文章主题:
blog地址:https://github.com/QwenLM/Qwen-7B/blob/main/tech_memo.md 北方的郎:通义千问开源大模型Qwen-7B技术报告
code地址:https://github.com/QwenLM/Qwen-7B https://github.com/QwenLM/Qwen-7B/blob/main/README_CN.md https://github.com/Dao-AILab/flash-attention
模型下载Hugging Face:Qwen/Qwen-7B · Hugging Face https://huggingface.co/Qwen/Qwen-7B-Chat
魔搭展示ModelScope:直接在modelscope平台使用Qwen-7B-Chat模型创空间链接::Qwen-7B-Chat-Demo==https://modelscope.cn/studios/qwen/Qwen-7B-Chat-Demo/summary
魔搭ModelScope: https://modelscope.cn/models/qwen/Qwen-7B/summary—-https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary
魔搭modelscope: https://github.com/modelscope/m 视频:阿里云宣布开源通义千问70亿参数大模型,将对国内大模型行业产生哪些影响?
无需环境配置-阿里通义千问-7B-Chat本地一键体验无需环境配置,通义千问-7B-Chat本地一键体验—- DragGAN Windows离线整合包B站介绍:https://www.bilibili.com/video/BV1fP411v77Y—-https://github.com/search?q=DragGAN&type=repositories—-基于https://github.com/XingangPan/DragGAN####GitHub – zhaoyun0071/DragGAN-Windows-GUI—-软件下载方式(仅支持Windows 10、Windows 11) (1)百度网盘链接:https://pan.baidu.com/s/1AIVBa6FLu1IH0Saxs7mHMg 提取码:qba7 (2)天翼网盘链接:https://cloud.189.cn/t/u6r2EnJR3qMn (访问码:iv5c) (3)夸克网盘链接:https://pan.quark.cn/s/273be7b9add4 提取码:yrCu
0 介绍优势
🌟【阿里云】超大规模🔥70亿参数通义千问-Qwen-7B,Transformer技术驱动的語言巨擘!💡🔍在海量数据海洋中砥砺成长,Qwen-7B通过精细化的预训练,汲取网络文本、专业书籍与代码等多元智慧。📚💻🌈不止于此,我们创新性地引入对齐算法,将大模型与AI助手完美融合,铸就了Qwen-7B-Chat,为用户提供更自然流畅的交互体验。💬🔍这款模型系列以其卓越性能和广泛适用性,展现了阿里云在人工智能领域的深厚实力和前瞻性思考。🌟🚀欲了解更多技术细节或寻求合作机会,请访问我们的官方网站,让AI的力量引领你的创新之路!🌐💻
🌟🚀超大规模训练素材,2.2万亿tokens的宝藏!🔥我们凭借自家专属的大规模预训练数据集,为语言模型铺就了卓越之路。💡数据丰富多元,文本与代码交织,覆盖广泛且专业——通用领域与深度专长一网打尽!🌍中英多语齐飞,代码数学样样精通,打造全面的语言学习环境。每一片言语的海洋,都经过精心筛选和优化,确保预训练语料分布均匀,每一句都能反映出语言的力量。🔍实验严谨,对比充分,只为提供最优质的训练基础。让我们的模型在海量信息中游刃有余,无论是学术研究还是实际应用,都能展现出顶尖性能。💪SEO友好,提升搜索引擎可见度,让优质内容触达更多读者。🏆你的信任,我们的承诺,一起见证语言的力量!🌟
🌟【Qwen-7B:卓越性能的超大规模模型】🌟💡 独特优势,超越想象!在众多基准测试中,Qwen-7B以其卓越的性能展现出压倒性的实力,相较于同等规模的开源模型,它犹如鹤立鸡群,遥遥领先。无论是在自然语言处理的复杂领域,如理解与生成,还是在严谨的数学运算和代码生成任务上,Qwen-7B都展现出了强大的计算智慧。🔍 不仅如此,这款超大规模的语言巨人还具备广泛的能力覆盖,从常识推理到多语种翻译,无一不显示出其全面且精准的技能。它的卓越表现,甚至超越了12-13B这样的大模型,为AI技术的发展树立了新的标杆。🏆 这份出色的成绩单,不仅证明了Qwen-7B在模型性能上的优越性,也预示着未来更多可能。欲了解更多关于这款革命性模型的深度解析和应用实例,请随时关注我们的平台,让Qwen-7B引领你的知识探索之旅!
🌟改进多语言支持:升级的分词器🚀,基于更大规模词汇库,提供更流畅且跨语言友好的表现。轻松训练Qwen-7B基础上特定的7B模型langs,满足多语种需求。🌍 Além that, Qwen-7B的独特之处在于它庞大的15万词汇集🔍,这不仅扩展了语言覆盖范围,还降低了对额外词表调整的需求。无需扩充,用户可便捷增强或扩展非中文英以外的语言能力。让全球交流更无缝!🌐
🌟掌握超高清叙事,只需一步!🔍Qwen-7B与Qwen-7B-Chat现已火力全开,以无与伦比的8K处理能力,引领对话新高度!📝不论是科幻想象、历史揭秘,还是日常闲聊,用户都能尽情输入长篇prompt,释放无限创意!🌍无论是探索浩瀚宇宙,还是追溯人类文明,只需轻轻一问,就能获得深度且丰富的回应。极简主义的现代生活方式
🌟🚀提升沟通效率!🔥专为插件开发者打造的神器来了!我们的Qwen-7B-Chat不仅火力全开,支持5种灵活调用,而且在对齐数据上独树一帜,确保每个插件都能无缝对接,轻松升级为高效能的Agent。🚀💪无论你是寻求智能化集成的专家,还是希望提升用户体验的魔法师,Qwen-7B-Chat都是你信赖的伙伴,它以强大的技术支持和卓越的兼容性,让你的创新想法瞬间落地。🌍💻欲了解更多插件调用细节,敬请关注我们,让技术与智慧碰撞出火花!🔥💡记得优化你的SEO关键词哦,比如”Qwen-7B-Chat插件调用”, “数据对齐优化”, “Agent升级”. 📈🔍
1 模型结构-基本信息
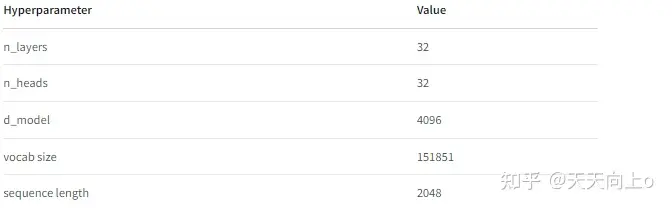
QWen-7B是基于Transformer的预训练语言模型, Qwen-7B结构与LLaMA相似的架构。使用来自公开的超过 2.2 万亿个tokens的数据和 2048 个上下文长度进行预训练,训练数据覆盖一般和专业领域,在语言方面重点关注英语和中文。 与标准transformer的主要区别如下:1)使用untied embedding嵌入;2)使用旋转位置嵌入-即RoPE相对位置编码;3)normalization实现–即RMSNorm代替LayerNorm;4)FFN激活函数-即SwiGLU代替 ReLU;5)attention中除QKV外无bias–采用flash attention加速训练;。。。。该模型有 32 层,嵌入维度为 4096,注意力头数为 32。
#
Qwen-7B-Chat通过对齐机制微调以符合人类意图,包括面向任务的数据,以及特定的以安全和服务为目标的数据。
2 数据
Pretraining data:预训练数据包括来自公开来源的混合数据,主要由网络文档和代码文件组成。此外,这些数据是多语种的,其中大部分是英文和中文。我们努力并采用了一系列模型-以排除低质量或不适合预训练的数据-如 NSFW 内容,最终数据经过了全局模糊重复数据删除。通过多次消减实验我们优化了预训练语料的组合。一方面利用了部分开源通用语料, 另一方面也积累了海量全网语料以及高质量文本内容,去重及过滤后的语料超过2.2T tokens。 囊括全网文本、百科、书籍、代码、数学及各个领域垂类。
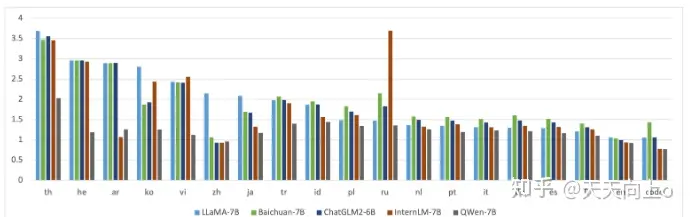
Tokenization:与目前主流的基于中英文词库的开放模型相比,我们使用了 151,851 个词库。它首先考虑了中、英、code数据的高效编码,同时对多语言也更加友好,用户可以在不扩充词汇量的情况下直接增强某些语言的能力。它按个位数分割数字,并调用 tiktoken tokenizer 库进行高效的标记化。tokenize后的数据超过 2.2 万亿个token。—-我们随机选取了每种语言的100万文档语料库来测试和比较不同模型的编码压缩率(以支持 100 种语言的 XLM-R 为基值 1,图中未显示)。可以看出Qwen-7B在确保对中文、英文和代码进行高效解码的同时,还对其他多种语言(如 th、he、ar、ko、vi、ja、tr、id、pl、ru、nl、pt、it、de、es、fr 等)实现了较高的压缩率,使模型在这些语言中具有较强的可扩展性以及较高的训练和推理效率。
在分词器方面,相比目前主流开源模型以中英词表为主,Qwen-7B使用了超过15万token大小的词表。 该词表在GPT-4使用的BPE词表cl100k_base基础上,对中文、多语言进行了优化,在对中、英、代码数据的高效编解码的基础上,对部分多语言更加友好,方便用户在不扩展词表的情况下对部分语种进行能力增强。 词表对数字按单个数字位切分。调用较为高效的tiktoken分词库进行分词。—-从部分语种各随机抽取100万个文档语料,以对比不同模型的编码压缩率(以支持100语种的XLM-R为基准值1,越低越好)。可以看到Qwen-7B在保持中英代码高效解码的前提下,对部分使用人群较多的语种(泰语th、希伯来语he、阿拉伯语ar、韩语ko、越南语vi、日语ja、土耳其语tr、印尼语id、波兰语pl、俄语ru、荷兰语nl、葡萄牙语pt、意大利语it、德语de、西班牙语es、法语fr等)上也实现了较高的压缩率,使得模型在这些语种上也具备较强的可扩展性和较高的训练和推理效率。
3 模型训练细节
使用AdamW优化器训练模型, β1=0.9,β2=0.95,ϵ=10−6\beta_1=0.9,\beta_2 = 0.95,\epsilon=10^{-6}
,,,,序列长度为2048,批大小batch_size是2048,意味着每次优化步骤累积超过400万个tokens。采用余弦学习率scheduler,预热2000步,峰值学习率为3e-4,及峰值学习率的10%的最小学习率-最小值为峰值的10%,使用0.1的权重衰减和1.0的梯度裁剪参数。训练采用bfloat16混合精度训练。
4 模型评估
Qwen-7B在多个全面评估自然语言理解与生成、数学运算解题、代码生成等能力的评测数据集上,包括MMLU、C-Eval、GSM8K、HumanEval、WMT22等,均超出了同规模大语言模型的表现,甚至超出了如12-13B参数等更大规模的语言模型。提示:由于硬件和框架造成的舍入误差,复现结果如有波动属于正常现象。。
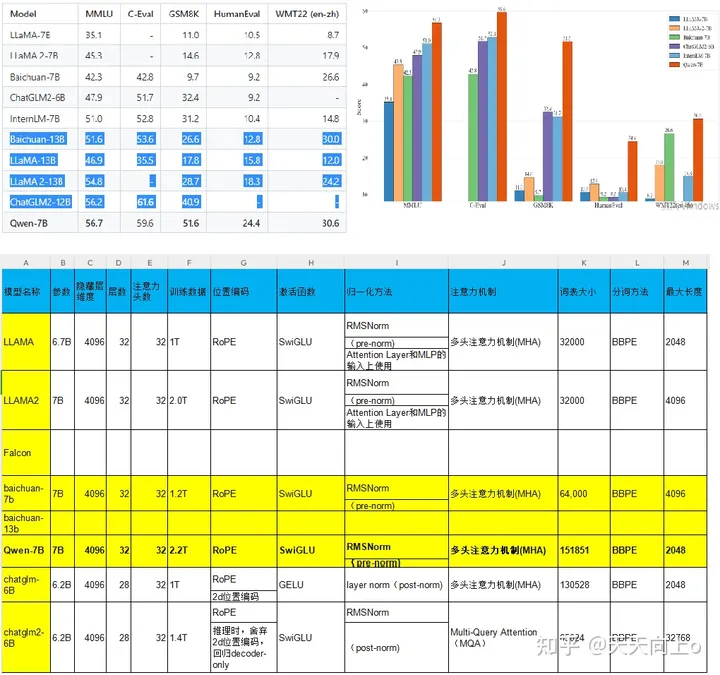
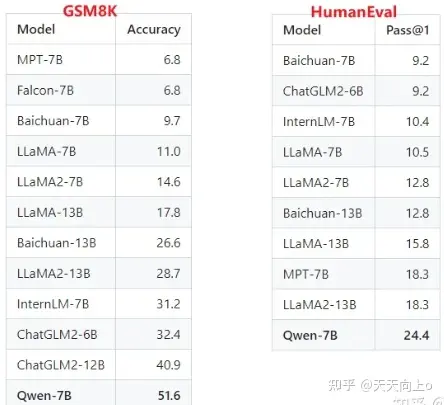
对于数学能力和代码能力,也分别在GSM8K和HumanEval数据集上做了评估。效果分别如下:
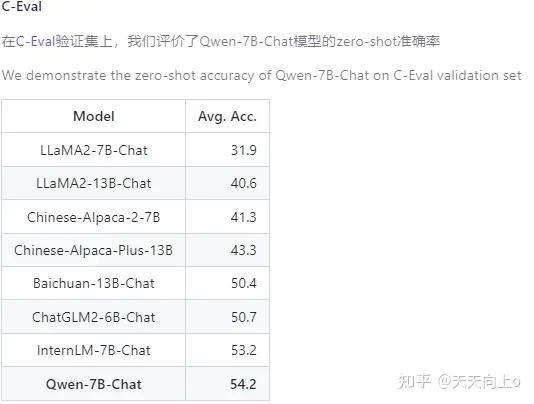
Qwen-7B-Chat
长文本理解评测(Long-Context Understanding)
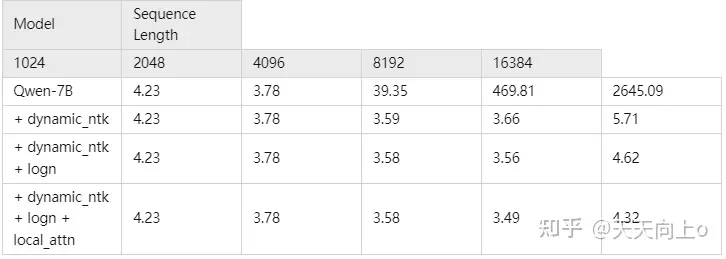
我们引入了NTK插值、窗口注意力、LogN注意力缩放 等技术来提升模型的上下文长度并突破训练序列长度的限制,将模型的上下文长度扩展到8K以上。。通过arXiv数据集上使用PPL指标测试的语言模型实验,我们发现Qwen-7B能够在长序列的设置下取得不错的表现。(若要启用NTK和LogN注意力缩放,请将config.json里的use_dynamc_ntk和use_logn_attn设置为true)
在长文本摘要数据集VCSUM上(文本平均长度在15K左右),Qwen-7B-Chat的Rouge-L结果如下:

编码
Qwen-7B-Chat在HumanEval上的zero-shot Pass@1如下所示。
ModelPass@1LLaMA2-7B-Chat12.2InternLM-7B-Chat14.0Baichuan-13B-Chat16.5LLaMA2-13B-Chat18.9Qwen-7B-Chat21.35 快速使用
在开始前,请确保你已经配置好环境并安装好相关的代码包。最重要的是,确保你的pytorch版本高于1.12,然后安装相关的依赖库-执行以下pip命令安装依赖库。
我们还推荐安装flash-attention来提高你的运行效率以及降低显存占用。以实现更高的效率和更低的显存占用。
使用Qwen-7B进行推理
使用Qwen-7B-chat进行推理
量化(Quantization)
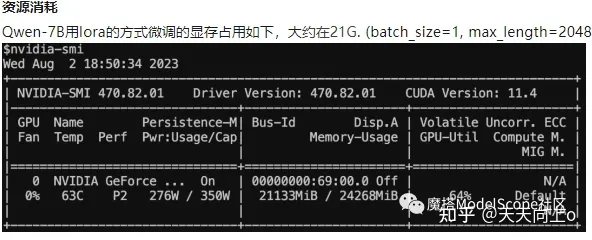
QWen-7B模型默认精度是bfloat16,这种情况下显存开销是16.2G。同时官方提供了更低精度的量化模型Int8和NF4,按照上述两种精度量化后,模型的现存开销分别是10.1G和7.4G。当然量化意味着模型效果的损失。可以让我们将模型量化成NF4和Int8精度的模型进行读取,帮助我们节省显存开销。我们也提供了相关性能数据。我们发现尽管模型在效果上存在损失,但模型的显存开销大幅降低。
在开始前,确保你已经安装了bitsandbytes。你只需要在AutoModelForCausalLM.from_pretrained中添加你的量化配置,即可使用量化模型。
PrecisionMMLUMemoryBF1656.716.2GInt852.810.1GNF448.97.4G插件调用 工具调用Tool Usage外部系统集成-能力的评测–LLM在协调多个外部系统以实现给定指令方面展示了能力,这为传统在线服务带来了新机遇,最引人注目的是网络搜索。
Qwen-7B-Chat经过针对API、数据库、模型等工具的优化,使得用户可以开发基于Qwen-7B的LangChain、Agent甚至Code Interpreter等应用。在即将开源的内部评测数据集上测试了Qwen-7B-Chat的工具调用能力,发现其表现稳定可靠。

自己部署的Qwen-7B-Chat,可以支持通过ReAct Prompting调用插件/工具/API,这样模型能完成更复杂和特定的任务。比如可以通过调用插件使用夸克搜索和文生图等功能。具体实现方法可以参考这里。。–ReAct也是 LangChain框架采用的主要方式之一。在即将开源的、用于评估工具使用能力的自建评测基准上,千问的表现如上:关于ReAct Prompting的prompt提示怎么写、怎么使用,请参考ReAct 样例说明。使用工具能使模型更好地完成任务。
Huggingface Agent
此外,实验结果还显示了模型在扮演Agent角色方面的能力,具备作为 HuggingFace Agent 的能力。有关更多信息,请查阅相关文档链接。在Hugging Face提供的run模式评测基准数据集上,在工具选择、工具使用和代码方面表现如下:
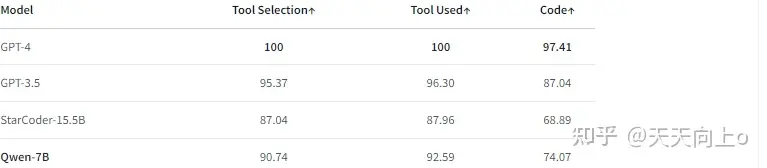
评测复现(Reproduction)
我们提供了评测脚本以供复现我们的实验结果,详见链接。注意,由于内部代码和开源代码存在少许差异,评测结果可能与汇报结果存在细微的结果不一致。请阅读eval/EVALUATION.md了解更多信息。由于硬件和框架造成的舍入误差,复现结果如有小幅波动属于正常现象。
####
6 微调finetune
通义千问7B模型开源,魔搭最佳实践来了—-ModelScope小助理:通义千问7B模型开源,魔搭最佳实践来了
红雨瓢泼:通义千问Qwen-7B效果如何?Firefly微调实践,效果出色
#
参考文献:
阿里云通义千问开源!70亿参数模型上线魔搭社区,免费可商用_央广网
阿里云宣布开源通义千问70亿参数大模型,将对国内大模型行业产生哪些影响?
#
莫笑傅立叶:[LLM] QWen-7b 通义千问开源啦 莫笑傅立叶:[LLM结构对比] Llama/Llama2/ChatGLM/ChatGLM2/Baichuan/QWen
#

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!