
文章主题:稳定扩散, AI图像生成, 文本到图像生成, 图像到文本生成
前几个月AIGC可谓是大热了一把,各种高质量的生成图片层出不穷,而其中最重要的开源模型Stable Diffusion也受到了各种技术商业上的热捧,以很快的速度不断的向前迭代着。之前作为一个没有相关知识基础的小白,为了了解相关的技术知识,找了很多文章看,最后还是发现Jay Alammar的这篇文章讲的最为通俗易懂,于是决定简单翻译一下,方便更多人从零开始了解这项强大的技术。
由于原文篇幅较长,所以这里分为三篇文章进行讲解:
第一篇,也就是本篇,主要讲“是什么”的问题,包括Stable Diffusion是什么,里面的各个模块是什么第二篇,主要讲“怎么办”的问题,也就是Diffusion怎么训练以及怎么使用的问题。第三篇,主要讲“如何控制”的问题,具体阐述语义信息到底是怎么影响生成图片的过程的。在本篇文章中,我们将正式探讨Stable Diffusion的概念,并深入剖析其内部包含的一些核心模块。
原文链接:The Illustrated Stable Diffusion有能力和时间的小伙伴还是更推荐阅读原文噢
作者:Jay Alammar译者:曾飞飞(知乎)近期,人工智能图像生成的潜力展示出了令人震撼的成果。只需从简洁的文字描述出发,就能如同魔法般生成出高质量图片。这无疑极大地拓展了人类运用艺术创作的可能性。在此背景下,Stable Diffusion的发布无疑是一个具有标志性的时刻。其开源性不仅让大众群众得以接触到一项极高质量的模型,更重要的是,该模型还能保持高速的运算速度以及较低的显存需求,展现了其强大的性能。
在尝试过Diffusion技术之后,你或许会对它的出色表现感到好奇,想要了解其背后的原理。接下来,我们将用简洁明了的语言为你揭示这个神秘技术的奥秘。
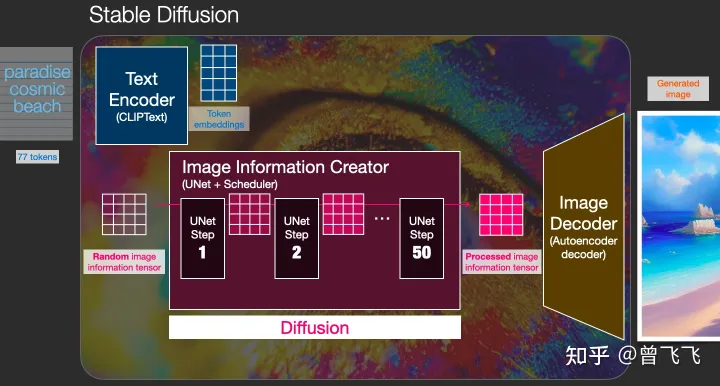
Stable Diffusion模型展现出了极高的灵活性,能够应对多种任务,包括但不限于文本到图像的生成、图像到图像的生成、特定角色的塑造,以及超分辨率处理和图像修复等。然而,作为对该模型最基础、最入门的介绍,我们将重点放在其最核心的“文本到图像”生成模块,也就是txt2img部分。如下图所示,这是一个典型的文生图展示,输入条件为“天堂(paradise)”、“广袤的(cosmic)”和“海滩(beach/)”,我们可以看到,生成的图像完美地符合了这些输入条件。画中不仅展现了湛蓝的天空和洁白的云朵,还有一望无际的广阔海滩:

在本篇文章中,尽管我们尚未深入探讨图生图模块(亦称img2img),但我们仍需对其进行简要概述。此模块的示意图暂未呈现,如下所示。在本例中,输入信息由单一的文字转变为包含图片与文字的复合形式。生成的成果受原始图片及文字提示词的共同影响。具体输入为“海盗船(pirate ship)”,而最终输出的结果成功地使原本的帆船变形为海盗船。

现在,让我们正式开始了解这项技术背后的原理吧。
一、组成模块
Stable Diffusion系统实际上是一个相对复杂的体系,其中包含了众多不同的模型模块。首要解决的问题在于如何将人类所理解的自然语言文本转化为机器可解读的数学语言,因为计算机并不具备处理英语的能力。为此,我们需要一个名为text understander的辅助工具来完成这个任务。在生成图像之前,图示中的蓝色text understander会先将文字信息转换为计算机能够理解和处理的数学形式:

我们后续在第三篇中会讲到这个text understander到底是怎么理解文字和怎么训练的,但现在暂时让我略过这一部分内容,我们只要知道这个text understander是个特别的Transformer语言模型就好了。它的输入是人类语言,输出是一系列的向量,这些向量的语义对应着我们输入的文字。
那么现在,有了可以代表语义的向量(就比如下面的蓝色3*5方格),我们就把这个语义向量交给真正的图片生成器了,也即下图中粉粉的Image Generator。

这个粉色的图片生成器(Image Generator)可以分解成两个子模块来看
1,图片信息生成器
这个下图中粉色的模块是Stable Diffusion的秘密武器,也是Stable Diffusion和其他diffusion模型最大的区别,很多性能上的提升就来源于此。
首先,最需要明确的一点:图片信息生成器不直接生成图片,而是生成的较低维度的图片信息,也就是所谓的隐空间信息(information of latent space)。这个隐空间信息在下面的流程图中表现为那个粉色的4*3的方格,后续再将下图中这个隐空间信息输入到下图中黄色的Decoder里,就可以成功生成图片了。Stable Diffusion主要引用的论文“latent diffusion”中的latent也是来源于隐变量中的“隐”(latent)。
一般的diffusion模型都是直接生成图片,并不会有先生成隐变量的过程,所以普通的diffusion在这一步上需要生成的信息更多,负荷也更大。因而之前的diffusion模型在速度上和资源利用上都比不过Stable Diffusion。那技术上来说,这个图片隐变量到底是怎么生成的呢?这其实是由一个Unet和一个Schedule算法共同完成的。schedule算法控制生成的进度,unet就具体去一步一步地执行生成的过程。Stable Diffusion中,整个unet的生成迭代过程大概要重复50~100次,隐变量的质量也在这个迭代的过程中不断的变得更好。下图中粉色的Image Information Creator左下角的循环标志也正是象征着这个迭代的过程。

2,图片解码器
图片解码器也就是我们上面说的decoder,它从图片信息生成器(Image Information Creator)中接过图片信息的隐变量,将其升维放大(upscale),还原成一张完整的图片。图片解码器只在最后的阶段起作用,也是我们真正能获得一张图片的最终过程。

上面粗略的聊了一下Stable Diffusion每个模块的功能,下面我们来更具体的了解一下这个系统中输入输出的向量形状,这样的话对Stable Diffusion的工作原理应该能有更直观的认识:
Text Encoder (蓝色模块) 功能:将人类语言转换成机器能理解的数学向量 输入:人类语言 输出:语义向量(77,768)Image Information Creator (粉色模块) 功能:结合语义向量,从纯噪声开始逐步去除噪声,生成图片信息隐变量 输入:噪声隐变量(4,64,64)+语义向量(77,768) 输出:去噪的隐变量(4,64,64)Image Decoder 功能:将图片信息隐变量转换为一张真正的图片。 输入:去噪的隐变量(4,64,64) 输出:一张真正的图片(3,512,512)大概流程中的向量形状变化就是这样,至于语义向量的形状为什么是奇怪的(77,768)的形状,我们后面讲到Text Encoder里面的CLIP模型的时候还会讲到,这里就暂且按下不表。
二、扩散(Diffusion)到底是什么意思?
Diffusion模型,翻译成中文也就是扩散模型,那这个扩散到底体现在什么地方呢?这就是我们这第二部分着重要描述的过程。首先我们先用random函数生成一个隐变量大小的纯噪声【下图中左下透明4*4】。而扩散的过程发生在Image Information Creator中,有了初始的纯噪声【下图中左下透明4*4】+语义向量【下图左上蓝色3*5】后,unet会结合语义向量不断的去除纯噪声隐变量中的噪声,重复50~100次左右就完全去除了噪声,同时不断的向隐变量中注入语义信息,我们就得到了一个有语义的隐变量【下图粉色4*4】。 别忘了我们还有一个scheduler,它就用来控制unet去噪的强度,以统筹整个去噪的过程。scheduler可以在去噪的不同阶段中动态地调整去噪强度,也可以在某些特殊的任务里,匀速地去除噪声,这都取决于我们一开始的设计。

这个扩散过程是一步一步迭代去噪的,每一步都向隐变量中注入语义信息,不断重复直到去噪完成为止。为了有个直观的认识,我们可以把初始的纯噪声【下图左上透明4*4】和最后的去噪隐变量【下图右上粉色4*4】都通过最后的Image Decoder,看看会出来什么样的图片。不出意料,纯噪声本身没有任何有效信息,解码出来的图片也会是纯噪声,如下图左侧所示。而最后的去噪隐变量由于已经耦合了语义信息,因此最后解码出来的也是一张包含语义信息的有效图片,如下图右侧图片所示。

刚才我们也提到过,扩散过程是一个多次迭代的过程。每一步迭代的输入都是一个隐变量,输出也是一个隐变量,只不过输出的这个隐变量噪声更少,并且语义信息更多。下图中4*4的隐变量不断从透明变粉的过程就代表了这个迭代的过程,颜色越粉,迭代次数越多,噪声也就越少。
这个时候我们再偷偷用Image Decoder提前看一下每一步所对应的图片,就会看到我们想要的图片一步一步地脱胎于噪声的全过程:

这是一个神奇的过程,下面的视频展示了迭代去噪的全过程,我们可以看一下视频的展示:
 0
0三、总结
至此,我们已经了解了Stable Diffusion是什么,以及其中的种种模块是什么,甚至还简单的窥视了一下它的工作过程。至于为什么Diffusion如何训练、如何控制,鉴于篇幅原因,就容我放到后文中再去细讲了。这里最后再简单做一下总结:
第一部分介绍了一些Stable Diffusion中的主要模块——包括一个Text Understander处理语义信息,一个Image Information Creator生成图片的隐变量,一个Image Decoder利用隐变量生成真正的图片。其次还介绍了一下Diffusion生成图片的流程——包括向量形状在系统中经历的一系列变化,以及各个阶段图片隐变量解码后的可视化。下篇文章可以点击这里阅读~
最后的最后,码字不易,喜欢的话可以点个赞或者收藏,作者会很开心的。后续作者也会更新更多关于深度学习领域的内容,感兴趣的话也可以关注一下哦~

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!


