
文章主题:AI, 大模型, 搜索增强, 知识库
自 ChatGPT 引领全球 AI 热潮以来,AI 领域已迅速跨过制造通用大模型的第一个重要里程碑。当前,最为关键的问题在于如何使这些大型模型在实际应用场景中实现高效的落地应用?
百川智能的最新实践是:用大模型+增强技术,可以大大提升企业应用大模型的效率。
全球大模型研究领域正逐步进入“开卷”长文本阶段,这将是决定大型模型能否在更多场景中落地的关键所在。百川公司于去年10月推出了最新款长窗口模型Baichuan2-192k,其能力涵盖了约35万个汉字,这一数字是OpenAI旗下GPT-4的14倍,更是Anthropic旗下Claude2大模型的4.4倍。
在12月19日,我国知名科技公司百川智能正式推出了基于搜索优化的Baichuan2-Turbo系列API,其中包括Baichuan2-Turbo-192K和Baichuan2-Turbo两个版本。这一举措展示了百川智能在人工智能领域的技术创新和实力,进一步提升了我国AI技术的应用水平和全球竞争力。
目前,我国知名的人工智能公司百川智能已经对其官网模型进行了升级。这一更新为企业用户提供了更为便捷的文本上传方式,允许他们在API接口中上传PDF、Word等不同类型的文件,同时也可以通过URL地址进行上传。随着这次升级,用户将能够享受到搜索增强和长窗口功能带来的更优质服务。百川2大模型的推出,标志着我国人工智能技术的进一步发展和提升。
给大模型“外挂硬盘”,秒建公司知识库
作为一家技术领先的公司,百川智能将大模型视为新时代计算机的代表,其重要性类似于中央处理器。与此同时,上下文窗口可被视为计算机的内存,负责存储当前正在处理的信息。而在大模型时代,互联网实时信息和企业的完整知识库共同构建了硬盘,提供了丰富的数据资源。这样的组合不仅使得计算过程更加高效,还为企业提供了更全面、精准的数据支持。
而基于搜索增强技术推出的API系列,用百川智能CEO王小川的话来说:
“就像硬盘一样,让大模型可以挂上外部知识库。”
在AI时代,大模型已经成为基础设施底座这一观点已得到广泛认同。然而,虽然模型参数不断增大,但大模型的技术探索仍处于初级阶段。此外,诸如“胡说八道”的幻觉问题和“记不住上一句问了什么”的对话窗口问题等,均对大模型效能的发挥产生了巨大影响。
但是,基于大模型+搜索增强这一路线之后,大模型的可用性可以有效提升——想要让大模型记得上一回合讲了什么,不需要通过扩大参数、使用更多算力来重读文本。“长窗口本身越大,它的性能会越低。因此如何用更好的搜索降低长窗口的负担,这个也是长窗口搜索要做好的工作。”王小川表示。
现在,哪怕基于参数没那么大的模型,模型单次获取的文本量级大大提高,并且速度也能大大提升。
Baichuan-192k API效果到底如何?百川智能展示了长文本领域的经典测试“大海捞针”的结果:
“大海捞针”测试(Needle in the Heystack)是由海外知名AI创业者兼开发者Greg Kamradt设计的,业内公认最权威的大模型长文本准确度测试方法。
简单而言,这一测试是将一段信息放在一段长文本中的任意位置,检测大模型的回答准确率如何。
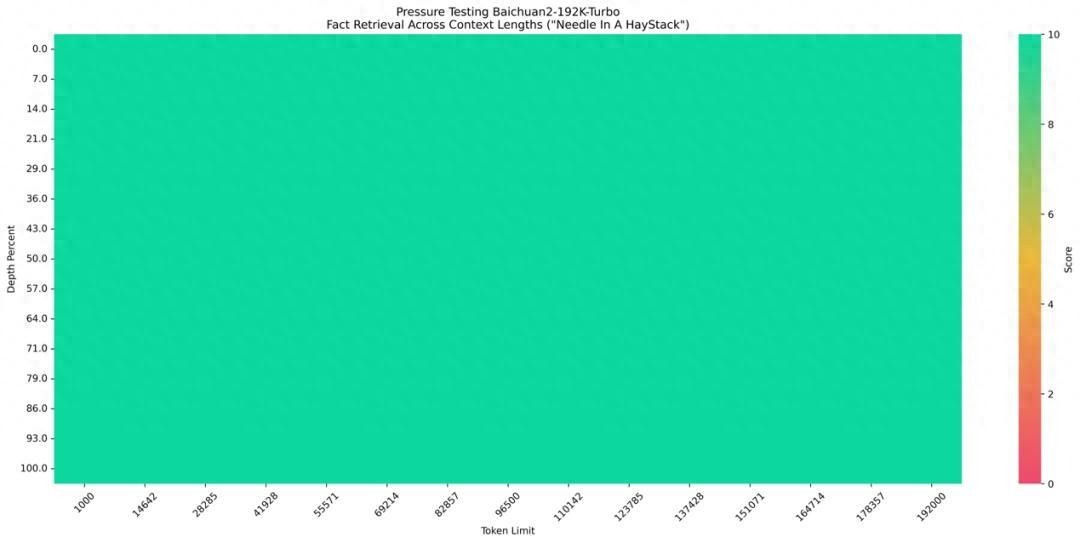
△“大海捞针”压力测试图
目前,对于192k token以内的请求,百川智能可以实现100%回答精度。“我们的长窗口能够做到全绿,相当于能完全不遗漏地把192k里的信息全部召回。”王小川表示。
并且,结合搜索系统,Baichuan-2能够获取的原本文本规模提升了两个数量级,达到5000万tokens,相当于35万汉字的规模。
百川智能分别测评了纯向量检索和稀疏检索+向量检索的检索的效果。测试结果显示,稀疏检索+向量检索的方式可以实现95%的回答精度。在文本总量提升大概250倍的情况下,其召回精度可达95%。
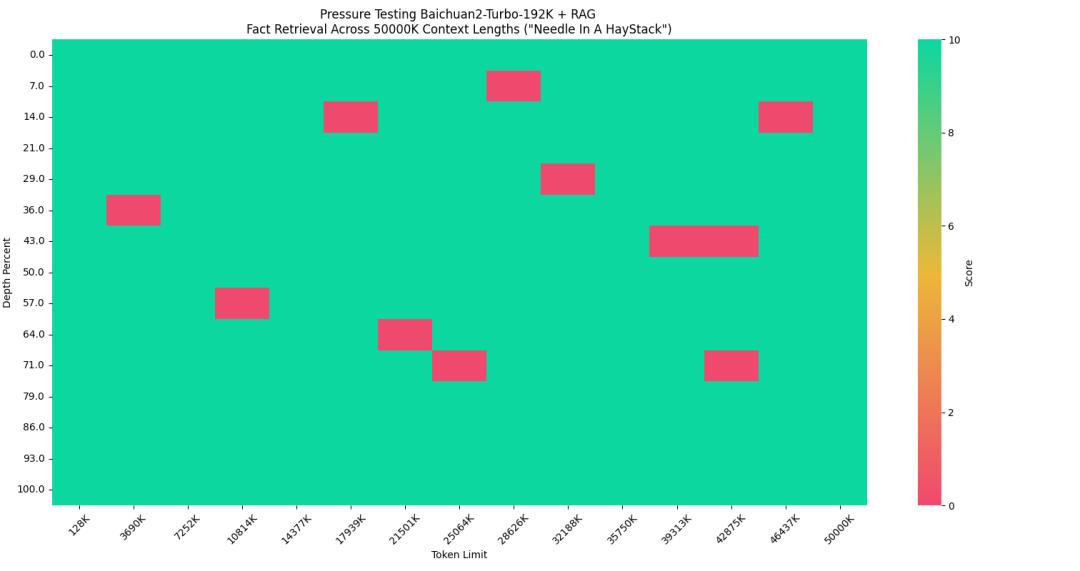
△在中文场景下的长文本测试
本次测试,百川智能使用中文场景,实验配置如下:
大海(HayStack):博金大模型挑战赛-金融数据集中的80份长金融文档。
针(Needle):2023 年 12 月 16 日,在极客公园创新大会 2024 的现场,王小川进一步分享了大模型的新思考。在王小川看来,大模型带来的新的开发范式下,产品经理的出发点,应该从思考产品市场匹配(PMF),到思考技术与产品的匹配怎么做,即 TPF(Technology Product Fit,技术产品匹配)。
查询问题:王小川认为大模型时代下,产品经理的出发点是什么?
总而言之,这次的发布相当于让大模型的运行速度和精度都再进一步。大模型即使再加长窗口,也能做到数据更新、更快、更准、更全的召回,还能够远远比做行业模型的成本要低。
大模型做定制,不等于项目化
除了新的API系列外,本次发布中,百川也发布了另一项功能:百川搜索增强知识库。使用过程也很简单:企业从私有化部署到云端把自己的知识上传到其中,即可生成一个一个外挂的系统,跟Baichuan2系统对接——相当于每个企业可以定制自己的硬盘,做到即插即用。
API和增强知识库的推出,最直观的落地效果是,模型比原先长窗口处理速度更快,成本更低。
如今的Baichuan-2能够拓展到大量To B场景当中,例如金融、政务、司法、教育等行业的智能客服、知识问答、合规风控、营销顾问等场景。
在发布会现场,百川也展示了金融行业的知识库搜索场景。某银行的知识库总量有6T,共12905个文档,Baichuan2能够海量的知识库可以查找找到文档里的内容。将36万字的文档通过API输入到模型中,就能精确找到答案。
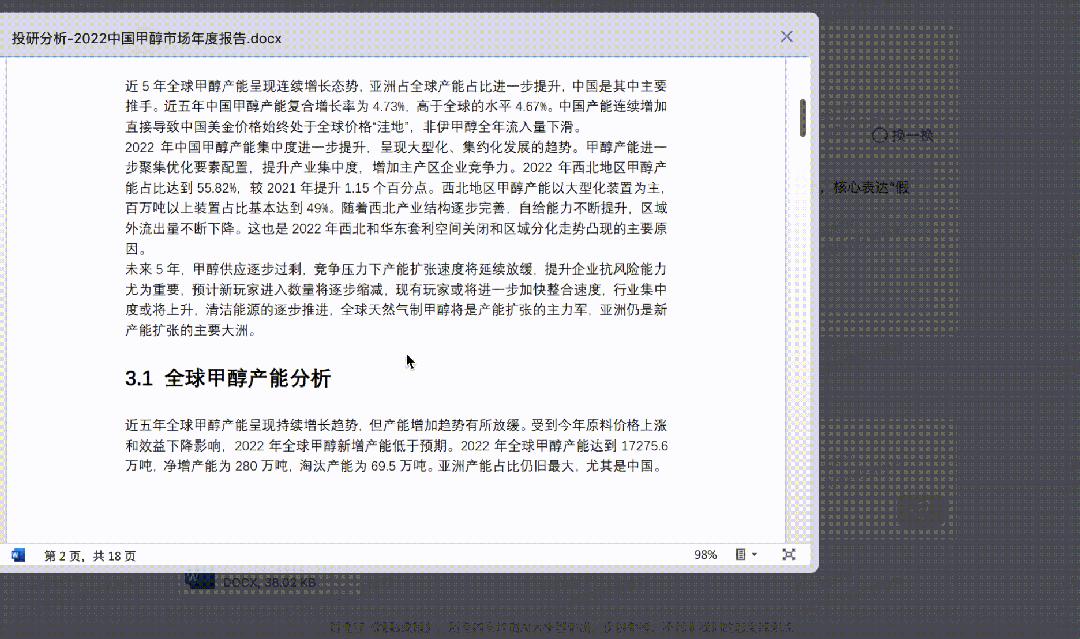
△百川现场展示投研信息提取和分析
可以说,大模型+搜索增强的方法,为以后大模型在行业落地提供了一条务实的路径。
企业知识库是现在大模型应用的主流场景。在以前,企业想要建一个企业知识库,需要通过预训练或者微调训练大模型,也需要比较高素质的AI人才。当底层的大模型数据每更新一次,都要重新训练或微调,成本也较为昂贵,且可控性和稳定性也很容易下降。
另外一点是,构建大模型知识库的主流方法是向量检索,但向量数据库应用成本也相对高昂,而向量模型的效果过于依赖训练数据的覆盖。在训练数据未覆盖的领域泛化能力会有明显折扣。用户Prompt和知识库中文档长度的差距,也会给向量检索带来了很大挑战。
针对这些问题,在推出大模型+搜索增强的过程中,百川智能也解决了一些技术难题,比如在通用RAG(检索增强生成)的技术基础上首创了Self-Critique大模型自省技术——以让大模型在输出答案之前“再自检”,给用户筛选出最优质的答案。
最终结果是,将搜索增强知识库和超长上下文窗口结合后,模型“接上外挂”,就可以连接全部企业知识库以及全网信息。可以替代绝大部分的企业个性化微调,解决99%企业知识库的定制化需求——企业要做定制化,成本可以大大降低。
王小川坦承,目前大模型在行业化中落地,客制化(Customized)是无法避免的,但可以通过技术的迭代,不断降低给客户交付的能力。“我们避免项目化,用产品化取代项目化。”他解释。
随着新模型和API系列发布,目前百川智能也正在快速推进商业化落地。百川智能透露,目前多个行业的头部企业已与百川智能达成合作。
欢迎交流
欢迎交流

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!


