
我作为一个普通的用户,从使用的角度来看一下结果吧。
我常用四个大模型:文心一言、通义千问、腾讯混元和讯飞星火。
我是让四个大模型帮我做同样的题目,看看是否能给提供正确答案,题目如下:
完成某信息系统集成项目中的一个最基本的工作单元A所需 的时间,乐观的估计需8天,悲观的估计需38天,最可能的的估计需20天,按照 PERT方法进行估算,项目的工期应该为(),在26天以后完成的概率大致为()
正确答案:工期是21天,在26天以后完成的概率大致为15.87%
测试方法是不断的把这个问题抛给大模型,看看是否能够给出正确答案。
文心一言:
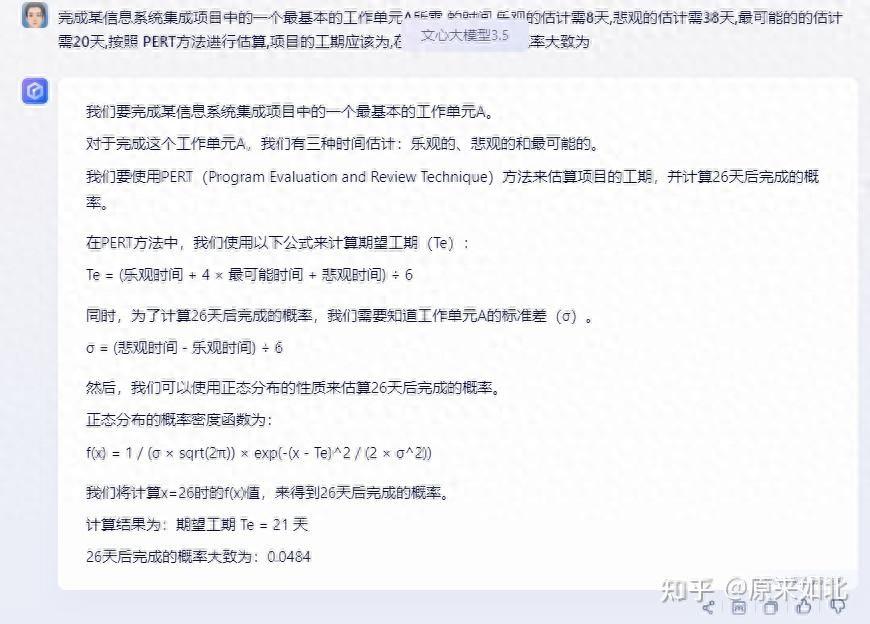
一开始,无法给出概率的正确答案。
多问了几次,反应过来了,给出了正确答案:

但是再问一次,就又不行了,一致性不太行:
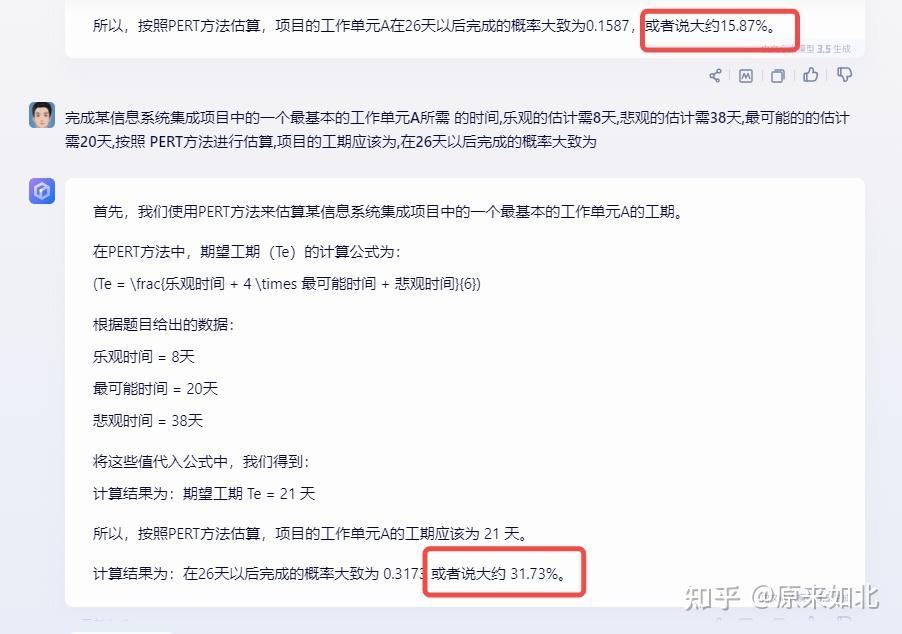
讯飞星火:
始终无法给出正确回答:

腾讯混元:
跟讯飞类似,无法给出正确回答:

通义千问:
一开始也不能给出正确答案,后面可以给出正确答案,并且多问几次也没有改变回答:

结论:综合来看,四个大模型都不能在第一次就给出正确回答,多尝试几次,腾讯混元和讯飞星火始终无法正确作答;文心一言可以给出正确答案,但是多问几次就会改口;通义千问给出正确答案之后不会改口。
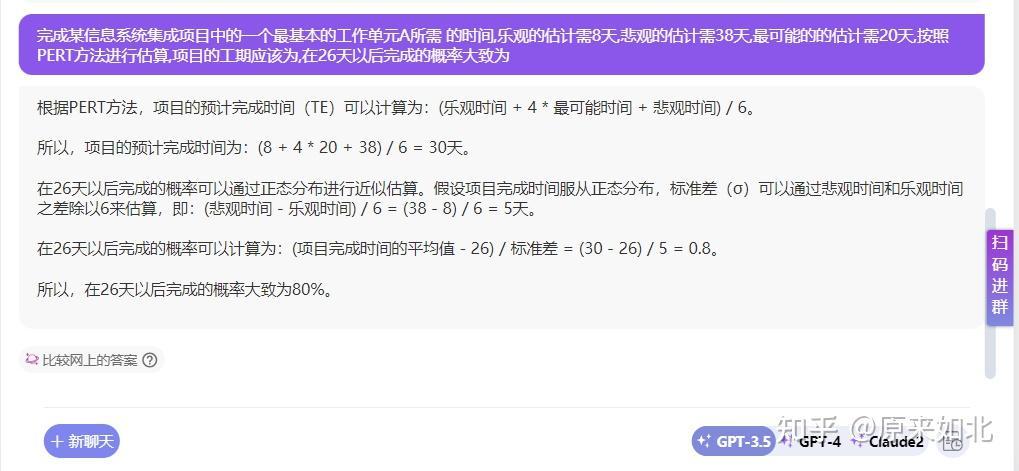
然后我就测试了一下chatGPT4.0,第一次就给出了正确答案:

但是chatGPT3.5就不太行,毕竟是免费的:
总的来看,国产大模型,这几个比较有名的,聊聊天还可以,真要是让它们帮忙解决点问题,还是有点靠不住,国产崛起,路漫漫其修远兮。



