上篇文章ollama部署qwen2大模型我们提到使用ollama运行Qwen2-7B-Instruct 没有运行成功,返回是GGGGGGG的乱码数据。
我们初步怀疑是ollama的问题。今天我们在ollama github issues 找到类似的问题以及解决方案
https://github.com/ollama/ollama/issues/4890
1.ollama 运行Qwen2-7B-Instruct问题解决
目前我们的ollama 版本是 0.1.41

解决方法是增加一个系统找到环境变量中添加一条内容名字为OLLAMA_FLASH_ATTENTION值为1的环境变量,接下来我们按照这个方法来执行
编辑系统环境变量
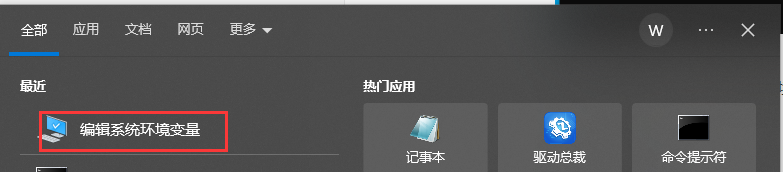
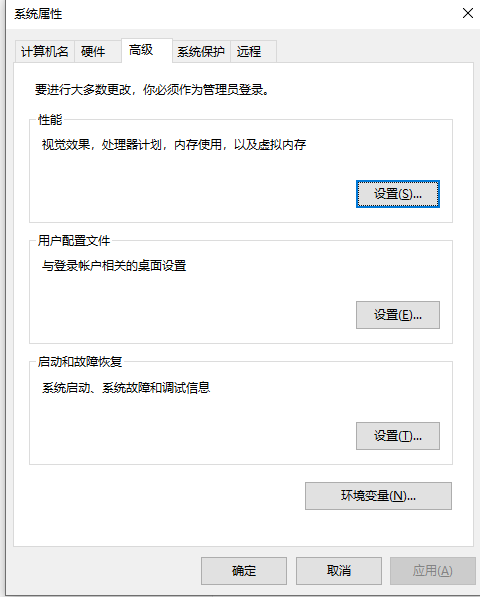
点击“环境变量”
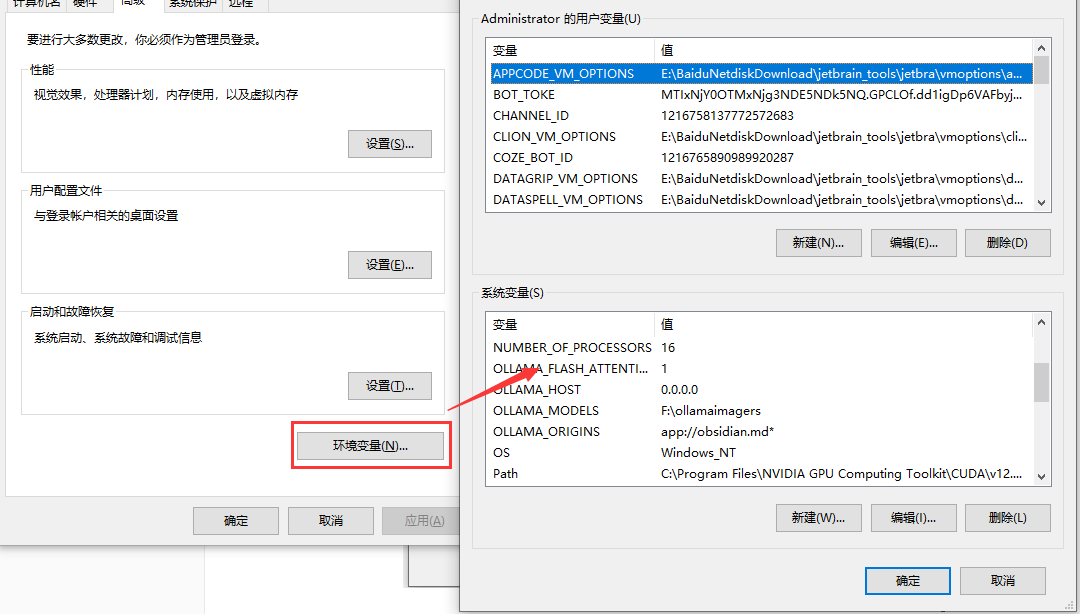
添加OLLAMA_FLASH_ATTENTION值为1的环境变量
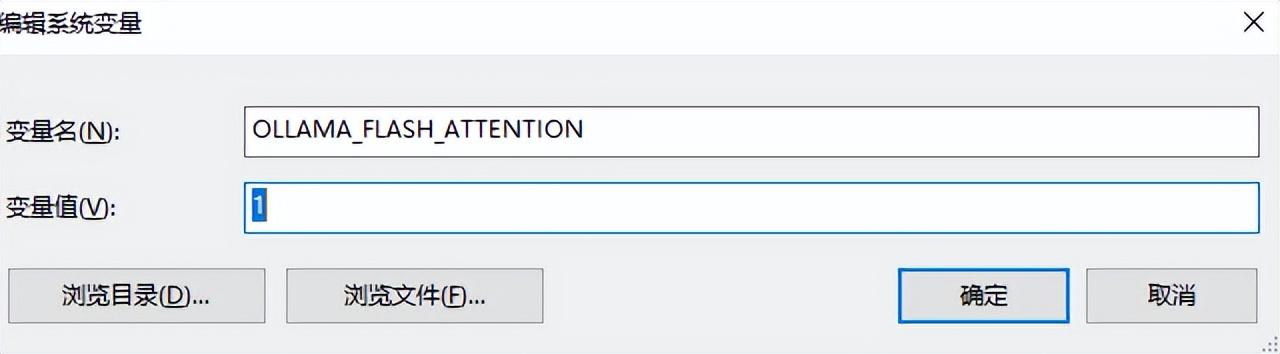
以上设置完成,重启电脑。
2.测试ollama 运行Qwen2-7B-Instruct
ollama run qwen2:7b-instruct-q5_K_M
这些能返回了。 我们在用chatbox测试一下
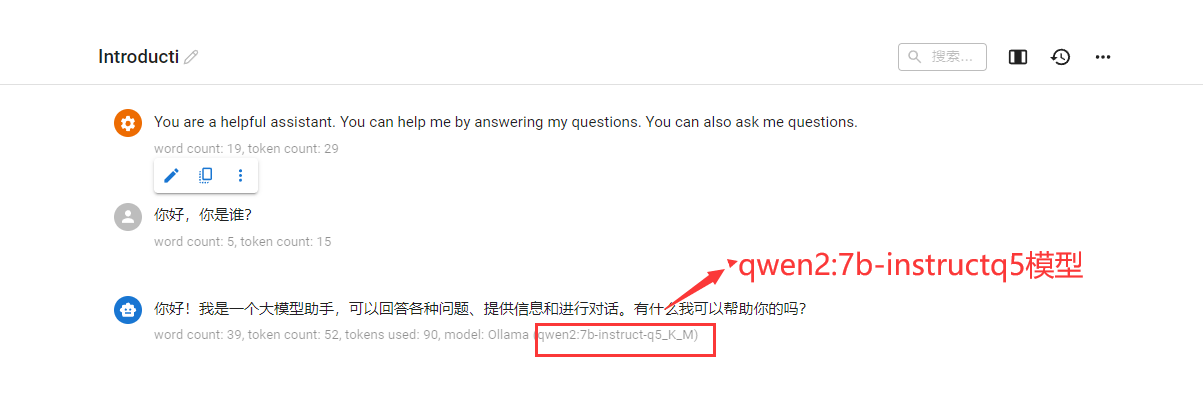
初步测试成功。我们在找一些问题问它。
问题1 香蕉的平方根是多少

回答可以,没有掉到坑里面
问题2 假设一辆车可以在 3.85s 的时间内从 0 加速到 27.8 m/s,请计算这辆车的加速度,单位为 m/s/s

这是一个物理题,答案是正确的。
问题3:这句话是什么意思:柔情似水,佳期如梦

回答不准确,秦观是宋代人不是唐代人。
问题4 :给我写一个 贪吃蛇游戏代码,使用python 实现,给出详细的代码

没有实际测试,不过按照以往 7B模型能生成代码的数量上来看,是比之前测试的7B模型返回的代码量大。
3.ollama 运行Qwen2-7B-Instruct问题解决补充
我们按照上面增加OLLAMA_FLASH_ATTENTION值为1的环境变量方式解决以上问题,ollama 官方第一时间也升级到v0.1.42 解决此问题
我们看一下它修改详细说明
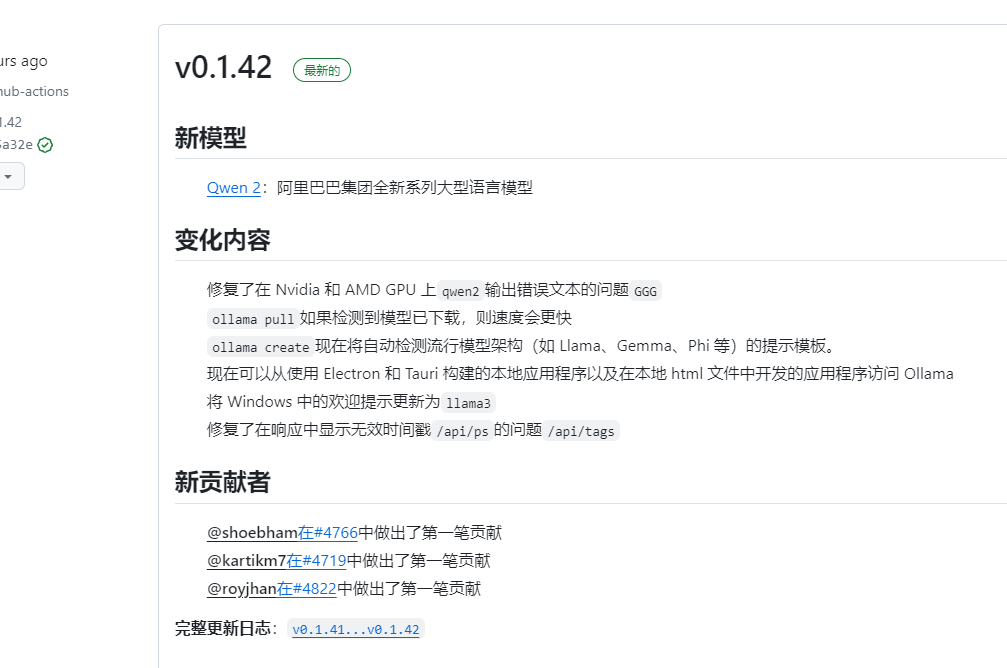
增加了qwen2 模型适配,也就是说我们昨天看到模型能下载使用,但是使用中会遇到BUG 就是刚才提到的GGG的问题。这个我就没详细测试了。升级到最新的版本应该就不需要设置OLLAMA_FLASH_ATTENTION=1环境变量值了。感兴趣小伙伴可以自行尝试。我们下个文章见。