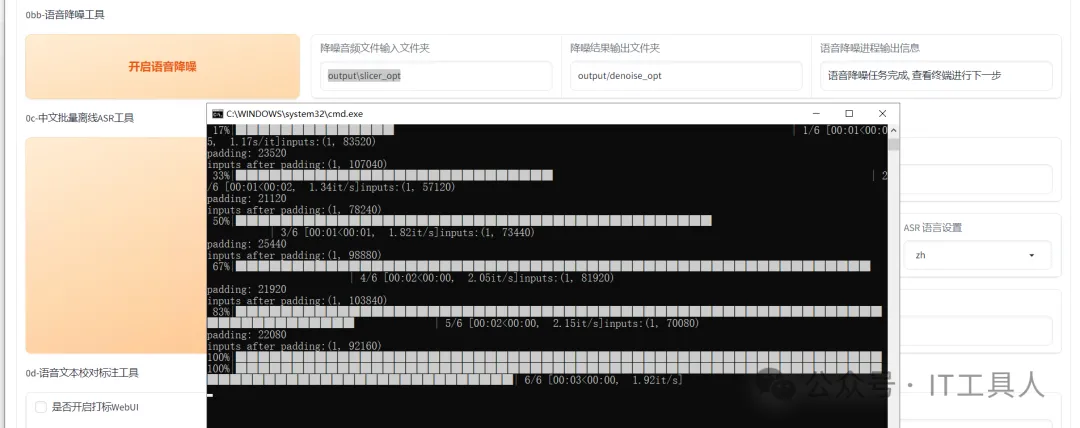
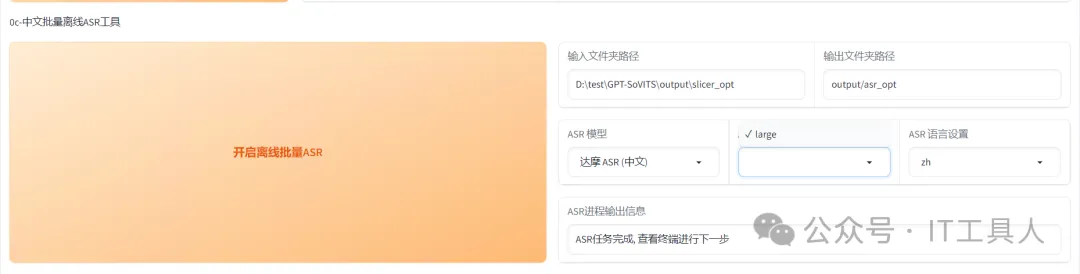
(5)开启离线批量ASR。输入音频片段所在文件夹,如果没有降噪,是output\slicer_opt目录,如果有降噪是output\denoise_opt。因为这次是说中文的声音克隆,所以ASR模型选择达摩ASR,其他参数也采用默认的,最后点击开启离线批量ASR,等了3分钟左右,在output\asr_opt目录生成了slicer_opt.list文件。
🎉🚀文章润色大放送🔍✨只需轻轻一点,你的创作瞬间焕发光彩!💡路径指引来啦——找到专属的list文件,一键开启打标操作,就像按下魔法按钮,3秒后,专业的校对页面会迅速跃然眼前。📝这是个微调环节,内容优质无需过多忧虑,直接跳过,让专业为你把关。もし、何か質問?别担心,我们随时待命!💬记得,每一次的打磨都是为了下一次的飞跃,让我们一起提升文章的魅力吧!✨SEO优化已融入每个词眼,让你的作品在搜索引擎中脱颖而出。🏆快行动起来,创作路上,我们与你并肩同行!🏃♂️💨

4、训练。只要设置模型名称、文件标注文件(list后缀文件)、训练集音频文件目录(输出结果),然后点击一键三连。如果路径跟我一样的,可以照搬。

🌟若对合成音频不尽满意,别急!可轻松微调至完美状态。我们的专业工具提供无限可能,只需轻轻一点,就能调整到最符合心意的音色。让你的声音独一无二,展现个性魅力。记得,每一次细微改动都是艺术的升华哦!😊
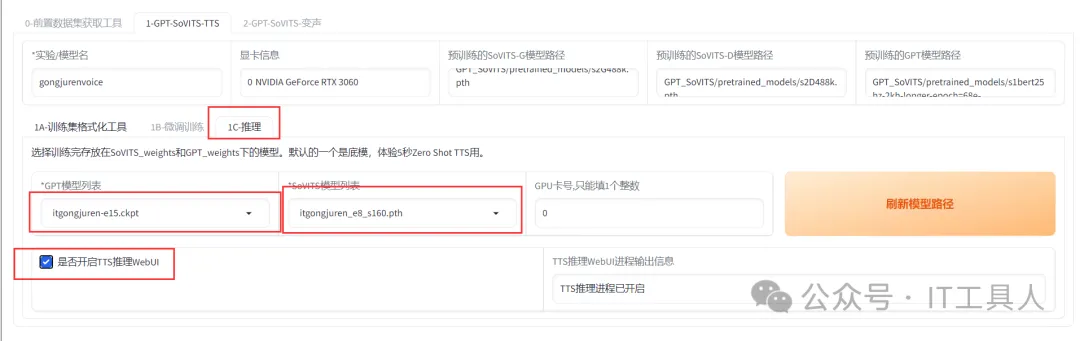
5、推理。文本生成语音的步骤了,也是激动人心的时刻。选择1C-推理,选择GPT模型列表和SoVITS模型列表,这里是选择训练时生成的模型,有几个模型,e和s可以选择稍微大一点试试,作者是说不是越大越好。
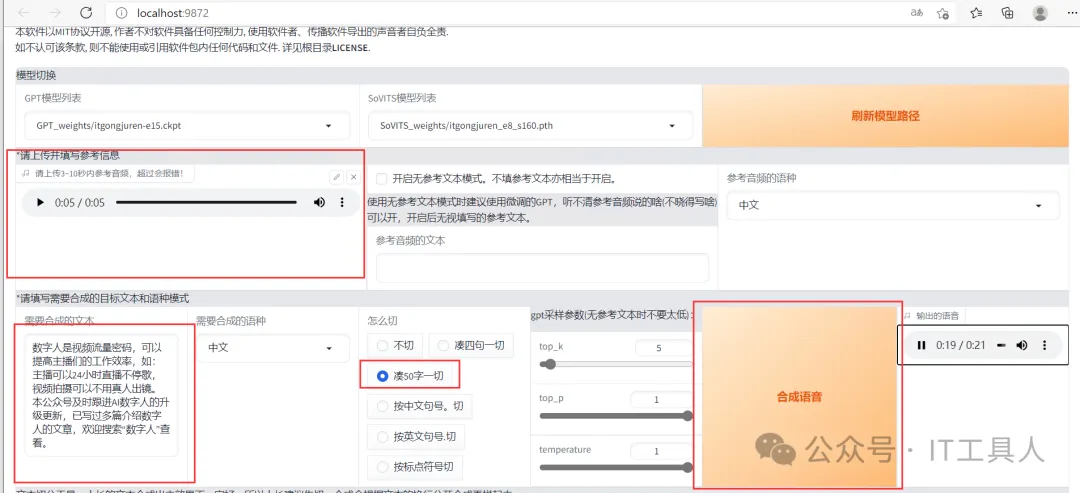
勾选开启TTS推理WebUI,3秒内弹出语音合成页面。上传一段3-10秒的音频,这里是选择前面分割的音频。输入待合成的文本,选择凑50字一切,点击合成语音,大概1分钟左右就生成了。结果还是可以,与原音相似度比较高,可以直接用。
🌟 当提到声音复制的潜在风险,确实会让人不自觉地感到一阵寒意。🚀 难道未来的语音交流真的要受限于此吗?🤔 为此,我们的公众号决定暂时不分享未经原创处理的声音内容,以确保每位读者都能享有最纯粹、无侵犯的互动体验。👩💻💖
最后再介绍一下这个牛逼的语音克隆工具,它是参考训练集的音频情感、音色、语速控制合成音频的情感、音色、语速。30秒的原音频训练就可以合成逼真的音频。而且可以跨语种生成,即参考音频(训练集)和推理文本的语种为不同语种,如支持英文、日语等。
看了这篇文章并且实践成功之后,就可以看GPT-SoVITS指南,那是一个权威且完整的指南,感谢大神无私的奉献。
GPT-SoVITS指南:
https://www.yuque.com/baicaigongchang1145haoyuangong/ib3g1e/xyyqrfwiu3e2bgyk。
github地址:
https://github.com/RVC-Boss/GPT-SoVITS。
🌟无论你对AI有多少疑惑,这里都能找到答案!💡我们的专业群专注于技术交流,欢迎加入,一起探索未来科技的无限可能!👩💻只需扫描下方二维码,立即进入AI技术大家庭,与志同道合者共享知识盛宴!👇别犹豫了,让我们在智慧的海洋中航行吧!🌊

AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!