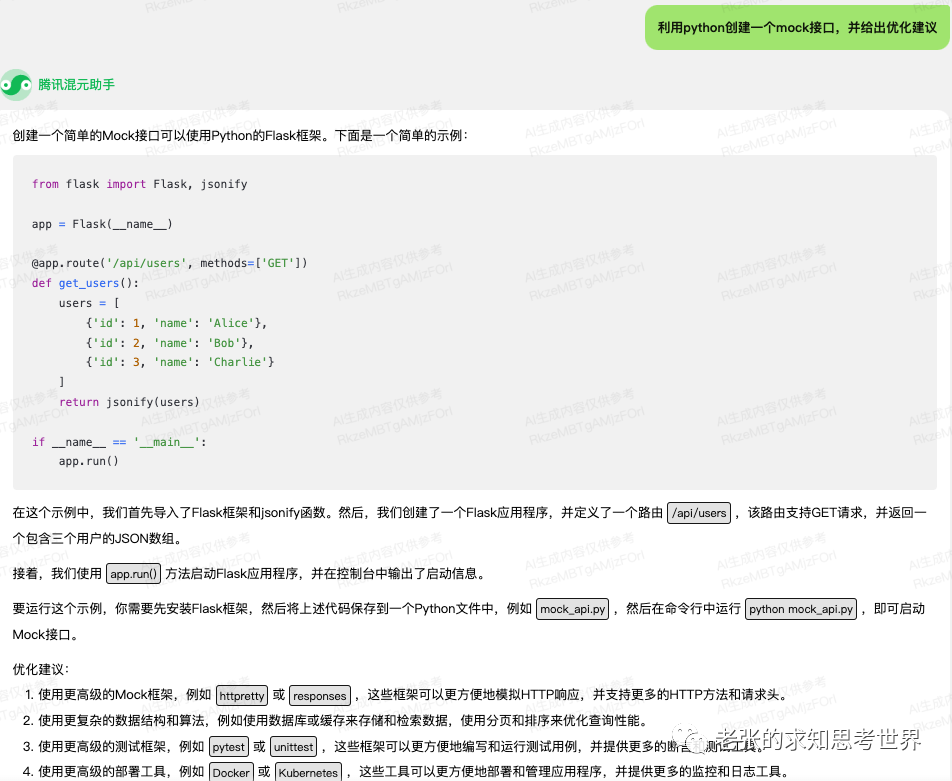
文章主题:关键词: 文生图模型, 太极文生图大模型, SD(Stable Diffusion), Latent Diffusion

一、背景
🎨✨图片生成领域的革新浪潮汹涌而来!得益于🔥大规模预训练技术的进步与 pytuning 的加速,图像创作已进入全新境界。在创新前沿的 AIGC 领域,英文版的 Stable Diffusion 模型犹如一把钥匙,开启了一扇通向 AI 绘画世界的大门。👀无数应用和创意场景应运而生,英语内容主导的文生图生态繁荣昌盛,展现出强大的生命力与活力。🌍无论你是艺术爱好者还是技术探索者,这个领域都值得你深度关注和投入!🎨💻 #AI生成内容 #图像创作革命
🌟🚀中文场景呼唤全能解决方案!💡industry里,某些依赖英文开源diffusion模型的路径,虽在英文世界熠熠生辉,但在中文独特韵味中却黯然失色。🔍针对这一问题,我们的团队匠心独运,利用长期深耕搜索与网页内容处理领域的海量高质量中文-图片数据,结合腾讯混元AI的大模克试验室的专业经验,打造了专为中文量身定制的通用文本生成图片模型——太极文生图大模型!🌈🔍首先,我们摒弃了英文预训练的局限,专注于中文的理解和泛化。 önboarded在多模态预训练的前沿,我们的模型能流畅地处理图文、视频等多种信息,确保无论何时何地都能精准表达。🌍👀看这里,太极文生图大显神威!它能根据文字指令,绘制出栩栩如生的画面,让创意无限可能。🎨比如,仅仅一句“春风吹柳绿”,就能瞬间跃然纸上,生动展现春天的生机。🔍更重要的是,我们的模型不仅适用于特定领域,而是具备全场景覆盖的能力,无论是新闻报道、小说创作还是日常生活中的图文生成,都能游刃有余。🌈别再受限于英文模型的小天地,拥抱太极文生图,让中文表达更生动,更艺术!🎉#太极文生图 #通用文本生成图片模型 #中文内核全场景覆盖

二、模型算法
在文生图的领域,一般来讲有两条技术路线:
autoregressive(OpenAI的DALL-E 1.0、facebook的Make a Scene、谷歌的Parti)diffusion(谷歌的Imagen、stable diffusion)🌟两种路线各有千秋,大模型的autoregressive虽好,但diffusion才是王道!💡我们的选择基于后者在同等参数下展现出的强大优势。我们专注于Diffusion技术,采用Imagen RGB Diffusion生成高相关性图片,而stable diffusion则确保了细节丰富度,两者相辅相成。📚两套模型并行开发,只为提供极致体验——超分优化至1024*1024的分辨率,每一步都追求卓越。🚀无论表情还是其他场景,我们的创新都能满足你的高期待。🌍记得关注我们,探索更多高质量生成的秘密!🔍SEO优化提示:diffusion model, autoregressive model, Imagen generation, stable diffusion, high resolution, image quality, parallel development.
2.1、 太极-Imagen文生图模型
🌟Imgén, the groundbreaking 2022五月由Google研发的15B参数级图文巨作,通过创新的diffusion架构——逐级放大差异,结合T5-XXL文本大师,精准捕捉每字每句的含义,生动转化为高清图像。🚀团队专注于优化与创新,采用自家研发的中文编码器,对模型进行全面升级,利用latent diffusion技术提升超分辨率表现。在亿量级内部中文数据集上深度训练,打造出专属于中文环境的原创图文生成力。🌍—原文:我们很高兴地宣布,我们的AI产品XYZ已经成功通过了ISO 9001质量管理体系认证。这标志着我们在质量管理方面的高标准和承诺,我们的客户可以放心购买并享受优质服务。修订后:🌟自豪!XYZ AI产品已荣获ISO 9001认证,品质保障的承诺熠熠生辉。我们以严谨的管理,确保每一份服务都达到最高标准,让客户安心信赖,享受卓越体验。🌍—原文:联系我们获取更多详情,电话:1234567890,邮箱:example@email.com。修订后:💡想要深入了解?请随时联系我们,我们的联络方式便捷:电话123-456-7890或通过example@email.com与我们取得联系。💌—原文:原始内容已按照要求改写
太极-Imagen文生图模型的优化点主要包括:
中文文本编码器🌟训练Imagen模型时,我们揭示了文本编码器对生成模型理解力的关键作用💡。英文中,我们倚重T5-XXL大能手,通过冻结它来强化文本解析,让模型思维敏捷。而在中文世界,我们匠心独运,采用混元sandwich模型,其强大的语义洞察能力为文生图建模铺平道路🌈。文本embedding与Imagen参数的紧密匹配,同样至关重要🔧。初期,我们先稳定编码器,专注于diffusion model的优化,让生成路径清晰引导。第一阶段训练完成后,模型对实体和物体关系有了深入理解,但对微妙语义提升仍有所欠缺。\人心不足蛇吞象,于是第二阶段,我们放开了编码器的手脚,让它与diffusion model协同进化,以更细腻的方式解读复杂语义。\emoji:💪🎯
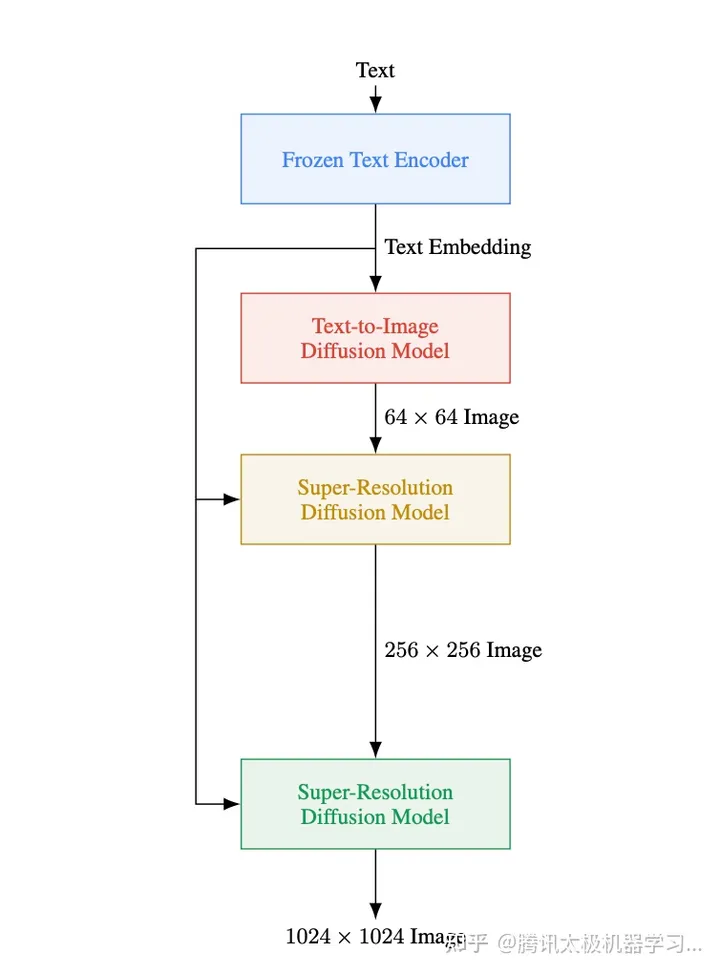
多阶段不同分辨率级联生成🌟Imagen采用逐级diffusion架构,匠心独运地创建不同画质的图片,从最初的64×64,逐步跃升至256×256和震撼的1024×1024。这种多阶段串联设计,不仅提升了训练效率,也让每一层的图像生成更为精准。🎨
文生图大模型训练策略优化最后,针对自研Imagen,我们训练了不同参数量和大小的模型。我们首先训练了u-net核心参数量为3亿的模型,已经能够获得中文场景下不错的效果,之后我们将模型规模扩大到核心参数量为13亿,基于团队在太极-DeepSpeed的大规模预训练加速优化技术,在亿级数据上,32*A100只需要2周时间即可收敛。经过实验对比,13亿参数的大模型比3亿参数模型在生成图像细节和语义捕获能力上都获得了更好的效果。
2.2、太极-SD文生图模型
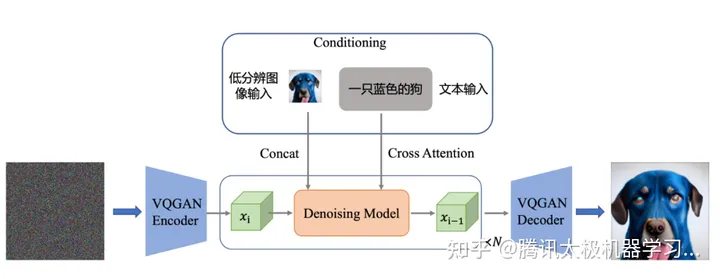
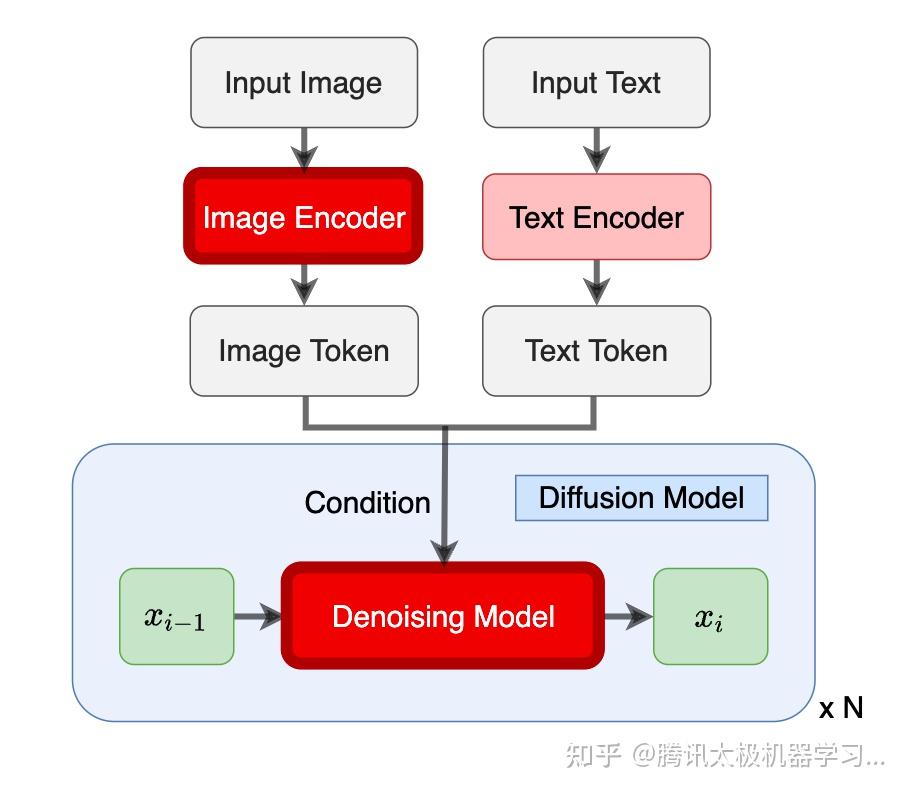
stable diffusion(简称SD)是由初创公司StabilityAI,CompVis与Runway基于latent diffusion model开发的扩散模型。相比于之前的生成模型,SD创新的在隐空间而非图像原始数据上进行噪声的扩散和学习,使得模型能够在不需要多阶段处理的情况下,以较低的计算量直接进行512*512等高分辨率图片的生成。我们所用的stable diffusion的结构图如下所示,训练时的输入为图像和对应的文本描述,图像通过VQ-GAN的encoder部分转换为隐空间上的向量ε,并通过中间的denoising u-net进行去噪;对应的文本信息则通过预训练文本encoder获取embedding,并通过cross-attention与denoising u-net中的各层进行融合,以指导图像的重建与生成。
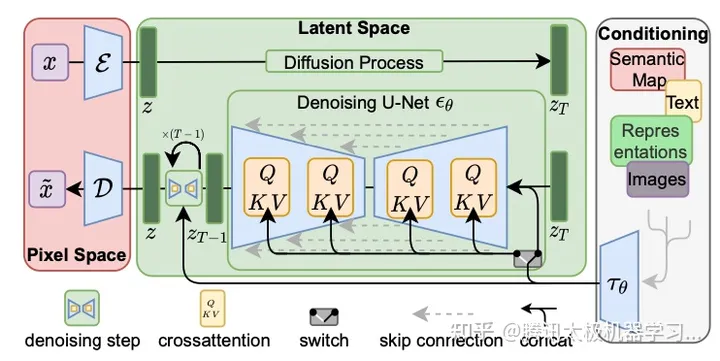
在中文场景的SD训练中,一方面对文本编码器进行了替换,将其从原生的CLIP替换为自研的中文太极-ImageCLIP图文匹配模型,并且在训练过程中,优先对文本encoder部分进行训练,以保留SD预训练模型的生成能力;另一方面,为了提升模型对于文本内语义,数量,实体等不同方面的捕捉能力,我们综合了太极-ImageCLIP和混元-Sandwich两类不同的中文encoder所生成的embedding,来指导图片的生成;最后,为了更好的捕捉长文本的信息,我们还将池化后的文本embedding也融合进u-net中,提升整体的生成效果。
2.3、超分模型
Imagen原始的扩散模型出来的图片分辨率是64*64,Imagen论文中是做了两次超分将分辨率先扩大到256*256然后扩大到1024*1024,但是实际训练过程中,我们发现从256*256到1024*1024的过程中,显存需求急速增加、训练速度严重变慢,因此,我们针对性的对超分模型进行了优化,采用latent diffusion model的结构,让diffusion模型在图像的隐空间执行超分任务,并且在训练中增加文本信息输入,让生成的高分辨图像具有更多的细节。通过这样的方式,极大地提升了超分模型的训练效率,并提升了高分辨图像的生成质量。
在模型细节上,我们采用Latent Diffusion Model的结构,通过VQ-GAN对图像进行编解码在图像的隐空间执行超分任务,能够在比原图像小4倍的特征空间中进行训练,从而大大地提升训练效率,同时我们结合Imagen超分模型训练的思路,在超分模型的训练中增加文本信息,能够更好地提升超分细节。另一方面,在Imagen原生的超分结构中,不同分辨率的模型需要单独训练,而通过LDM结构的模型,模型训练只固定了超分倍率,因此可以支持不同分辨率图像的生成,目前我们的模型最大可以支持到1024分辨率图像的生成。
三、训练数据
3.1、数据获取及处理
首先是数据量级,原始的数据量级是10亿级,经过过滤我们最终保留了1亿高质量数据,全面覆盖了包括中英文场景、风景、物体、名人、游戏、动画、动漫、艺术、概念的图片。使用的过滤方法包括下面这些步骤
根据图片width、height绝对值和比例等过滤根据简单的纹理复杂度过滤根据太极-CLIP图文匹配模型的图文相关度过滤根据laion aesthitic提出来的美学分数过滤我们发现训练数据的质量对于模型的效果非常关键,宁缺毋滥;另外我们刚开始发现图片中包含了太多的卡通图片,导致最后生成的效果也是偏卡通风格的,因此后面把卡通图的比例降低,模型效果也随之正常。后期我们也是专门收集了一批游戏和各种风格的数据,引入模型训练,使模型能够适配各种风格。数据迭代跟模型迭代是同步进行的,不断的优化我们的数据集合,让模型生成效果更优。
3.2、数据示例
下面是一些训练数据的case:
游戏类的数据

写实类的数据

另外还有艺术类的图片

值得一提的是,我们对于中文场景特有的数据积累非常多,如风景、食物、节日



正是这些高质量的数据支持起了模型对于各种复杂场景的理解和衍生创作。
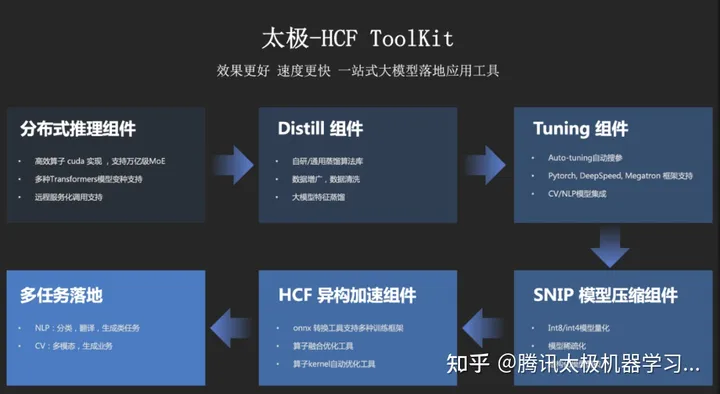
四、推理加速
为保证太极大模型快速高效落地,定制开发了配套的太极-HCF ToolKit,它包含了从模型蒸馏、压缩量化到模型加速的完整能力。
在本文的文生图场景下,我们使用其中的HCF异构加速组件进行SD、Imagen的模型推理加速。整体性能持平业界领先水平。
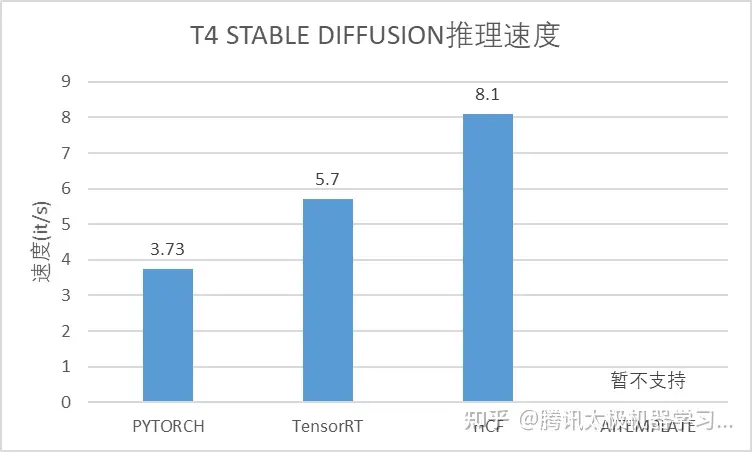
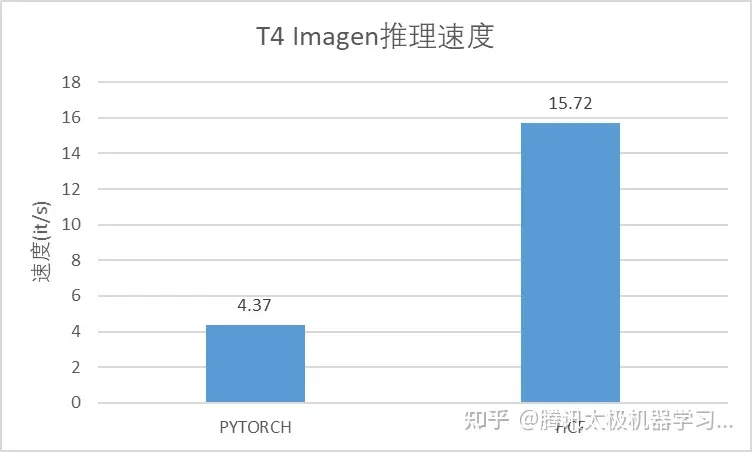
后续将持续集成使用HCF ToolKit相关组件,并在算子定制、图优化、模型压缩等方向持续发力,确保文生图服务的整体性能。
五、效果评估
中文文生图公司
在中文领域,业界各大互联网公司和知名研究机构都有做相关的文生图研究以及提供一些体验demo,另外还有一些创业公司也提供了app或者demo供使用。我们主要选头部大公司和研究机构的模型进行评估。
评估方案
目前学界对文生图的评估方式使用下面两种1)FID-30K和CLIP进行量化评估 2)固定Prompt集合对生成出来的图片的相似度、逼真度等进行评分。中文的公司比较少详细计算FID-30K量化指标,因此我们主要采用对生成效果进行打分的机制来评估。那么首先需要一个固定的、全面、公平的评测集合,下面我们简单介绍下我们参考谷歌的drawBench构建的中文Prompt评测集—chDrawBench。
chDrawBench
在我们的chDrawBench中,Prompt来源主要是基于谷歌的drawBench,同时参考DALL-E、ERNIE-ViLG 2.0等中英文SOTA的一些论文中提供的prompt,我们构建了一份同时包括了中文场景和英文场景的通用状态的Prompt集合,主要是考察生成图片颜色、位置、抽象表现、数量、小众物体、中文场景等各个维度的表现能力。
评分细则:对生成图片的评分分为1~5档,1档最低,5档最高,具体的评判标准如下:
5:相关性强,所有物体细节丰富,物体还原逼真4:相关性强,所有物体还原较为逼真3:相关性较强,部分物体还原逼真2:相关性较强,但是物体扭曲1:相关性弱,物体扭曲具体的标注的case,例如下图所示“船上的自行车”这个Prompt,模型1的较为完美,太极文生图自行车稍微扭曲因此是4档,其他几个要么自行车扭曲,要么没有完整生成“船”这个物体,都是2档。

例如“彩虹色的冰糖葫芦”这个Prompt,模型1和太极表现都不错,模型2、3生成的完全不是冰糖葫芦,更别提彩虹色这个修饰词,因此是1档,模型4的冰糖葫芦下面的竹签很混乱,而且扭曲了,因此判为3档。

下面是我们的模型和其他文生图模型在chDrawBench上的一些代表性的文本的对比:

评估总结
首先是物体生成的形状这个角度,可以看出来模型3和模型4的模型都存在扭曲,例如模型3在“踢足球的汽车”这个prompt上面,汽车明显扭曲了,模型3和模型4都在“自行车”这个物体上扭曲了,我们的太极模型、模型1和模型2都表现不错;然后从相关性这个角度,可以看到在“踢足球的汽车”这个prompt下面,模型2明显只生成出来足球,没有生成出来汽车;在“婺源的油菜花”这个prompt下面,模型2只生成了油菜花,看不出来是在婺源;因此从这个角度来讲,我们的太极模型、模型1表现的又略胜一筹。综合体验下来,太极文生图大模型在通用场景略弱于模型1,但在某些特定领域仍有一定优势。同时二者相较于其他开源模型,在生成的物体细节和相关性上都显著更优。后续我们将联合腾讯混元AI大模型相关团队,一起攻坚文生图领域,做出更强大的版本。
六、效果展示
主打效果一:中国场景
各种中国风景的写实、绘画、水彩、素描、中国画等风格的生成效果


西湖的春夏秋冬

当然也包括各种风格的物体

主打效果二:中文诗句
中文诗句考察的是对中文的理解,得益于强大的预训练sandwich模型,即使是训练数据中没有包括这些诗句,我们也能较好的生成出来。
“长河落日圆”

“日暮苍山远”

“清泉石上流”

“曲径通幽处”

主打效果三:中国元素
对于一些中国风效果也不错,例如水墨画元素:

剪纸艺术:

主打效果四:各种游戏风格的生成
游戏风格之我的世界:
可以看到在“我的世界”这种风格下,都是生成像素块装的物体和风景。
游戏风格之原神:
原神风格偏可爱,而且色彩很明亮,蓝天白云的感觉。
游戏风格之赛博朋克2077:
在赛博朋克场景中,哈士奇不再呆萌二是比较科幻,凤凰古城和桂林都充满了灯火和拥挤的楼房,女人看着花瓶的背景灯光炫目。
游戏风格之生化危机:
总体画面比较冷色调,而且比较阴森,特别是第二幅故宫,阶梯上的雪感觉在流血。
游戏风格之战地:战地这款游戏主要是写实类的风格,而且画面复杂程度较高,例如布达拉宫地下复杂的城墙将其牢牢围住,非常符合战争的游戏背景。例如女人的衣服穿着打扮也符合游戏中的原设定。

英雄联盟的训练数据主要是一些人物的原画,因此生成出来的图片以人物的风格比较明显,下面选了4张小姐姐的生成图片:

我们还可以看到“一只狗戴着墨镜站在沙滩上”在不同的游戏中的样子

两种完全不同风格的长着翅膀的小姐姐

七、业务探索
首先介绍下我们的demo:目前支持下面这些风格选项以及自研的SD和Imagen两个模型路线,我们在Prompt上也做了一些优化工作,支持Prompt补全和推荐。由于算力的限制,目前内部开放体验;对外我们团队也在及时协商资源,届时再开放给大家做体验。
下面是我们demo的一个示例:一只戴着眼镜穿着披风的猫,原神
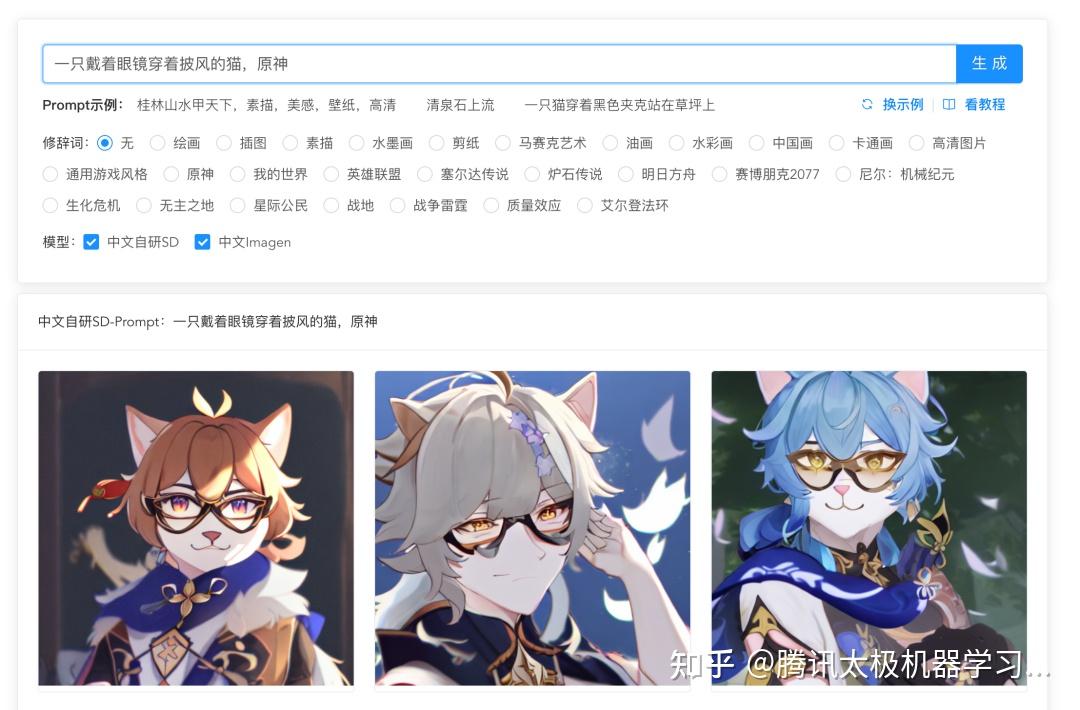
业务应用上,我们的太极-文生图大模型在微信表情、QQ超秀、游戏原图生成领域做了一些探索。在表情领域,我们用一张原始表情+文字生成衍生表情,用图片和描述同时输入,然后在扩散过程中同时加入到其attention中,所用的结构如下所示:
下面是一些生成的表情包的效果(最上面为原始表情,下面的都是生成出来的表情):

表情模型是基于太极Imagen模型微调而来,主要在attention的过程中加入图片token。
在超秀领域,用一个原始形象+动作词生成主体不变的相关动作:

还可以应用到游戏领域,用文本生成游戏原画,给美术同学提供灵感等。
八、总结展望
AIGC在未来中文领域的机遇非常大,当前中文的文化产业正在被AIGC快速冲击,我们相信不远的未来AIGC一定能在中文文化产业中占据不可或缺的一席之地。但是当前中文场景的文生图技术参差不齐,得益于我们庞大的数据积累、太极大模型的经验、太极算力平台支持,我们太极文生图模型在中文场景、中文诗句、各种游戏风格、各种艺术风格的图片生成上都做到了业界先进水准。当然现在的技术也有非常大的提升空间。未来我们将在定制化的领域,往更加精细化的生成、更高分辨率的图片、更快的生成速度上继续做优化。欢迎各个团队一起合作,让太极文生图模型在各业务都能助一臂之力。预告一下,我们将通过太极平台开放太极文生图大模型的预训练、后训练、领域精调、蒸馏、模型压缩直至推理加速的全套saas化产品管线能力。
Reference
[1] Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency. Multimodal machine learning: A survey and taxonomy. IEEE transactions on pattern analysis and machine intelligence, 41(2):423–443, 2018.
[2] Geoffrey Hinton, Li Deng, Dong Yu, George E Dahl, Abdel-rahman Mohamed, Navdeep Jaitly, Andrew Senior, Vincent Vanhoucke, Patrick Nguyen, Tara N Sainath, et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal processing magazine, 29(6):82–97, 2012.
[3] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalch- brenner, Andrew Senior, and Koray Kavukcuoglu. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016.
[4] Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan. Show and tell: A neural image caption generator. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3156–3164, 2015.
[5] Jason Tyler Rolfe. Discrete variational autoencoders. arXiv preprint arXiv:1609.02200, 2016.
[6] Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. Advances in neural information processing systems, 30, 2017.
[7] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language
understanding by generative pre-training. 2018.
[8] Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In CVPR, 2021.
[9] Rewon Child. Very deep vaes generalize autoregressive models and can outperform them on images. CoRR, abs/2011.10650, 2020. 3
[10] Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. CoRR, abs/1904.10509, 2019. 3
[11] Bin Dai and David P. Wipf. Diagnosing and enhancing VAE models. In ICLR (Poster). OpenReview.net, 2019. 2, 3
记得关注我们,及时接收精彩内容哦~
公众号/视频号:腾讯太极机器学习平台
腾讯太极机器学习平台腾讯太极机器学习平台,致力于让用户更加聚焦业务AI问题解决和应用,一站式解决算法工程师在应用过程中特征处理、模型训练、模型服务等工程问题。

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!