去年 ChatGPT 一声枪响,在全球范围内点燃了 AI 热潮,自此国内 AI 百模大战已持续了 5 个多月,期间众多大厂也都相继发布了自家的通用大模型产品。
在这场声势浩大、愈演愈烈的百模大战中,期间不少人都在问:腾讯的混元大模型呢?
今年 2 月初,业界有传言称腾讯在研发类 ChatGPT 对话式产品,成立了混元助手项目组,对此腾讯回应道:“在相关方向上已有布局”;在 5 月的一季度财报会议上,腾讯总裁刘炽平再次透露,“混元模型构建进展顺利”。但此后,便鲜有腾讯混元大模型的相关消息。
在如今这个入局者越来越多、行业却渐入冷静期的时间点,腾讯混元大模型终于“现身”了!
在 9 月 7 号举行的 2023 年腾讯全球数字生态大会上,腾讯集团高级执行副总裁、云与智慧产业事业群 CEO 汤道生激动表示:“今天我们非常高兴地告诉大家,腾讯自主研发的通用大语言模型——腾讯混元大模型,正式面向产业亮相!”


主打一个“更可靠、更成熟”!
在正式介绍混元大模型前,腾讯集团副总裁蒋杰提出了一个问题:“训练烧钱、百模大战,在投入大模型时我们在期待什么?”而这个问题的答案,正是这个拥有超千亿参数规模、预训练语料超 2 万亿 tokens 的混元大模型的最大特点——“更可靠、更成熟”。
更可靠
(1)降低大语言模型的幻觉比例
所谓“幻觉”,是指在生成式 AI 发展过程中,AI 模型生成了不属于现实世界的内容,即捏造了虚假信息,而这也是目前几乎所有大模型都无法避免的问题。对此,当前业界普遍的解决方式是采用外挂插件,即给大模型“外挂”一个知识库,使其在推理时进行检索,基于检索结果再进行输出,提高正确率。
但这个方式有一个明显缺点:一旦遇到复杂任务,幻觉问题依旧无法解决。为此,腾讯选择不让混元大模型依赖外挂来解决幻觉问题,而是在预训练阶段就通过“探真”算法进行事实修正,降低了复杂任务中的幻觉。
经过预训练算法及策略的整体优化后,蒋杰表示相比其他主流开源大模型,目前混元大模型的幻觉比例降低了 30%-50%。

(2)让大语言模型识别“陷阱”,抗拒“诱导”
作为一款通用大模型,面对各种诱导提问时总是防不胜防,就在今年 7 月 ChatGPT 还出现了一个“奶奶漏洞”。对此,腾讯通过强化学习的方法,让混元大模型学会识别陷阱问题,对难以回答或不应回答的问题说“不”,提升应用安全性和智能感,由此混元大模型面对安全诱导类问题的拒答率已提升了 20%。

更成熟
(1)多种场景下处理超长文本
目前业界的大语言模型,长文生成内容普遍偏短,还容易发生截断。针对这个问题,腾讯通过位置编码优化,提升长文的处理效果和性能,并结合指令跟随优化,让产出内容更符合字数要求,由此极大提升了混元大模型的生成超长文本和续写能力。

(2)显著提高模型在场景中的逻辑思维能力
在逻辑思维上,众多大模型的高频应用多是基于常识的推理;而腾讯提出思维链的新策略,有效强化了模型对问题拆解和分步思考的倾向,不仅能结合实际场景推理决策,还能让应用助手拥有像人一样思维推理。

基于以上,正如腾讯自己所说:“腾讯混元大模型不仅具有强大的中文理解与创作能力,还拥有逻辑推理能力以及可靠的任务执行能力。”
值得一提的是,在中国信通院《大规模预训练模型技术和应用的评估方法》的标准符合性测试中,混元大模型共测评了 66 个能力项,在“模型开发”和“模型能力”这两个重要领域的综合评价中,均获得了当前的最高分:
模型开发:共测 29 个能力项,综合评级 4+ 级,当前最高分。
模型能力:共测试 37 个能力项,综合评级 4+ 级,当前最高分。
蒋杰表示:“我们研发大模型的目标不是在评测上获得高分,而是将技术应用到实际场景中,腾讯将全面拥抱大模型。”


全链路自研下,更为“实用” 的混元
这样一个大模型的背后,蒋杰透露:“腾讯混元大模型是从第一个 token 开始从零训练的。”从模型算法到机器学习框架,再到 AI 基础设施这个全链路,腾讯都选择了自主研发:
(1)领先的算力基础设施:服务器是腾讯云星星海自研服务器;算力平台是腾讯云高性能算力集群,性能提升 3 倍;自研星脉高速网络,拥有 3.2T 通信带宽,通信性能提升 10 倍。
(2)自研机器学习框架 Angel:AngelPTM 使训练速度相比业界主流框架提升 1 倍,AngelHCF 使推理速度比业界主流框架提升 1.3 倍。
(3)创新大模型训练:预训练上从零启动训练,优化预训练算法及策略;精调及强化学习,改进注意力机制,并开发了思维链新算法。
为何要全链路自研而非基于开源?蒋杰坦言:因为现有的开源技术,并不适用于腾讯的海量高并发。此外,正如汤道生所说:“我们始终认为,大模型需要基于产业场景,与企业数据融合,才能释放出最大的价值。AI 通过对企业生产、销售、服务各个环节的影响,助力产业生产效率提升、服务创新。”
得益于自研,自 2020 年开始研发起,混元大模型的技术积累就来自于腾讯丰富的应用场景,经过业务场景的充分磨练,在多次迭代后已成为通用技术底座,更能满足应用需要。据汤道生介绍,目前腾讯云、腾讯广告、腾讯游戏、腾讯金融科技、腾讯会议、腾讯文档、微信搜一搜、QQ 浏览器等 50+ 个腾讯内部业务和产品,已接入腾讯混元大模型测试并取得初步效果。
例如,在混元的助力下,腾讯会议的 AI 小助手打造完成,可快速实现会中问答、会议摘要、会议待办项等多种事项:

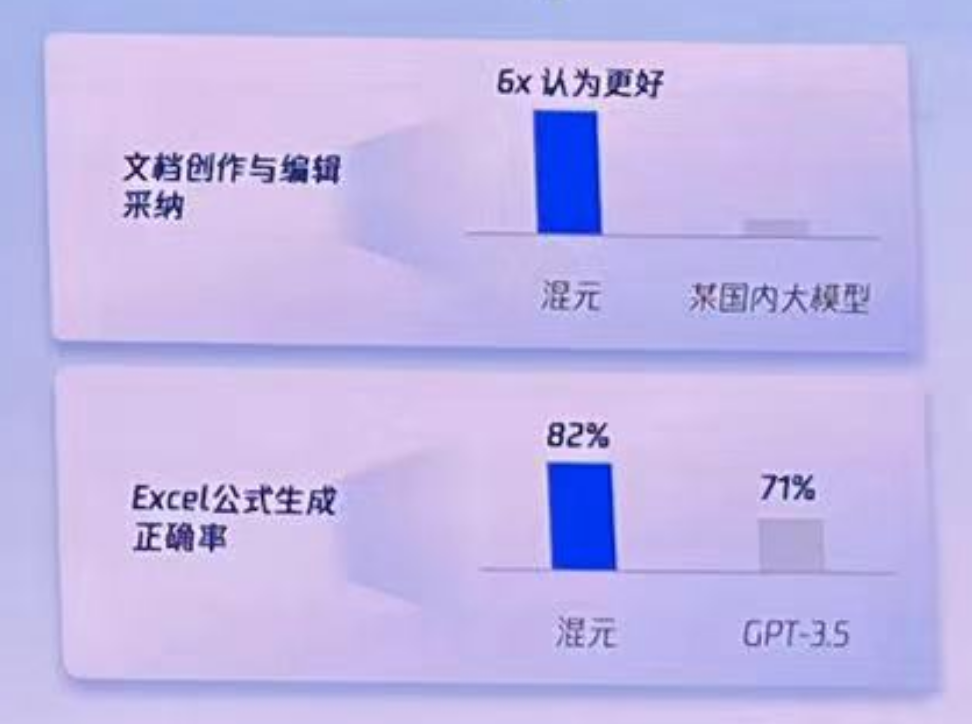
例如,在混元的加持下,腾讯文档也多了个智能助手功能,不仅支持数十种文本创作场景,还能生成上百种专业文书规范以及用自然语言生成数百种 Excel 公式等(目前这些功能还在内测阶段,将在成熟后面向用户开放):
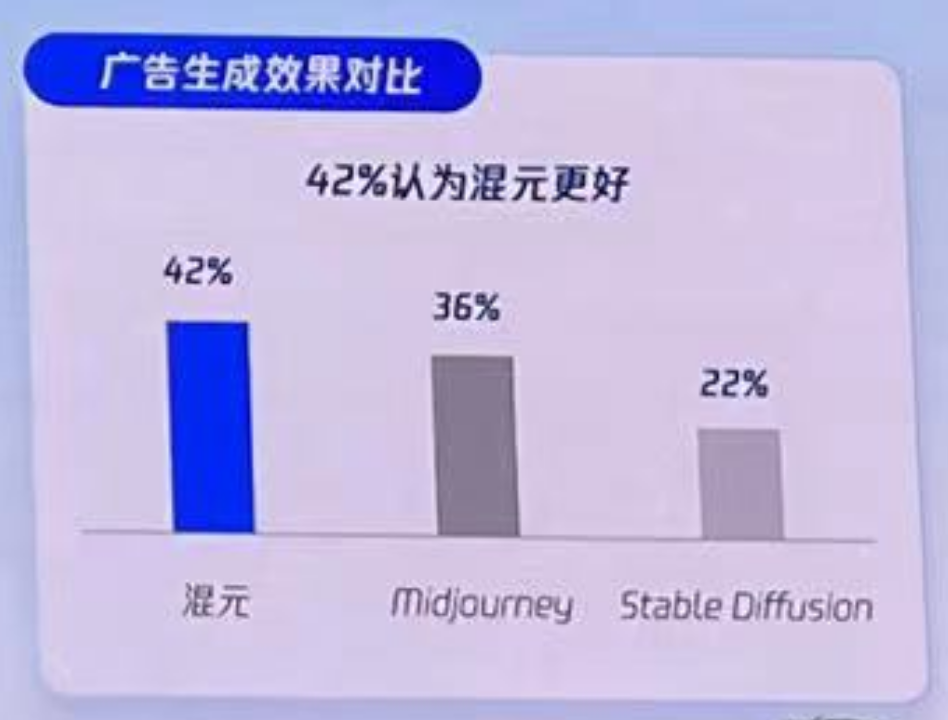
又例如,混元还加强了腾讯广告的智能化广告素材创作,在适应行业与地域特色的同时,还能将文字、图片、视频自然融合:
一如蒋杰所说,全面拥抱大模型已是腾讯的进行时。在演讲最后他也郑重宣布:腾讯混元大模型已正式通过腾讯云对外开放,主力全行业。 另外,据了解微信也已上线腾讯混元助手小程序,目前仅限受邀用户体验。


混元,将“永远在路上”
如开头所说,目前国内百模大战的密集发布期已过,腾讯在这个时间才让混元亮相,属实令不少业内人士感到疑惑:为什么?
对于这个问题,蒋杰在演讲后的媒体群访中给出了答案:混元在腾讯内部已经内测很久了,不是第一天才有,这次亮相也并不想抢风头,只是希望将它的应用展示给大家,“腾讯做这个就是看自己,不看别人。”
诚然如他所说,腾讯既“敢为天下后”,自有其独到策略和坚实技术基础。
2021 年起,腾讯先后推出了千亿和万亿参数的 NLP 稀疏大模型,打破 CLUE 三大榜单记录,实现在中文理解能力上的新突破;到了 2022 年,腾讯混元大模型被首次披露后,就在中文语言理解权威评测集合 CLUE 与 VCR、MSR-VTT,MSVD 等多个权威多模态数据集榜单中登顶……从零开始到现在的全自研,混元大模型从来都不是一蹴而就。
今年 5 月,腾讯董事会主席兼首席执行官马化腾曾说:
“我们最开始以为这是互联网十年不遇的机会,但是越想越觉得这是几百年不遇的、类似发明电的工业革命一样的机遇。互联网企业都有很多的积累,都在做,我们也一样在埋头研发,但是并不急于早早做完,把半成品拿出来展示。”或许是基于这一说法,业界对于现在“亮相”的混元大模型充满期待:已经是“成品”状态了吗?有望对标 GPT-4 了吗?准备好带来怎样的社会价值了吗?
对于这些问题,蒋杰淡然回应:“这次的亮相只是一个开始,我觉得我们一直在路上,混元也将永远在路上。未来的成果评估,我们交予大家来检验。”
推荐阅读:
▶OpenAI将举办首届全球开发者大会;Meta公司因争抢计算资源发生内斗;PHP 8.3 RC1发布|极客头条
▶大模型大战之年,Google 把生成式 AI 全面融入 Android、Web、云!