最近想自定义部署个收集新闻+写作 agent,以为 coze 有更新,又去试了试,还是感觉太生硬了
搜索引擎插件,很多都显示”平台错误,请稍后再试或提交反馈”,对需要自定义的不友好,还是老老实实本地部署下最近很火的 crewAI 的 agent 项目
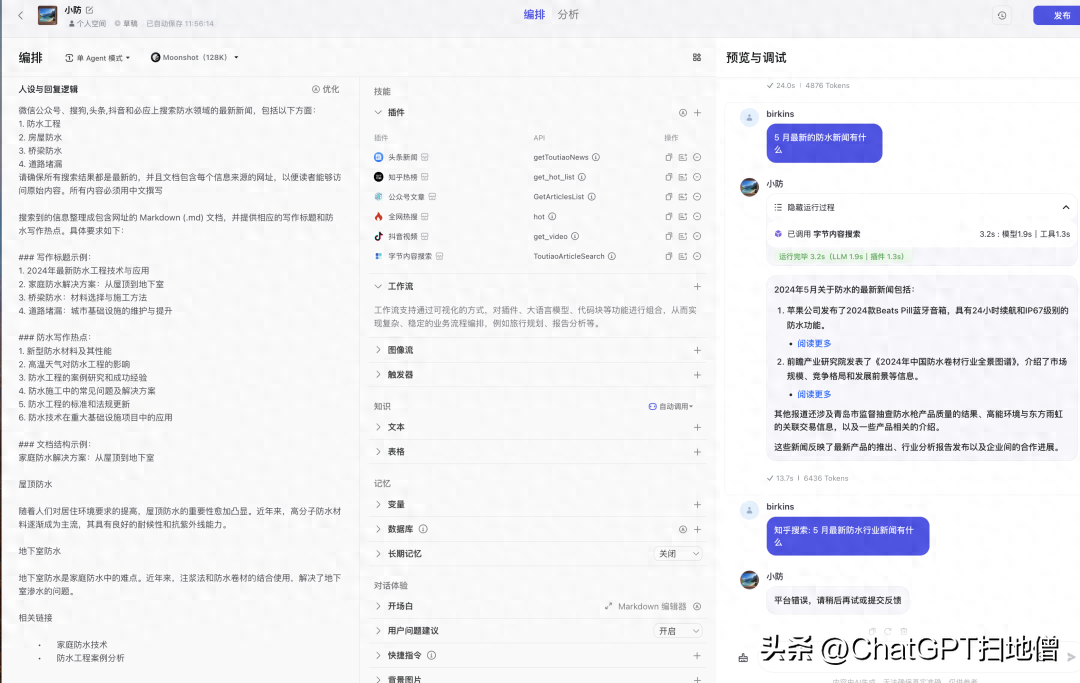
准备
终端运行,安装 crew 相关python包pip3 install crewai[tools]
打开 Ollama Mac 端的 app,让它在后台运行
LLM
除了 ollama,LM studio,也支持以下 api 格式的大模型,包括 FastChat,Mistral,solar,cohere 和微软的Azure OpenAI API

LLM supported in CrewAI
在项目文件上新建 ollamaModelFile,名称自己改,没有后缀,FROM 改成 ollama 下载模型的名称,可以修改 temperature
FROM qwen:110b # Set parameters PARAMETER temperature 0.8 PARAMETER num_ctx 32000 PARAMETER stop Result PARAMETER stop Error # 设置回答的重复性 PARAMETER repeat_penalty 1.4 PARAMETER repeat_last_n -1 # 设置回答的多样性 PARAMETER top_k 50 PARAMETER top_p 0.6 PARAMETER mirostat_eta 0.5 PARAMETER mirostat_tau 4.3 # Sets a custom system message to specify the behavior of the chat assistant # Leaving it blank for now. SYSTEM “”” You are a waterproofing expert specializing in conducting research and writing high-quality articles on waterproofing technologies. Your focus includes waterproof engineering for bridges, roofs, roads, and tunnels, as well as waterproof coatings, products, and companies. You should exclude consumer product waterproofing such as electronics. Provide detailed and accurate information in your responses “”” TEMPLATE “””{{ if .System }}system {{ .System }} {{ end }}{{ if .Prompt }}user {{ .Prompt }} {{ end }}assistant {{ .Response }} “””ModelFile 设置好了,再ollama create $custom_model_name -f ./ollamaModelFile就可以直接ollama run WaterproofLLM 等自定义的模型了,而且模型的参数都按照 ModelFile 的参数来的,算是 ollama 进阶玩法了,下面就是 parameter 各种可设置变量
ParameterDescriptionValue TypeExample Usagemirost启用Mirostat采样以控制困惑度。(默认值: 0, 0 = 禁用, 1 = Mirostat, 2 = Mirostat 2.0)intmirost 0mirost_eta影响算法响应生成文本反馈的速度。较低的学习率将导致较慢的调整,而较高的学习率将使算法更灵敏。(默认值: 0.1)floatmirost_eta 0.1mirost_tau控制输出的连贯性和多样性之间的平衡。较低的值将产生更集中和连贯的文本。(默认值: 5.0)floatmirost_tau 5.0num_ctx设置用于生成下一个令牌的上下文窗口大小。(默认值: 2048)intnum_ctx 4096repeat_last_n设置模型回溯以防止重复的步数。(默认值: 64, 0 = 禁用, -1 = num_ctx)intrepeat_last_n 64repeat_penalty设置对重复进行惩罚的强度。较高的值 (例如1.5) 将更强烈地惩罚重复,而较低的值 (例如0.9) 将更宽松。(默认值: 1.1)floatrepeat_penalty 1.1temperature模型的温度。提高温度将使模型回答更具创意。(默认值: 0.8)floattemperature 0.7seed设置用于生成的随机种子。将此设置为特定数字将使模型生成相同提示的相同文本。(默认值: 0)intseed 42stop设置停止序列。当遇到此模式时,LLM将停止生成文本并返回。可以通过指定多个单独的 stop 参数在模型文件中设置多个停止模式。stringstop “AI assistant:”tfs_z使用尾部自由采样以减少不太可能令牌对输出的影响。较高的值 (例如2.0) 将减少影响,而值为1.0将禁用此设置。(默认值: 1)floattfs_z 1num_predict生成文本时要预测的最大令牌数。(默认值: 128, -1 = 无限生成, -2 = 全上下文)intnum_predict 42top_k降低生成无意义文本的概率。较高的值 (例如100) 将生成更具多样性的答案,而较低的值 (例如10) 将更保守。(默认值: 40)inttop_k 40top_p与top-k一起工作。较高的值 (例如0.95) 将导致更具多样性的文本,而较低的值 (例如0.5) 将生成更集中和保守的文本。(默认值: 0.9)floattop_p 0.9
还可设置 template,包括模型回复 response,用户 prompt 和系统的 system
常见模版是
TEMPLATE “””{{ if .System }}<|im_start|>system {{ .System }}<|im_end|> {{ end }}{{ if .Prompt }}<|im_start|>user {{ .Prompt }}<|im_end|> {{ end }}<|im_start|>assistant “””理解为:
TEMPLATE “”” 和 **”””**:• 这段代码开始和结束的 TEMPLATE “”” 和 “”” 表示定义一个多行字符串模板。这种形式通常用于在代码中包含多行文本。
{{ if .System }}system:• {{ if .System }} 表示一个条件判断,检查 .System 是否存在或为真。如果 .System 存在(即不为空),则执行以下的内容。
• system 是输出的文本,表示系统消息的开始。
**{{ .System }}**:• {{ .System }} 表示将 System 的内容插入到这里。System 是一个模板变量,包含系统消息的内容。
**{{ end }}**:• {{ end }} 结束条件判断块,表示如果 System 存在,输出从 {{ if .System }} 到 {{ end }} 之间的内容。
{{ if .Prompt }}user:• {{ if .Prompt }} 表示另一个条件判断,检查 .Prompt 是否存在或为真。如果 .Prompt 存在(即不为空),则执行以下的内容。
• user 是输出的文本,表示用户提示的开始。
**{{ .Prompt }}**:• {{ .Prompt }} 表示将 Prompt 的内容插入到这里。Prompt 是一个模板变量,包含用户提示的内容。
**{{ end }}**:• {{ end }} 结束条件判断块,表示如果 Prompt 存在,输出从 {{ if .Prompt }} 到 {{ end }} 之间的内容。
assistant:• assistant 是输出的文本,表示助手的响应的开始
“
system 消息主要用于设置对话或任务的背景和规则,指导模型如何表现和回应。它通常包含背景信息、角色设定、行为准则等。这些信息通常不直接显示给最终用户,而是帮助模型在特定的上下文中更好地生成响应
ModelFile 设置好了,再ollama create $custom_model_name -f ./ollamaModelFile就可以直接ollama run WaterproofLLM 等自定义的模型了,而且模型的参数都按照 ModelFile 的参数来的,算是 ollama 进阶玩法了
如下图,问模型是不是防水专家,他已经按照我在 ModelFile 设置的 prompt 回答了
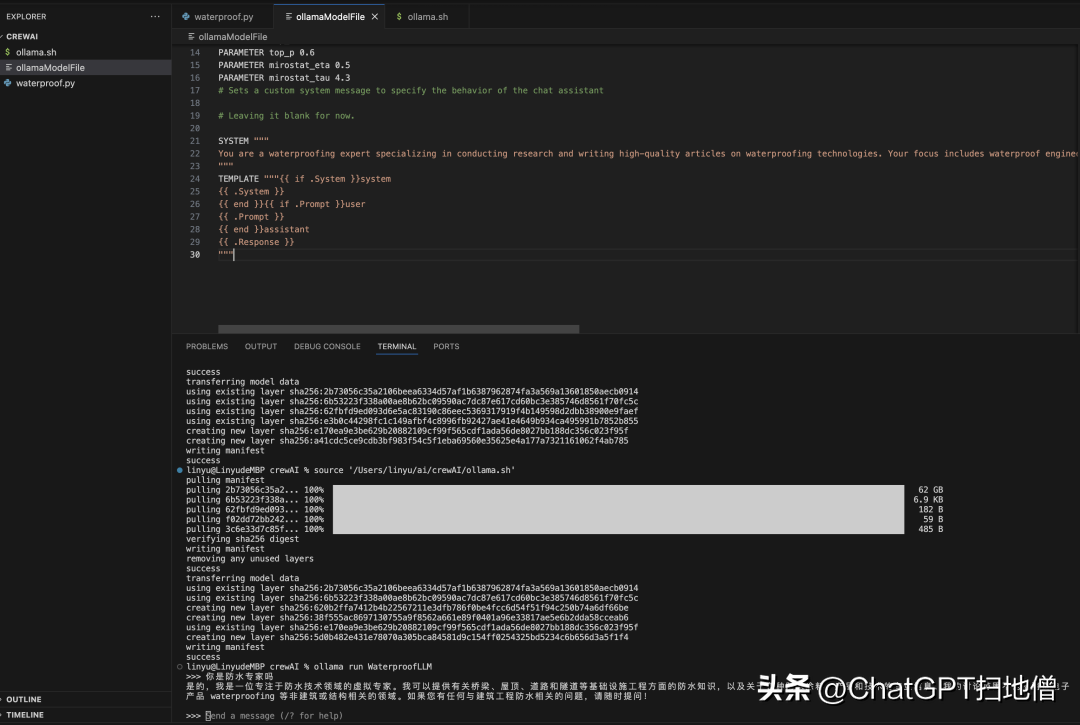
再回到 CrewAI 项目
再新建 .sh 文件,名称也自定义,用来配置模型名称
#!/bin/zsh # 自定义模型名称 model_name=“qwen:110b” custom_model_name=“waterproofLLM” #get the base model ollama pull $model_name #加载刚建的ModelFile ollama create $custom_model_name -f ./ollamaModelFile在运行 py 文件之前,在终端source xx.sh 文件,准备模型
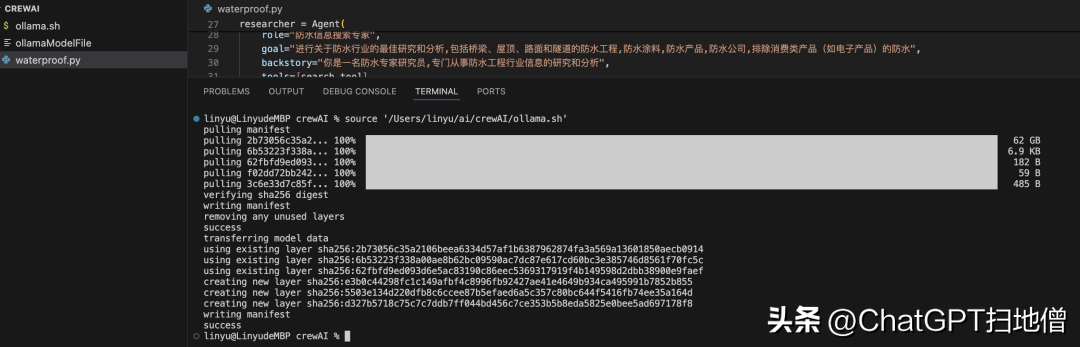
在 py 文件中,ollama 的部署代码如下,注意 api-key 这段代码必须要有,根据官方文档填的NA
os.environ[“OPENAI_API_KEY”] = “NA” llm = ChatOpenAI( model = “waterproofLLM”, base_url = “http://localhost:11434/v1”)Agent
agent 支持的变量,其中 allow_delegation 为 ture 时,这个 agent 就能将自己任务分派给别的 agent

• function_calling_llm(可选):将ReAct crewAI代理转换为函数调用代理。
• max_iter:代理执行任务的最大迭代次数,默认为15。
• memory:使代理在执行期间及跨执行时保留信息。默认为False。
• max_rpm:代理执行时每分钟的最大请求数。可选。
• verbose:启用详细的代理执行日志记录。默认为False
tool
这里用了 serper 的 api,注册就有免费调用额度2500 credit,一次搜索时 1 个 credit
在官方文档,还有让 LLM 阅读pdf,doc,json,youtube video等格式内容的工具,当然就需要设置相应的向量模型

main.py代码
这里把 agent,tool,task都放在一起的,实际可以各自形成文件分开放
import os from crewai import Agent, Task, Crew, Process from crewai_tools import SerperDevTool from langchain_openai import ChatOpenAI # 设置 ollama 模型 See https://docs.crewai.com/how-to/LLM-Connections/ for more information. os.environ[“OPENAI_API_KEY”] =NA llm = ChatOpenAI( model = “waterproofLLM”, base_url = “http://localhost:11434/v1”) # You can pass an optional llm attribute specifying what model you wanna use. # It can be a local model through Ollama / LM Studio or a remote # model like OpenAI, Mistral, Antrophic or others (https://docs.crewai.com/how-to/LLM-Connections/) # # import os # os.environ[OPENAI_MODEL_NAME] = gpt-3.5-turbo # OR # # from langchain_openai import ChatOpenAI # 配置搜索工具 os.environ[“SERPER_API_KEY”] = “9c7775d1b9fd75d3546ce41613a25e1dab2148ea” search_tool = SerperDevTool() # 设置 agent 角色 researcher = Agent( role=“防水信息搜索专家”, goal=“进行关于防水行业的搜索和调研,要广泛搜索各种跟防水直接或间接相关联的新闻,咨询和信息”, backstory=“你是一名防水搜索专家,专门从事防水工程行业信息的检索和分析”, tools=[search_tool], allow_delegation=False, verbose=True, llm=llm, ) #定义防水写作专家,可以换模型 # writing_llm = ChatOpenAI( # model=”WriteAI”, # base_url=”http://localhost:11434/v1″ # writer = Agent( role=防水写作专家, goal=根据防水信息搜索专家提供的信息,撰写高质量的中文防水文章, backstory=“””Y你是一名防水写作专家,擅长将防水工程的专业信息转化为易懂且有深度的中文文章,整理成条理清晰的文章给人类检查,检查通过后再做进一步完善”””, verbose=True, allow_delegation=True, llm=llm, max_rpm=100, cache=True, # 允许人类干预 human_input=True ) headline_specialist = Agent( role=防水文章标题写手, goal=根据防水写作专家提供的信息,撰写至少 8 个经过SEO优化,具有吸引力和搜索关键字的爆款标题,每个标题打分,比如 9/10, backstory=“””你是一名防水文章标题写手,擅长给防水文章起专业又具有吸引力的爆款标题.”””, verbose=True, allow_delegation=False, cache=False ) # Create tasks for your agents search_task = Task( description=“””搜索提供至少3 条 这一周的防水新闻,为确保准确,加上每篇新闻的日期”””, expected_output=“以项目符号形式呈现,根据分类,包含所有相关信息和最新动态,每个信息都要加上 url 原文网址”, agent=researcher ) write_task = Task( description=“””根据防水信息搜索专家的搜索结果,整理成专业的防水文章”””, expected_output=“文章应有分类的小标题,采用Markdown格式输出,字数不少于6000字,文字风格严肃正式,在文章最后加上url 原文网址”, agent=writer ) headline_task = Task( description=“””根据防水写作专家提供的文章内容,撰写至少 8 个SEO优化且具有吸引力的标题,并为每个标题评分(例如9/10).”””, expected_output=“至少有 8 个标题,并在每个标题后面打分”, agent=headline_specialist ) # Instantiate your crew with a sequential process crew = Crew( agents=[researcher, writer,headline_specialist], tasks=[search_task,write_task,headline_task], process=Process.sequential, verbose=2, # You can set it to 1 or 2 to different logging levels ) # 上面是按顺序一个个执行 task,也可以是根据一个目标,分配给各个 agent 一起执行,就要用hierarchical,并且需要一个服装监管这些agent 的 manager # process=Process.hierarchical # manager_llm=ChatOpenAI(model=”gpt-4″) # Get your crew to work! result = crew.kickoff() print(“######################”) print(result)结果
执行也是根据指令细化拆解,一步步执行的,网络搜索都是按照我给的关键词一个一个地搜索

另外,role 的名称相当于专业术语了,必须严格一致,我把 role 制定的防水信息搜索专家,而在写作专家的要求中让他根据防水搜索专家的结果来写,结果就报错,如下图

在运行过程中,我这台macbook pro 的风扇响声很明显,qwen:110b 模型大小就 60G+,运行起来用了 86G 内存,运行速度也比较慢,py 文件需要 5 分钟才能运行
但这个项目确实能让模型自己根据任务回答,而且流程在终端都能看见,大家可以从下图体会一下 agent 的自动化
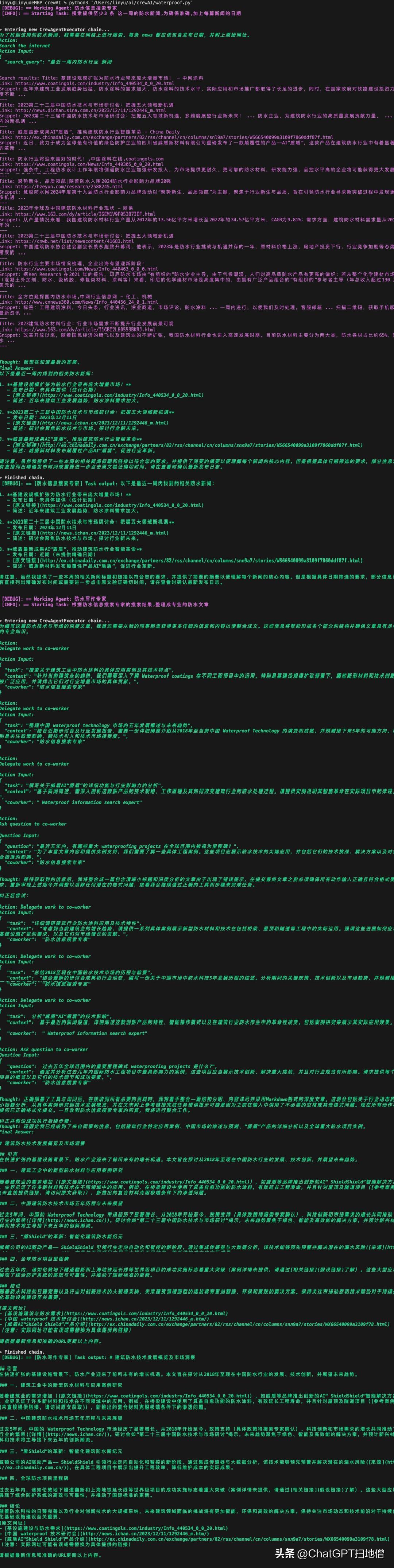
防水新闻收集和写作
后记
更高级的玩法去 crewAI 的github,有会议总结,飞机订票,发 ins 等专业的example,在专业的 example 做修改会更实用些
本文提供的仅仅是基本 crewAI 玩法
没想到部署 CrewAI 还把 ollma 的进阶玩法学会了,原来 ollama 也支持提示词