最近,我们探讨了如何利用Ollama平台在本地部署LLM,但是它所支持的模型种类有限。对于那些渴望接触更广泛的模型的用户来说,Hugging Face提供了一个理想的解决方案。
Hugging Face不仅是一个模型和数据集的托管共享社区,更像是机器学习领域的GitHub,专注于LLM等资源的分享。通过使用LM Studio这样的工具,用户可以轻松地在本地下载、托管并运用Hugging Face上的模型,极大地简化了整个过程。
本文将指导你如何使用LM Studio在本地运行Meta Llama 3——迄今为止最强大的开源LLM之一,并展示如何通过Semantic Kernel与之交互。
运行 LLM 服务
首先,你需要从LM Studio官网(https://lmstudio.ai/)下载并安装该软件。启动后,你可以在首页搜索和下载 Hugging Face 上的模型。例如,选择Llama 3 – 8B Instruct模型,只需点击下载,即可将其保存至本地。

如果你遇到网络问题无法直接从Hugging Face下载模型,不必担心。你可以通过修改LM Studio的配置文件C:\Users\你的用户名\.cache\lm-studio\downloads.json,将下载链接替换为镜像站点,之后重启LM Studio即可顺利下载。



下载完成后,点击界面左侧的Local Server图标,选择你刚下载的模型,并启动服务器。
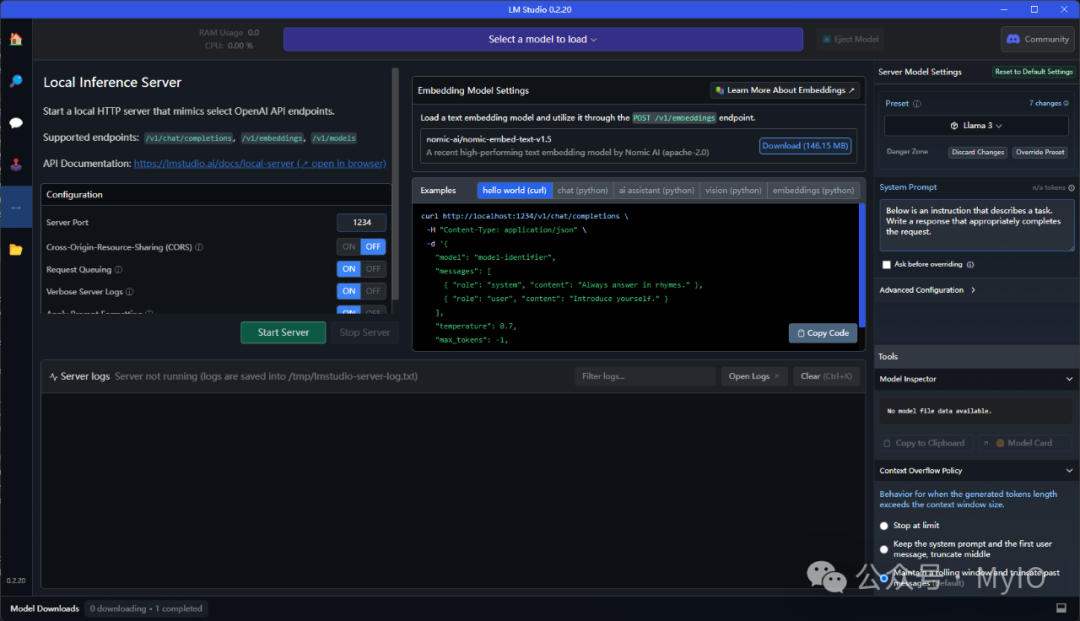
值得注意的是,LM Studio提供的本地服务器公开的REST API与OpenAI API兼容。这意味着,你之前编写的与OpenAI交互的代码同样适用于LM Studio托管的模型。
与 LLM 交互
Semantic Kernel支持OpenAI API,因此理论上也能与LM Studio的开源LLM协同工作。尽管在初始化Semantic Kernel时无法指定API端点,但你可以通过一个小技巧——定制HttpClient——来重定向所有HTTP请求至本地服务器。
public class MyHttpMessageHandler : HttpClientHandler
{
protected override Task
{
if (request.RequestUri != && request.RequestUri.Host.Equals(“api.openai.com”, StringComparison.OrdinalIgnoreCase))
{
request.RequestUri = new Uri($“http://localhost:1234{request.RequestUri.PathAndQuery}”);
}
returnbase.SendAsync(request, cancellationToken);
}
}
HttpClient client = new HttpClient(new MyHttpMessageHandler());
var kernel = Kernel.CreateBuilder()
.AddOpenAIChatCompletion(model, apiKey, httpClient: client)
.Build();
在Semantic Kernel初始化时,你可以随意提供模型名称和API密钥,因为LM Studio服务器会忽略这些信息,并始终将请求路由至当前托管的模型。
现在,你可以使用标准的Semantic Kernel代码来执行提示,享受与LLM交互的便捷。
string prompt = “你是谁?”;
var response = await kernel.InvokePromptAsync(prompt);
Console.WriteLine(response.GetValue

结论
通过LM Studio和Semantic Kernel的结合,我们不仅能够在本地环境中运行强大的LLM,还能享受到OpenAI API标准带来的便利。