
大家好,当前的AI生态正全面拥抱大模型,以大模型为桥梁,连接并重塑着万物。在国内,众多大模型如雨后春笋般蓬勃发展,共同描绘出一幅AI的繁荣画卷。尽管其中不乏一些滥竽充数、借势炒作的成分,但总体来看,国产大模型的领军企业正以前所未有的速度迅猛进步。
 我们不禁要问,大模型得以迅猛发展的关键因素究竟何在?国内大模型的最新进展又达到了怎样的高度?大模型哪家强?接下来我们一探究竟!
我们不禁要问,大模型得以迅猛发展的关键因素究竟何在?国内大模型的最新进展又达到了怎样的高度?大模型哪家强?接下来我们一探究竟!
大模型发展的关键因素
数据质量,无疑是训练大模型不可或缺的核心要素。在当下大模型竞相绽放的时代背景下,数据的质量往往决定了模型的最终表现。这包括了数据采集的完整性、数据标注的精准度以及数据质检的严格性,每一个环节都需要专业的团队精心管理与维护,确保数据的高品质。算法与模型优化同样是大模型发展的关键所在。我们必须不断地进行算法的优化和模型的调整,以提高模型的性能,确保其能够高效且精准地处理各种任务。此外,算力资源也是大模型发展中不可忽视的一环。大模型的训练和推理过程都需要庞大的算力支持,包括高性能计算机、GPU等先进设备的投入。算力资源的丰富程度直接决定了大模型的训练速度和推理效率,因此,不断提升算力资源的规模和质量是推动大模型发展的重要保障。最后,大模型的应用场景也至关重要。我们需要结合具体的应用场景,对模型进行针对性的训练和应用优化,以提升模型的实用性和可扩展性。 大模型的发展趋势大模型的发展趋势呈现出规模化、多模态化、跨领域化、迁移化、自监督化以及标准化和模块化等特点。这些趋势共同推动了大模型技术的不断进步和广泛应用,为人工智能领域的发展注入了新的活力。模型规模与性能提升:随着计算资源的不断增加和数据集的持续扩大,大模型的规模将继续增长。多模态融合:大模型越来越倾向于整合多种数据模态,包括文本、图像、音频等。这种多模态融合能够提供更丰富的信息,提升模型的表现能力。跨领域应用:大模型在不同领域的应用范围正在不断扩展,涵盖计算机视觉、语音识别等各个领域。这种跨领域应用的能力使得大模型具有更广泛的实用性和价值。。自监督与无监督学习:为了解决标注数据的稀缺和昂贵问题,大模型正在向自监督学习和无监督学习倾斜。这种方法可以利用未标记的数据进行模型训练,从而减少对数据标注的依赖,降低训练成本。标准化与模块化发展:随着大模型技术的普及和成熟,模型的标准化和模块化发展也成为了一个重要的趋势。
大模型的发展趋势大模型的发展趋势呈现出规模化、多模态化、跨领域化、迁移化、自监督化以及标准化和模块化等特点。这些趋势共同推动了大模型技术的不断进步和广泛应用,为人工智能领域的发展注入了新的活力。模型规模与性能提升:随着计算资源的不断增加和数据集的持续扩大,大模型的规模将继续增长。多模态融合:大模型越来越倾向于整合多种数据模态,包括文本、图像、音频等。这种多模态融合能够提供更丰富的信息,提升模型的表现能力。跨领域应用:大模型在不同领域的应用范围正在不断扩展,涵盖计算机视觉、语音识别等各个领域。这种跨领域应用的能力使得大模型具有更广泛的实用性和价值。。自监督与无监督学习:为了解决标注数据的稀缺和昂贵问题,大模型正在向自监督学习和无监督学习倾斜。这种方法可以利用未标记的数据进行模型训练,从而减少对数据标注的依赖,降低训练成本。标准化与模块化发展:随着大模型技术的普及和成熟,模型的标准化和模块化发展也成为了一个重要的趋势。
国内 AI 大模型发展近况
国内已有发布200个左右的大模型,也有许多有前途的AI大模型。其中,字节跳动和百度是比较被看好的,他们拥有高质量的中文私有数据、专业的团队、丰富的GPU资源,以及强大的技术实力。此外,智谱和Moonshot也是国内大模型创业公司的代表,他们拥有独特的商业模式和融资优势,特别的,近期Moonshot的Kimi融资上很顺利,产品也可圈可点。其他公司也各有特点,但目前尚未公开表示具体的技术进展和优势。
总之,人工智能大模型是未来的发展趋势,国内有许多有前途的公司和团队,但需要不断提高技术实力和创新能力才能在这个领域中保持领先地位。
国内外大模型排行榜
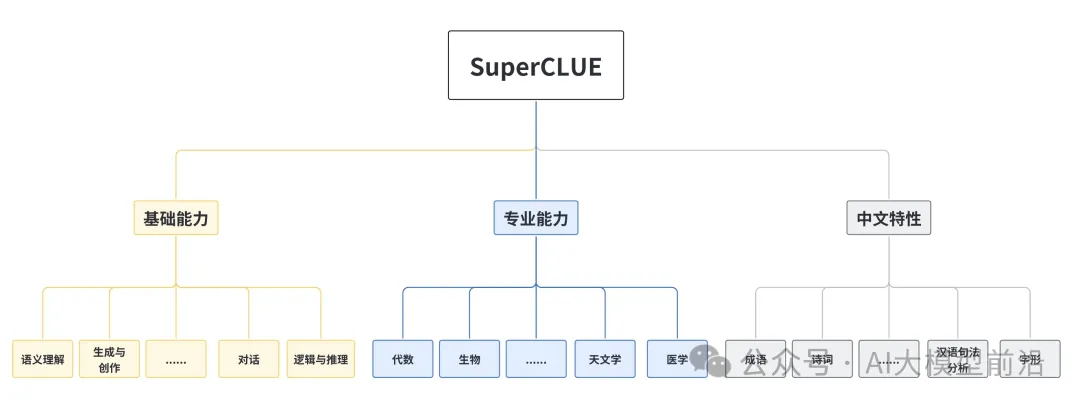
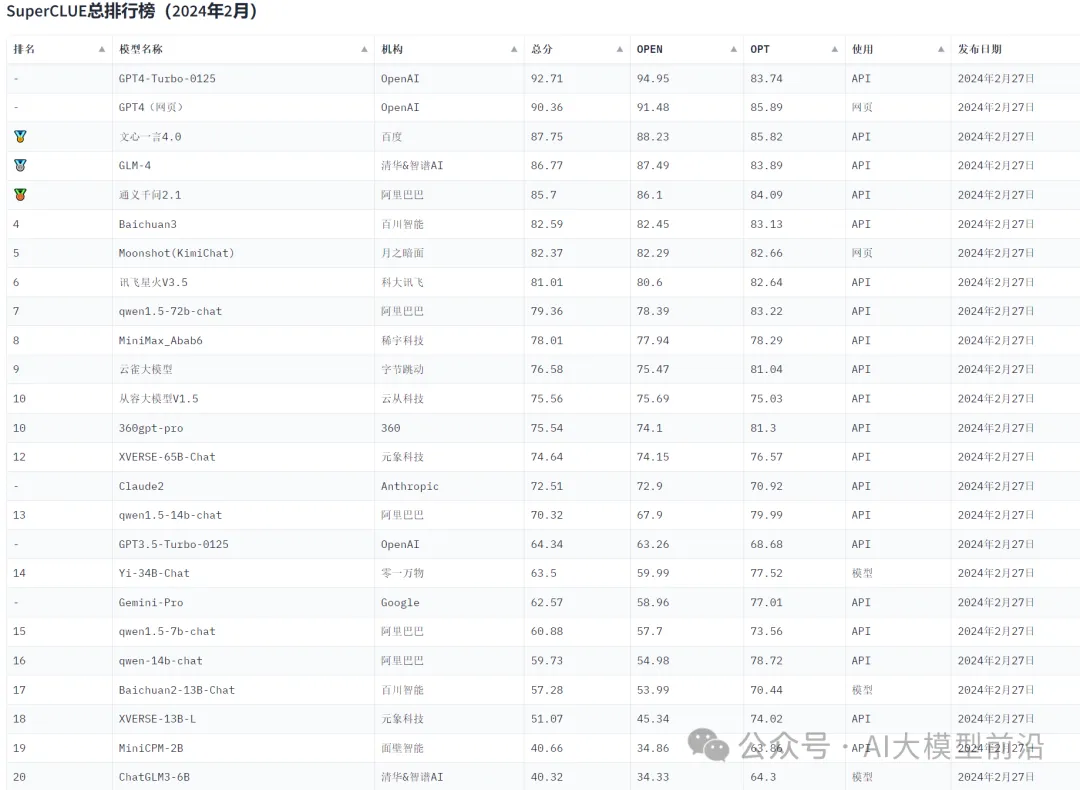
根据中文通用大模型综合性测评基准(SuperCLUE),综合各项能力,大模型的排名如下:

 fill=%23FFFFFF%3E%3Crect x=249 y=126 width=1 height=1%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E) 参考链接:https://www.clue.ai/superclue.htmlhttps://www.superclueai.com/https://arxiv.org/abs/2307.15020https://github.com/wgwang/awesome-LLMs-In-Chinahttps://www.zhihu.com/question/608763410
参考链接:https://www.clue.ai/superclue.htmlhttps://www.superclueai.com/https://arxiv.org/abs/2307.15020https://github.com/wgwang/awesome-LLMs-In-Chinahttps://www.zhihu.com/question/608763410



