背景
Llama3发布了,这次用了24000块gpu,训练了15T的数据,提供了8B和70B的预训练和指令微调版本。
小团队玩玩推理就好了。
阿里云今天也推出了针对Llama3的限时免费训练、部署、推理服务。

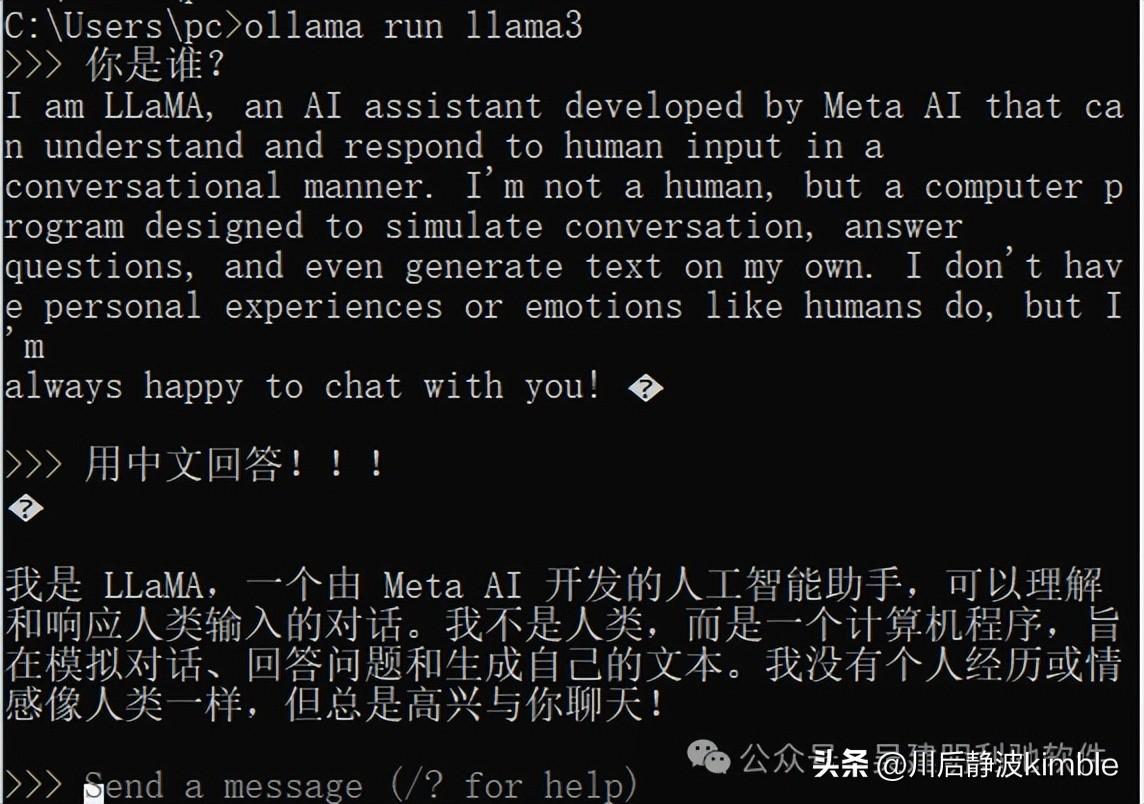
我们在本地,运行以下命令,即可下载模型Llama3。
ollama run llama3
即可实现和Llama3对话。
ollama只能使用自己官网发布的,如何制作并使用自己的模型呢?
导入模型
本指南逐步介绍如何导入 GGUF、PyTorch 或 Safetensors 模型。
导入 (GGUF)
第 1 步:编写 Modelfile
首先创建一个 Modelfile 。这个文件是模型的蓝图,指定了权重、参数、提示模板等内容。
FROM ./mistral-7b-v0.1.Q4_0.gguf(可选项)许多聊天模型需要提示模板才能正确回答。
可以使用 Modelfile 中的 TEMPLATE 指令指定默认提示模板:
FROM ./mistral-7b-v0.1.Q4_0.gguf TEMPLATE “[INST] {{ .Prompt }} [/INST]”第 2 步:创建 Ollama 模型
最后,从我们的 Modelfile 创建一个模型:
ollama create example -f Modelfile第 3 步:运行模型
接下来,使用 ollama run 测试模型:
ollama run example “你最喜欢的吃啥?”导入(PyTorch 和 Safetensors)
从 PyTorch 和 Safetensors 导入的过程比从 GGUF 导入的过程更长。
Setup 设置
首先,克隆 ollama/ollama 存储库:
git clone git@github.com:ollama/ollama.git ollama cd ollama然后获取其 llama.cpp 子模块:
git submodule init git submodule update llm/llama.cpp接下来,安装 Python 依赖项:
python3 -m venv llm/llama.cpp/.venv source llm/llama.cpp/.venv/bin/activate pip install -r llm/llama.cpp/requirements.txt然后构建 quantize 工具:
make -C llm/llama.cpp quantize克隆 HuggingFace 存储库(可选)
如果模型当前托管在 HuggingFace 存储库中,请首先克隆该存储库以下载原始模型。
安装 Git LFS,,验证其已安装,然后克隆模型的存储库:
git lfs install git clone https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1 model转换模型
注意:某些模型架构需要使用特定的转换脚本。例如,Qwen 模型需要运行 convert-hf-to-gguf.py 而不是 convert.py
python llm/llama.cpp/convert.py ./model –outtype f16 –outfile converted.bin量化模型
llm/llama.cpp/quantize converted.bin quantized.bin q4_0第三步:写一个 Modelfile
接下来,为我们的模型创建一个 Modelfile :
FROM quantized.bin TEMPLATE “[INST] {{ .Prompt }} [/INST]”第 4 步:创建 Ollama 模型
最后,从 Modelfile 创建一个模型:
ollama create example -f Modelfile第 5 步:运行模型
接下来,使用 ollama run 测试模型:
ollama run example “你最爱的人是谁?”发布我们的模型(可选 – alpha)
发布模型处于早期 alpha 阶段。如果想发布模型以与其他人共享,请按照以下步骤操作:
1、创建一个帐户
2、复制Ollama 公钥:
macOS:cat ~/.ollama/id_ed25519.pubWindows: type %USERPROFILE%\.ollama\id_ed25519.pubLinux: cat /usr/share/ollama/.ollama/id_ed25519.pub3、将公钥添加到你的 Ollama 帐户
接下来,将模型复制到用户名的命名空间:
ollama cp example <your username>/example然后推送模型:
ollama push <your username>/example发布后,模型将在 https://ollama.com/<your username>/example 中提供。