6月27日凌晨,全球著名开源平台HuggingFace的联合创始人兼首席执行官Clem在社交平台宣布,他们使用了300块H100对当前全球100多个主流开源模型,重新进行了评估。
官方博文榜单显示,阿里开源的Qwen2 72B排名第一;科技巨头Meta开源的Llama-3-70B指令微调版本位列第二;法国知名大模型平台Mistralai的Mixtral排名第三。
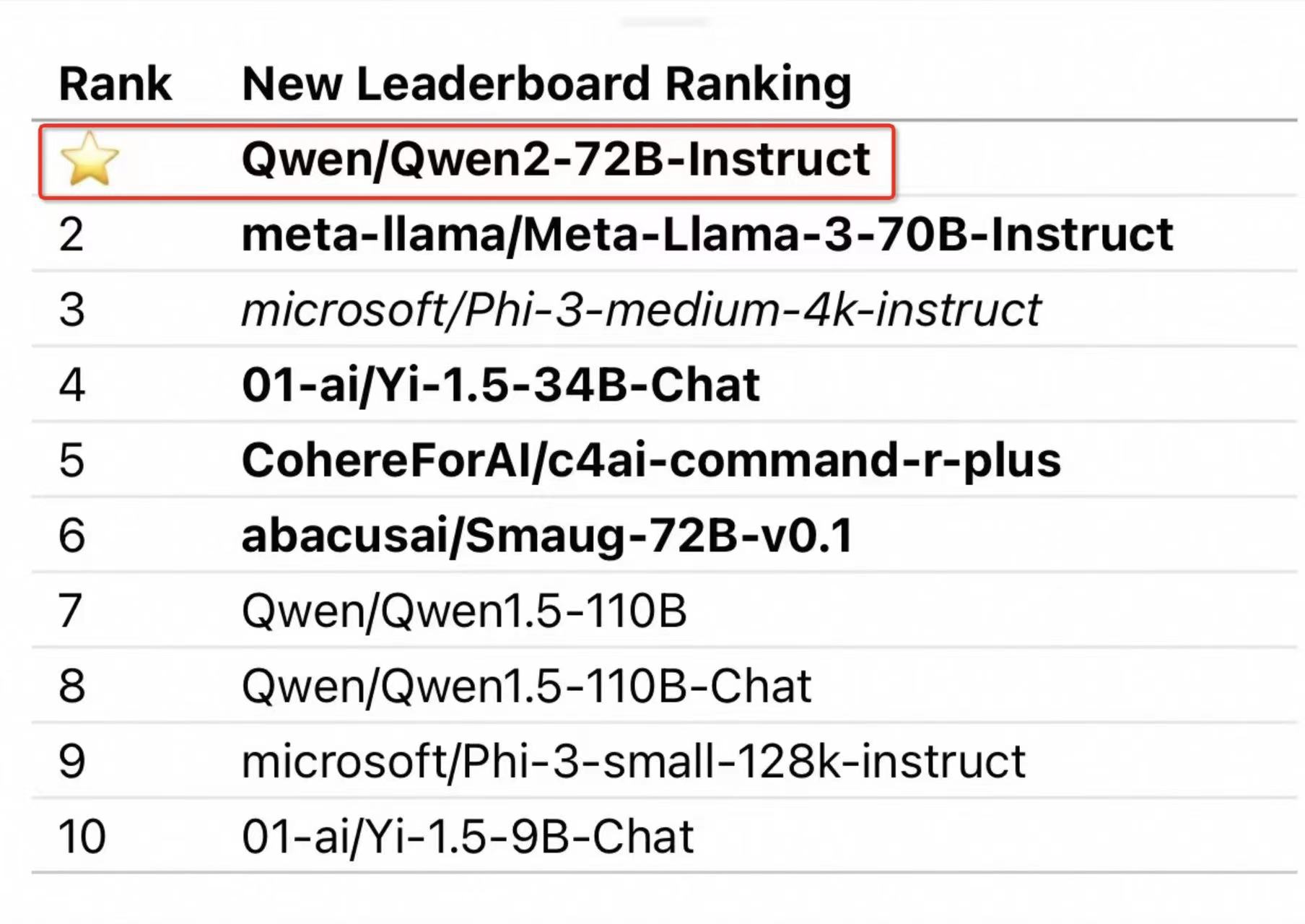
对于重新评估的原因,Clem称目前开发者太注重排行榜的名次,在训练过程中使用了很多评估集的数据,并且之前的评估流程对于那些模型来说太简单了,“所以本次给这些模型加大了难度,想看看它们的真正实力。”
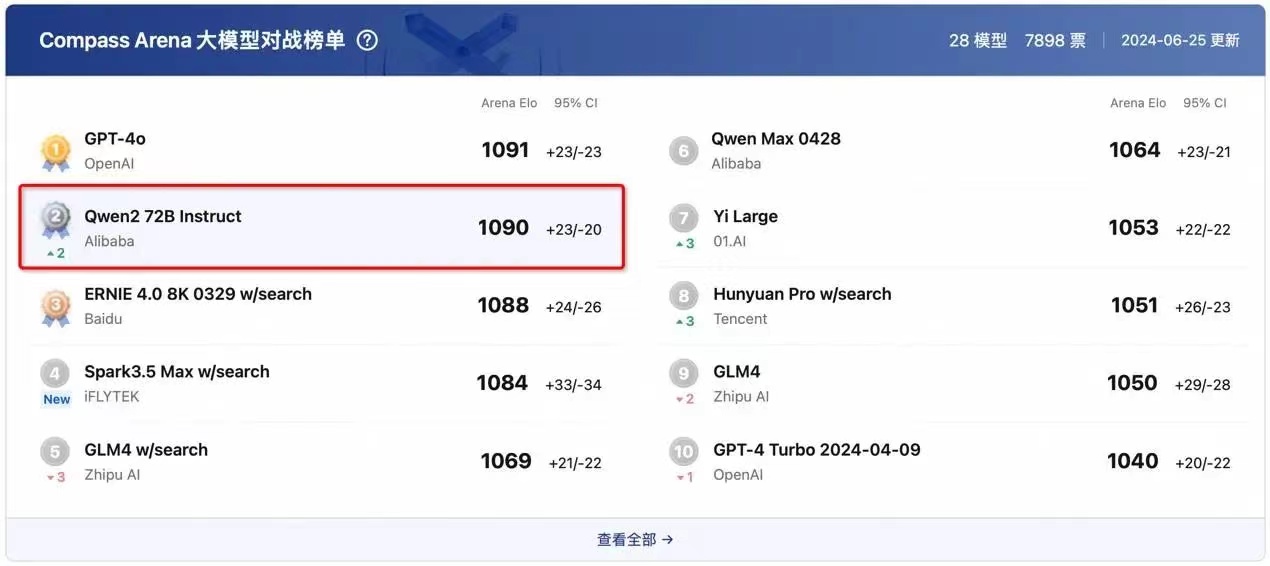
同样在6月27日,上海人工智能实验室大模型测评榜单CompassArena公布最新结果,阿里通义千问Qwen2-72B得分仅次于GPT-4o,以1分之差排名第二,成为排名最高的开源大模型,总成绩也超过国内一众闭源模型。
被“团宠”
备受市场关注的开源模型通义千问Qwen2系列,于6月7日揭开神秘面纱。
当日凌晨,阿里免费开源Qwen2系列5个尺寸的预训练和指令微调模型:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B,其中Qwen2-57B-A14B为混合专家模型(MoE)。
两小时后,全球开源社区Hugging Face宣布Qwen2的72B模型直接冲上其开源大模型榜单,排名超过了其2月发布的Qwen1.5-110B和美国的Llama3-70B。另外有多个重要的开源生态伙伴火速宣布支持Qwen2,包括TensorRT-LLM、OpenVINO、OpenCompass、XTuner、LLaMA-Factory、Firefly、OpenBuddy、vLLM、Ollama等。
据悉,Qwen2小尺寸模型可以部署在耳机、手机等端侧设备,大尺寸模型能够用于企业界、科研级的场景。与前代Qwen1.5相比,Qwen2的多语言处理、长文本处理、代码生成、数学和逻辑推理等能力明显提升。
发布后,在魔搭ModelScope和阿里云百炼平台火速上线,普通用户可在魔搭或Compass Arena等平台直接体验模型。与此同时,Qwen2系列也吸引了众多开发者前去测试。

Qwen系列模型在全球的爆火,在下载量上也有反馈,据报道截至6月初,下载量已突破1600万次。海内外开源社区已经出现了超过1500款基于Qwen二次开发的模型和应用。
近期金沙江创投主管合伙人朱啸虎,在多个场合发表了关于AI投资的观点,在谈及开源闭源模型时,他表示“在很多场景下,国内开源模型已经不比闭源模型差,完全足够支撑中国AI应用的发展。尤其在中文知识方面,阿里的通义千问比Llama 3还要强,所以很多创业公司都是拿1000万参数的开源模型来训练自己的垂直模型。”
开源阵营正在扩大
开源和闭源,一直是大模型时代讨论的焦点。
在开源通义千问Qwen2系列模型之前,5月9日,阿里云还发布了闭源模型通义千问2.5,称中文场景性能超过GPT-4。从某种程度上来说,通义千问在开源闭源路线上是齐头并进。
阿里云CTO周靖人表示,“阿里云既有开源模型,也有闭源模型,实际上形成的是开源和闭源整体的体系,我们为企业提供的是全方位的服务。”
他认为模型选择其实不是越大越好,也不是模型能力越强越好,因为还要考虑模型服务成本等问题,所以我们把选择给到企业和开发者,让他们自己做主。

那么企业、开发者们又是如何看待开源模型呢?个人开发者、中国能源建设集团浙江省电力设计院有限公司系统室专工陶佳表示国外的模型,闭源的如OpenAI,能力很强,但是API调用不便,“而且我们这种B端用户更喜欢自己上手定制,API能做的事还是太少;开源的比如Llama,中文能力一般。通义千问开源模型,对企业级应用是个比较好的起点。”
无独有偶,未来速度联合创始人&CEO秦续业认为开源模型能够在最小限度上满足企业的需求。而且开源模型有各种尺寸,总有一款适合你,如果试过以后发现所有的模型都不行,那可能这个需求本来就不成立。
另据有鹿机器人创始人、CEO陈俊波介绍,其公司正在研发第二代具身智能技术LPLM大模型。LLM本身是一个偏慢速的、逻辑推理的、有比较完整的结构性思考的智能系统。物理世界大模型,是一个更偏实时响应的、偏直觉的一套思维过程。LPLM本质上是融合了这两个系统,使它们能够很好地配合跟协作,能够从人类的高层的指令理解、到拆解、再到底层对物理世界进行理解和规划。
他称市面上能找到的大模型都做过实验,最后选择了通义千问,原因主要是,它是目前至少在中文领域我们能找到的智能性表现最好的开源大模型之一;并且提供了非常方便的工具链,可以在他们自己的数据上快速地去做finetune和各种各样的实验;以及提供了一个特式量化的模型,量化前跟量化后基本上没有掉点。
作为国内最早开源自研大模型的“大厂”,阿里云从2023年8月起密集开源模型,从Qwen到Qwen1.5再到Qwen2三代开源模型,实现了全尺寸、全模态开源。不到一年时间,Qwen系列的72B、110B模型多次登顶HuggingFace 的Open LLM Leaderboard开源模型榜单。
值得注意的是,目前国内不少企业也加入开源阵营,比如在5月13日,零一万物将早先发布的Yi-34B、Yi-9B、6B中小尺寸开源模型版本升级为Yi-1.5系列,每个版本达到同尺寸中 SOTA 性能最佳。
再观海外,微软、谷歌等都相继发布开源模型。就在6月27日谷歌也面向全球研究人员和开发人员发布Gemma 2语言模型,共有90亿参数和270亿参数两种大小。
早前,与媒体沟通中,周靖人在谈及开源技术时表示,在2024年的今天,开源技术对于全球技术的发展价值已经毋庸置疑,不管从国际还是国内来看,开源模型的发展速度都比预期的更快,并称通义未来也还会持续开源。
5月14日,阿里巴巴集团发布2024财年Q4及全年业绩。财报显示本季度,阿里云收入同比增长3%,其中核心公共云产品收入实现双位数同比增长,AI相关收入增长加快,持续实现三位数同比增长。
在财报分析师电话会上,阿里巴巴集团CEO、阿里云智能集团董事长兼CEO吴泳铭说,本季度阿里云已经完成了面向AI时代阿里云的产品策略调整,收入质量持续提升,核心公共云产品收入双位数增长,AI相关收入实现三位数的同比加速增长。吴泳铭表示,通义大模型与阿里云先进的AI基础设施将深度融合,实现软硬件层面的协同优化,“基于领先的产品组合、对AI基础设施的大力布局以及积极的行业伙伴策略,我们有信心,阿里云的商业化营收(剔除集团内客户)在2025财年下半年能重返双位数增长。”