
文章主题:编程, 模型, 图示
通向AGI之路
码字真心不易,求点赞!
2022年可谓是AIGC(AI Generated Content)元年,上半年有文生图大模型DALL-E2和Stable Diffusion,下半年有OpenAI的文本对话大模型ChatGPT问世,这让冷却的AI又沸腾起来了,因为AIGC能让更多的人真真切切感受到AI的力量。这篇文章将介绍比较火的文生图模型Stable Diffusion(简称SD),Stable Diffusion不仅是一个完全开源的模型(代码,数据,模型全部开源),而且是它的参数量只有1B左右,大部分人可以在普通的显卡上进行推理甚至精调模型。毫不夸张的说,Stable Diffusion的出现和开源对AIGC的火热和发展是有巨大推动作用的,因为它让更多的人能快地上手AI作画。这里将基于Hugging Face的diffusers库深入讲解SD的技术原理以及部分的实现细节,然后也会介绍SD的常用功能,注意本文主要以SD V1.5版本为例,在最后也会简单介绍 SD 2.0版本以及基于SD的扩展应用。
SD模型原理
SD是CompVis、Stability AI和LAION等公司研发的一个文生图模型,它的模型和代码是开源的,而且训练数据LAION-5B也是开源的。SD在开源90天github仓库就收获了33K的stars,可见这个模型是多受欢迎。

SD是一个基于latent的扩散模型,它在UNet中引入text condition来实现基于文本生成图像。SD的核心来源于Latent Diffusion这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。
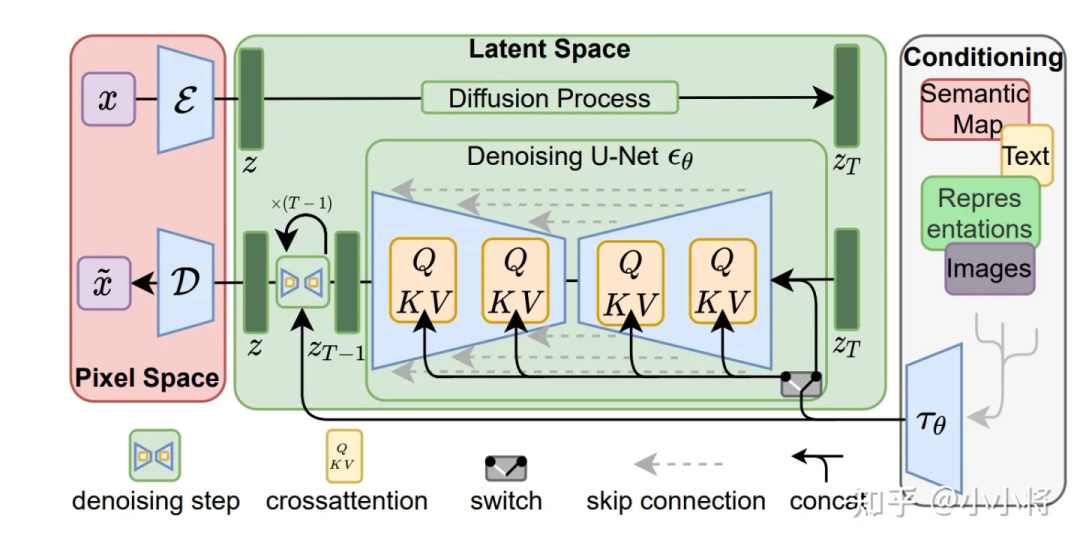
基于latent的扩散模型的优势在于计算效率更高效,因为图像的latent空间要比图像pixel空间要小,这也是SD的核心优势。文生图模型往往参数量比较大,基于pixel的方法往往限于算力只生成64×64大小的图像,比如OpenAI的DALL-E2和谷歌的Imagen,然后再通过超分辨模型将图像分辨率提升至256×256和1024×1024;而基于latent的SD是在latent空间操作的,它可以直接生成256×256和512×512甚至更高分辨率的图像。
SD模型的主体结构如下图所示,主要包括三个模型:
autoencoder:encoder将图像压缩到latent空间,而decoder将latent解码为图像;
CLIP text encoder:提取输入text的text embeddings,通过cross attention方式送入扩散模型的UNet中作为condition;
UNet:扩散模型的主体,用来实现文本引导下的latent生成。
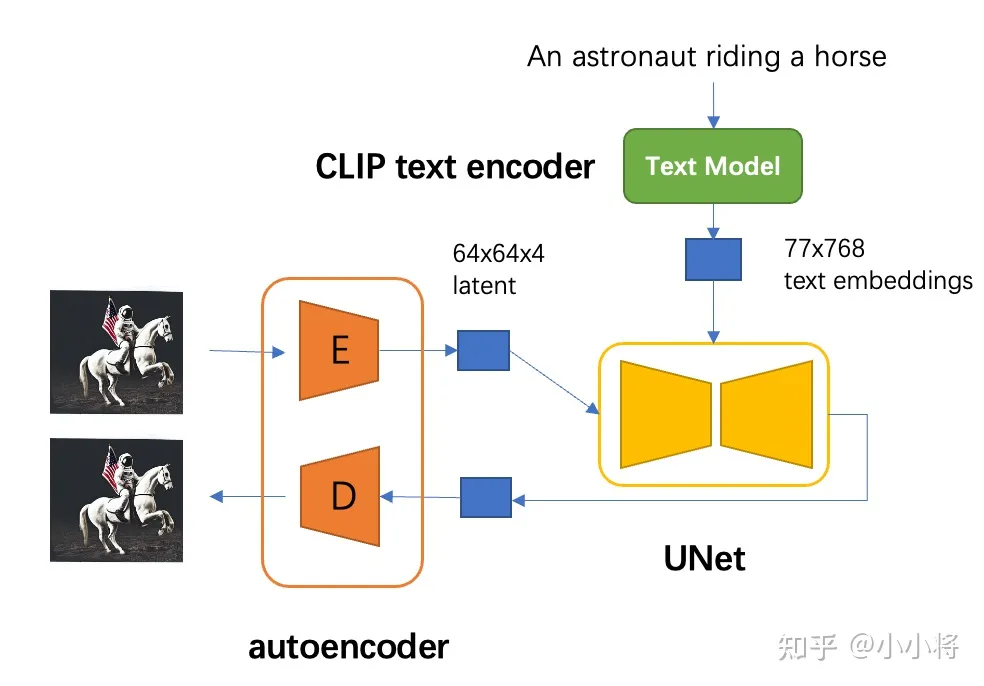
对于SD模型,其autoencoder模型参数大小为84M,CLIP text encoder模型大小为123M,而UNet参数大小为860M,所以SD模型的总参数量约为1B。
autoencoder
autoencoder是一个基于encoder-decoder架构的图像压缩模型,对于一个大小为H<span tabindex=”0″ data-mathml=”H

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!


