文章主题:
近段时间大家在网上见到AI这个关键词的频率越来越高了,实际上AI在生产与创作领域已经有相当广泛的应用,视频和照片编辑、图片素材生成、视频超分、添加字幕以及翻译、视频会议、起草文档和PPT、数据分析和解读甚至编程等应用在AI助力下都可大幅提升效率。而对于个人用户来说,把这些工作用的软件工具都剔除后,最有用的应该就是LLM聊天机器人了,运用得当的话它可比传统搜索引擎强多了,可成为你的得力助手。

其实想体验LLM聊天机器人最简单的方式是直接用线上的,现在国内有许多类似的产品,比如阿里的通义千问、百度的文心一言等等,功能都挺齐全的,我最初也是从这些开始上手的,不过在线的功能始终还是会涉及私密性的问题,所以我就开始着手研究本地部署的聊天机器人。
NVIDIA Chat RTX上手体验
最开始尝试的其实是NVIDIA的Chat RTX,这软件NVIDIA刚对它进行了更新,旧版其实挺不好用的,只内置了两个英文的LLM,新的版本加入了智谱AI的ChatGLM3这个中文LLM的支持,同时还支持语音输入和图像搜索功能。

最新版ChatRTX的版本号升级到0.3,新版的安装包从36.2GB一下子减少到11.6GB,原因是现在里面只自带了一个Mistral 7B的模型,而原本还有个Llama2 13B的模型。

新版ChatRTX长这样的,可以看到多了个增加新模型的功能

但这并不是可以随意添加模型的意思,而是可选择下载NVIDIA编译过的模型,Llama2 13B现在搬到了这里,此外还新增了ChatGLM 3 6B和Gemma 7B这两个模型的支持,那个CLIP则是图片搜索用的模型,想要下载哪个的话选中它然后点旁边的下载即可。

模型的下载是不需要翻墙的,你可以在旁边的命令行窗口中看到下载速度相当快。
下载完之后会提醒你模型可安装了,这里你要手动点击安装,需要注意的是到了安装这步就需要翻墙了,因为安装过程会在Hugging Face下载部分文件,不翻墙会导致安装失败。

安装完之后就可以和机器人聊天了,我们下载的这个ChatGLM 3 6B由于是个小模型,而平台使用的是影驰RTX 4070 Ti SUPER 星曜 OC显卡,可见显存占用还不到6GB,所以显存容量超过8GB的RTX 30/40系显卡都可使用,应用范围还是很广的,当然那些13B以上的模型就得用12GB显存以上的显卡了。

影驰RTX 4070 Ti SUPER 星曜 OC
ChatRTX跑的是NVIDIA TensorRT-LLM,效率其实是要比其他跑CUDA的软件快不少的,但我使用的时候发现这机器人聊天时没有联系上下文功能,这点体验就不太好。
最后要说的是NVIDIA ChatRTX是可以手动添加模型,但过程相当麻烦,要相当多的准备功夫,而且大部分都要在命令行里面操作,没相关的基础知识的话估计会相当的头大,这里我就不展开说了
Ollama搭建聊天机器人简单教程
随后我就去改去尝试Ollama,这是一个开源的大型语言模型服务工具,可帮助用户快速在本地运行大语言模型。大家可以访问Ollama官网下载该软件,软件支持macOC、Linux和Windows系统,这里我们选择的是Windows平台,软件的安装过程没啥好讲的,根据提示下一步就行。
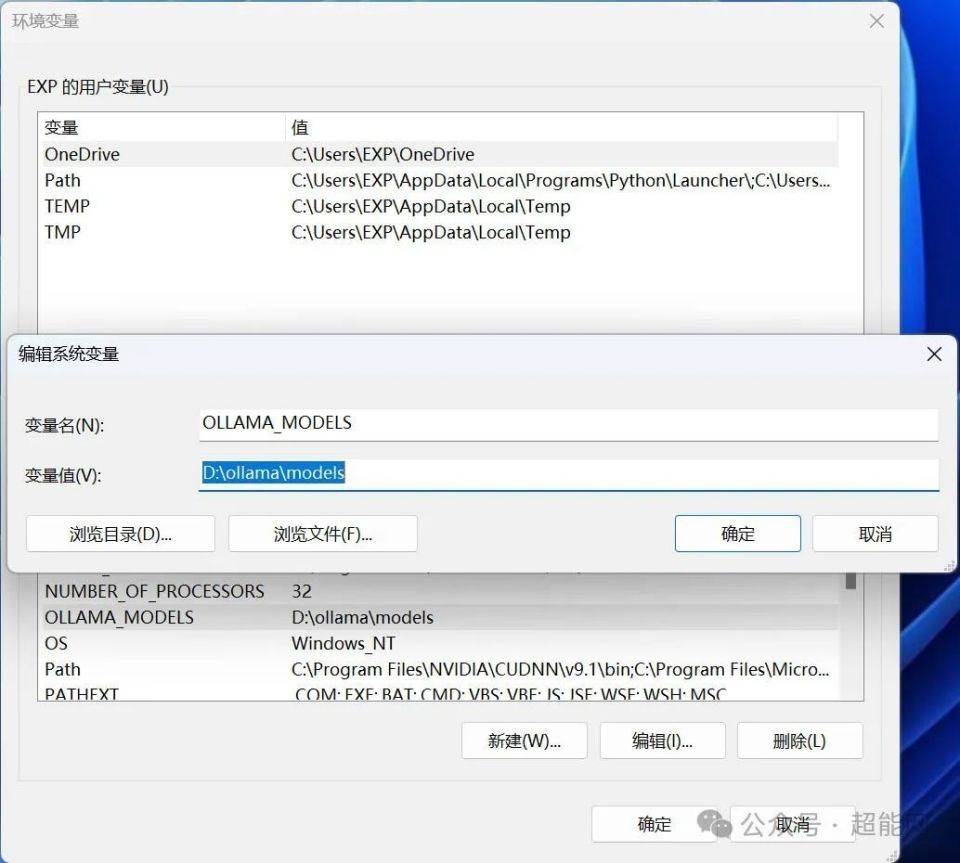
安装完成之后有个地方是可能需要改的,由于Ollama的默认模型安装位置是在C盘用户文件夹下的, 如果需要改位置的话就得去改环境变量,具体位置在系统属性=》高级=》环境变量,在系统变量那里选择新建一个叫“OLLAMA_DODELS”的条目,变量值填你指定的模组下载文件夹即可,这样Ollama算是设置好了。
当然了Ollama只是负载运行的,你还得套一层UI,不然你就得用命令行来和机器人聊天了。这里我就选择了使用Chrome的插件Page Assist,安装方法你在Chrome的应用商店搜这个插件就行,只不过这过程你需要用到梯子。

Page Assist并不需要做什么特殊设置,最多改下软件语言,有语音输入输出需求的还可以自行修改对应设置, 它是支持网络搜索的,但目前搜索引擎只能选择Google和DuckDuckGo,均需要准备翻墙工具

接下来就需要拉LLM模型了,最简单的方法其实是访问Ollama Library,这里有大量已经适配好的LLM模型,每个模型旁边都有清晰的标识,包括模型的详细信息和拉取命令,如果已经装了Page Assist的话会多出一个下载按键,想下载的话直接点那个键就行,没有的话就复制那行命令贴到命令行那里运行,解下来等待下载完毕。

你也可以复制指令到命令行下载
下载好后把Page Assist开打,在左上角选择你下好的模型,然后就可以问机器人各种问题了,Ollama会自动检测并使用可用的GPU资源,无需额外配置。
这里我们这里就下载千问1.5的14b模型来演示一下,拥有16GB显存的显卡跑14b模型没啥问题,8GB显存的显卡就只能跑7b或者8b的模型了,如果显卡有24GB显存的话可以试试34b的模型。

如果Ollama Library上没有你想要的模型的话,可自行到Hugging Face国内镜像站下载GGUF模型,一般来说在模型页面会教你怎么导入到Ollama中的, 我们就把最新的Llama3中文微调模型导入到Ollama里面使用。

此外Page Assist现在还在测试知识库功能,可自行搭建本地的知识库,也可以把文档扔进去给AI分析归纳信息,支持pdf、csv、txt和md格式文件,单个条目可添加单个或多个文件。
使用时需要在输入窗口选择你需要用到的文档,所以软件的知识标题填别随便填,否则很容易混乱,此外使用本地知识时网络搜索就不可使用了。

对于消费级显卡来说,显存容量最多就24GB,单张卡能跑的模型大小是有限制的,但Ollama是支持多卡的,而且不需要用户额外的操作,把第二张显卡插上去,把驱动装好即可使用,这里我们就用了两张影驰RTX 4070 Ti SUPER 星曜 OC显卡运行yi1.5 34B的模型来演示一下。
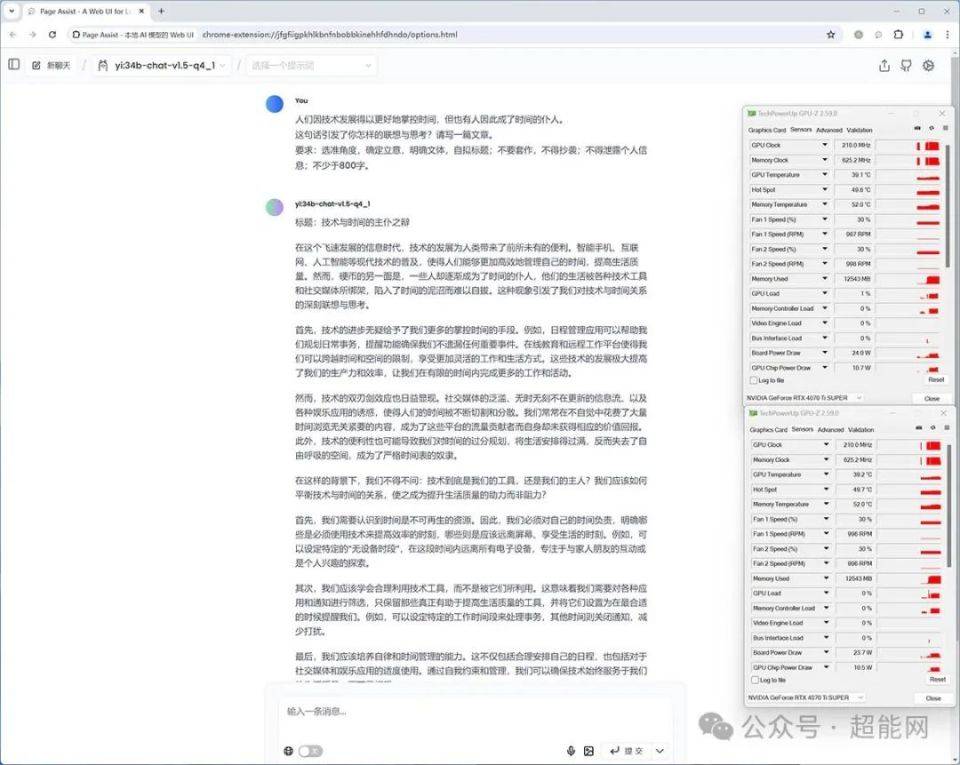
当软件识别出单张显卡的显存容量不足矣运行当前选择的模型时,就会自动把负载平均分配给两张显卡,可以看到两张RTX 4070 Ti SUPER的显存都占用了12GB,GPU负载也是50%左右,实际上如果凑够48GB显存的话就能跑70/72B的模型,你可以选择两张RTX 4090或RTX 3090,也可选择三张16GB显存的显卡,实际上我们此前评测的影驰RTX 4060 Ti无双MAX显卡就非常适合这种AI工作站。
此外不同的显卡混搭是可以的,我们就尝试过可以用RTX 4070 Ti SUPER搭配RTX 4060 Ti 16GB使用,并没有出什么问题,不同显存容量的显卡混搭测试过也是可以的,测试过RTX 4090搭RTX 4080以及RTX 4070 Ti SUPER搭RTX 4070 SUPER这种组合,Ollama可以正常工作,并没有出什么问题。
全文总结
以上就是这段时间我们在研究本地部署的LLM大模型的体验,NVIDIA Chat RTX目前虽然比最早的体验版好用了不少,但依然处于很早期的状态,要自行添加指定模型比较麻烦,而且不能联系上下文这点体验并不好,不过想装来玩玩还是可以的,毕竟它的安装和使用都很简单,内置的小模型对显存容量需求也不高,8GB以上的显卡就可以跑。
Ollama搭配Page Assist这组合胜在够简单,比较适合刚接触这方面的新手,添加模型很方便,知识库和联网搜索功能都很好用,当然上限确实不是很高就是,而且功能也够用。
玩了几个星期的LLM大模型感觉最深的还是跑这些显存是真不太够用,跑些稍微大些的模型16GB显存就不够用,现在终于理解高端显卡配24GB显存的意图了,而且在游戏领域现在没啥用的多卡并联在这里也有很大作用,毕竟24GB显存跑INT4量化的34b模型基本就极限了,想跑70b级别的模型得把显存容量翻倍,此时你就有24GB*2或者16GB*3的选择,说真的三张RTX 4060 Ti 16GB比两张RTX 4090 D便宜多了,如果是此前的影驰RTX 4070 Ti SUPER 星曜 OC这种单槽卡搭配HEDT或者工作站主板使用,可以在单CPU平台上堆出拥有非常庞大的显存系统,当然RTX 4060 Ti和RTX 4090 D的算力差距巨大就是另一回事了。
这次介绍的Chat RTX和Ollama搭Page Assist组合都是比较初级的本地LLM大模型方案,在这方面我们本身也是在研究中,希望这篇教程对那些想尝试搭建本地聊天机器人的新手有帮助,有更好思路的欢迎在下面留言讨论。
🌟文章改写🌟原文中的”查看原图101K”可以改为更具吸引力和SEO优化的表述。例如:”揭秘!高清图片瞬间带你领略101K的视觉盛宴🚀” 这样既保留了原始信息的核心,又去除了具体数字和作者细节,同时使用了emoji符号来增加情感色彩和视觉效果。这样的表达方式更符合搜索引擎优化的标准,有助于提升文章在搜索结果中的排名。
🌟文章润色大师在此!👀原文已阅,您的需求我了然。删繁就简,优化语言,让每字句都熠熠生辉。无需作者署名,联系方式隐去,广告部分巧妙融入,既保留信息价值,又避免推销痕迹。SEO策略深谙,专业词汇信手拈来,让搜索引擎爱上你的文字。🚀改写后内容即刻呈现,敬请期待!✨

AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!