文章主题:国产大模型, 百模大战, GPT-4, 开源模型

智东西
作者 | 漠影
编辑 | 三北
随着“百模大战”进入小考时刻,已经有国产大模型交高分卷了。
在9月1日,我国网信办发布了一则关于深度合成服务算法备案公告,这一消息一经传出,立即引发了国内各大模型的关注。这些头部大模型纷纷公开宣布向全社会开放其服务,以接受新的挑战和机遇。
在这个特定的时刻,一款国产开源大模型已经崭露头角,成功地征服了各大中英文测评榜单。它在基座模型测试中的表现尤为惊人,甚至超越了像Llama 2等知名的开源大模型。而在垂直行业领域的表现更是令人瞩目,远远超过了其他竞争对手,呈现出一种“黑马”崛起的态势。
根据官方数据统计,今年8月份,该模型在GitHub、Hugging Face等著名开源社区中的下载量超过300万,刷新了全球同类开源模型的最高纪录,从而成为全球最受欢迎的GPT-4替代方案之一。
值得注意的是,该模型的研发团队勇于创新,首次公开了模型训练的过程。这一举措得到了复旦大学计算科学技术学院教授张奇的赞誉,他认为这对学术界产生了重大影响。
在9月6日这个重要时刻,搜狗创始人王小川所创立的百川智能公司,成功推出了Baichuan 2大模型,并与此同时,向大家揭示了相关的前沿动态。王小川表示:“我们已经告别了Llama2开源模型的时代,现在,我们可以享受到更为友好且功能更强大的开源模型。”
近年来,我国大型人工智能模型正逐步改变着各行各业的生态格局。在这其中,百川智能公司最新发布的Baichuan 2大模型,被视为具有颠覆性的力量。那么,这款模型的实际性能如何呢?其背后的战略与行动布局又是怎样的呢?通过对百川大模型200多天的实践进行深入剖析,我们将能够更加清晰地了解到,国产大模型正在如何打破现有的游戏规则。首先,我们要了解的是,Baichuan 2大模型的强大之处。它拥有超过1.75万亿个参数,远超业界同类产品。这使得它在诸如自然语言理解、计算机视觉等众多领域都展现出了卓越的性能。而且,它的训练时间仅为6个月,相较于传统的训练方式,效率提高了数十倍。这样的表现,无疑让人对国产大模型充满了期待。然而,要想真正发挥大模型的潜力,仅仅依靠强大的技术实力是远远不够的。因此,百川智能公司在Baichuan 2大模型的研发过程中,采取了一系列富有策略性的行动。他们积极与各行业的需求进行对接,以实现模型的定制化应用。同时,他们还通过构建一个开放的大模型平台,鼓励合作伙伴共同开发大模型应用,从而形成了一个良性的循环。正是这种策略性的布局,让Baichuan 2大模型在实践中得以更好地服务于各行业。例如,在金融领域,Baichuan 2大模型可以帮助银行和保险公司进行风险评估、信贷审批等工作,提高工作效率,降低成本。在医疗领域,它可以辅助医生进行疾病诊断,提高诊断的准确性,为患者提供更好的治疗方案。这些成功的应用案例,无疑证明了百川智能公司的战略眼光和实践能力。综上所述,我们可以看出,国产大模型正在通过改写产业的游戏规则,推动各行各业的发展。而百川智能公司的Baichuan 2大模型,则是这一变革中的先锋。通过持续优化模型性能、拓展应用场景、推动行业合作,我们有理由相信,Baichuan 2大模型将在未来发挥更大的作用,引领我国人工智能发展的新篇章。
9月13日,通过对话百川智能技术联创陈炜鹏,智东西对此进行了深入探讨。
Baichuan 2下载地址:
https://github.com/baichuan-inc/Baichuan2一、月下载超300万,测评全面碾压Llama 2
随着“百模大战”进入深水区,当下大模型进行简单对话已不足为奇,还要追求“文理兼修”。
百川智能于9月6日新推出的Baichuan 2开源模型,不仅文科能力大幅提高,其在数学能力、代码能力、安全能力、逻辑、语义理解都有明显的提升。陈炜鹏告诉智东西,无论是在MMLU、CMMLU、BBH等综合性基准测评中,还是在GSM8k、HumanEval等垂直领域的测评中,抑或是多语言能力测评中,Baichuan 2都远超同类开源大模型。

Baichuan 2相比于一代Baichuan的能力提升
在所有主流中英文通用榜单上,Baichuan 2全面领先Llama 2,而Baichuan2-13B在测评中秒杀所有同尺寸开源模型。
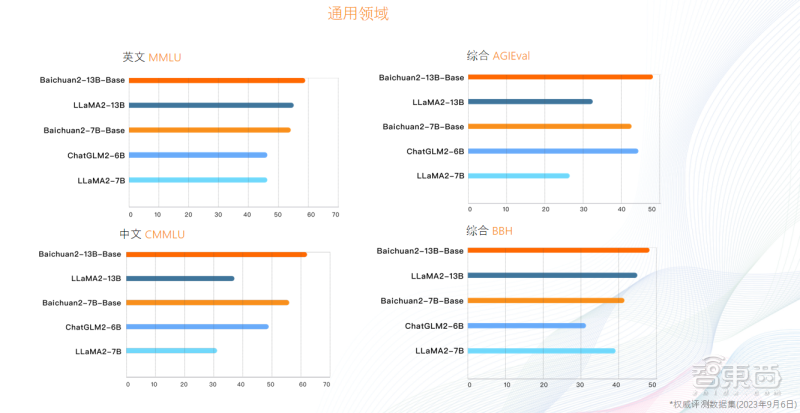
Baichuan 2在通用领域的测评成绩
在垂直行业测评榜单中,Baichuan2-13B在法律、数学、医疗领域的模型效果均优于其他开源模型。
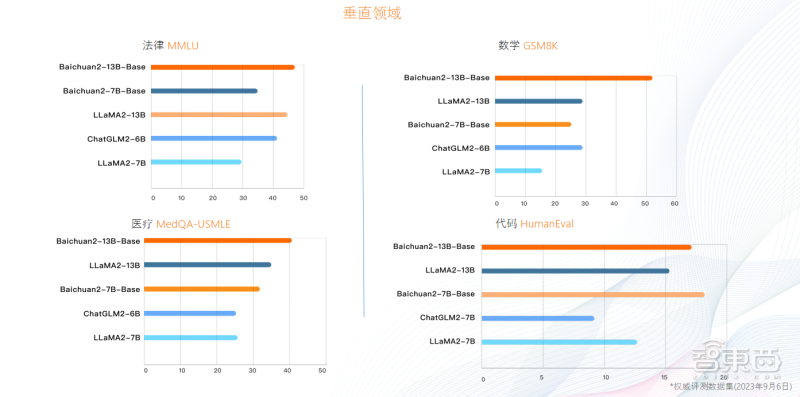
Baichuan 2在垂直领域的测评成绩
在跨语言能力测评榜单中,Baichuan2-13B在英语、法语、阿拉伯语、俄语中的能力都超过其它开源模型。
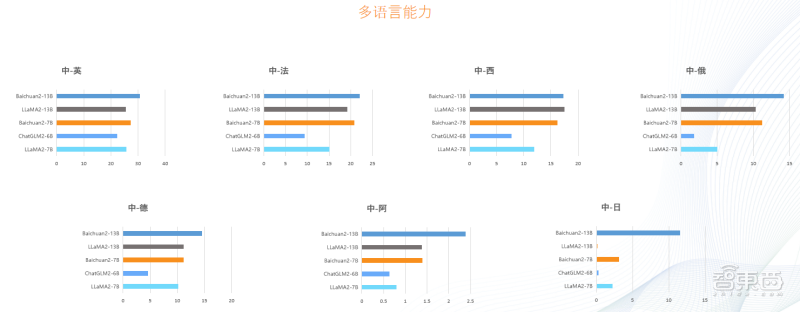
Baichuan 2在多语言领域的测评成绩
IDEA研究院讲席科学家张家兴参与了百川智能最新的发布会,他在会上的圆桌峰会中称:“国内做大模型的团队也很多,能做到Baichuan 2这样效果的还是很少。”实际上,当下很多大模型测评是围绕单点维度进行的,甚至大家看到GPT-4在某些榜单中已经排到了10名往后,其实意义不大。而百川大模型公布了全面性的测评结果,相对更具有说服力。
“除了榜单,场景实测更重要。”陈炜鹏告诉智东西,“目前Baichuan在开源社区总下载量已经超过500万次,月下载量达到300多万次。”
Baichuan大模型在开源社区的下载情况
据悉,已有200+企业申请百川大模型开源商用授权,并已将百川模型投入实际生产场景。申请企业涵盖互联网、软件和信息技术、金融、法律、教育、制造、企业服务等众多领域,合作伙伴群体仍在持续扩大。
可以看到,不仅全面刷榜权威基准,百川智能开源大模型在各行各业已经加速落地。
二、直击商业协议“隐痛”,国产大模型要改变游戏规则
陈炜鹏告诉智东西,采用Baichuan 2,开发者不仅能够得到直接的效果提升,还能够获得更多实际的便利。
比如很多开发者为Llama 2的商业协议所困,迁移到Baichuan 2则可以避开不少“隐痛”。
Llama 2的商用协议对中国开发者并不友好。虽然宣称开源,但其商用协议声明“仅适用于英文为主的环境”。也就是说,如果你做的模型更多是商用于中文场景,是拿不到开源协议的。
Llama 2的商业协议部分内容
对此,Baichuan 2面向中文领域全面开放,且在多语言环境中提供免费服务。陈炜鹏告诉智东西,对于迁移到Baichuan 2的开发者来说,不仅模型效果得以提升,迁移成本也更低。Llama 2等模型所依赖的推理、加速、调优等套件,其中超70%的套件Baichuan 2都同等支持,剩下30%则是不常用的。
直击商业协议“隐痛”,国产大模型厂商正试图改变硅谷主导的游戏规则。
王小川在Baichuan 2的发布会上说:“Llama 2开源模型的时代已经过去了。我们现在可以获得比Llama更友好且能力更强的开源模型,能够帮助扶持中国整个生态的发展。”
为了构建大模型生态,9月6日,百川智能率先开放了其大模型训练过程,助力伙伴在理解训练过程的基础上做微调和强化;同时其设立了大模型科研基金,通过跟CCF(中国计算机学会)的合作,在今年内会大约投入300~400万人民币支持高校项目开发;此外,其还与AWS合作开展了黑客马拉松活动,面向开发者提供算力支持,以鼓励其进行大模型应用的开发。
在国内开源社区建设方面,Baichuan大模型不仅在GitHub、Hugging Face等国际开源社区中上线,最新的Baichuan 2也已经上线了国内的魔塔社区、昇思社区等知名AI社区,壮大本土AI大模型开源生态。
三、全球大模型“乱斗”,百川智能200天“蝶变”
当下,全球AI大模型产业正进入“乱斗”阶段。
这厢,微软将与OpenAI的“铁联盟”关系搁置一边,转而搭上Llama 2等开源模型;那厢,Meta也传出明年要训练对标GPT-3.5的闭源大模型,同时Anthropic、A21 Labs等创企也紧锣密鼓,想要在全行业AI化的浪潮中分一杯羹。
在国内,从自主可控和数字化转型需求出发,“百模大战”已经打响近半年。知名行研机构IDC预测,2026年中国AI大模型市场规模将达到211亿美元,互联网大厂、AI创企、传统行业龙头企业纷纷加入了大模型角逐,计划有朝一日做出赶超GPT-4的大模型。
诚然,GPT-4仍然是一堵高墙,但其早已不是业内唯一选择。国内的开源大模型已经在更多需要私有化部署、轻量化应用和自主可控技术的场景,填补空缺位置。
百川智能正是率先抓住了这样的市场空缺机遇,在过去的200多天里探索“蝶变”。
按照百川智能创立之初的计划,其预计在2023年三季度推出500亿规模参数的模型,四季度发表对标GPT-3.5的模型,在2024年一季度的时候发布超级应用。
实际上,团队一方面顺利执行原计划,另一方面开辟了开源路线——在二季度发现中国有开源模型的需求,于是从6月开始以平均每月一次的频率发布了开源模型,免费开源了7B、13B不同尺寸的大模型。
为什么能够如此快速反应,且迭代如此之快?
陈炜鹏向智东西道出背后的一个关键要点:百川智能将搜索的经验快速迁移到大模型的研发中。回顾大模型的训练过程,陈炜鹏解读道,这就类似一个“造火箭”系统化工程。对于百川智能团队来说,这与其熟悉的搜索研发模式有相似之处,将复杂的系统做拆解,通过过程评估来推动团队的协同,显著提升团队的效果。
在技术方面,大模型和搜索有很多重合的技术栈,比如在大模型训练中关键的数据环节,团队基于搜索经验实现数据精选和处理,数据处理环节实现千亿数据的小时级去重,并通过多粒度内容质量打分提升大模型质量。正是基于这种精细构造的数据,百川智能采用了开源最大的2.6T语料训练7B/13B的模型。在模型研发的过程中,百川也探索了基于自己数据的scaling law(比例定律),实现了实现高效、稳定、可预测。
据悉,团队在千卡的A800集群里面达到180TFLOPS的训练性能,使得机器利用率超过50%,在行业中间也处于最高水平之一。而跳出模型训练本身来说,通过多次迭代并通过开源社区反馈,百川智能不断提升Baichuan大模型的竞争力,也同时为闭源大模型的开发提供助力。
结语:从闭源到开源,国产AI大模型加速突破
“百模大战”狂飙200天,目前已进入了阶段性“交卷”时刻。国内不仅有大厂的闭源大模型产品面向全社会开放,也有AI创企如百川智能研发的开源大模型获得了权威测评、开发者社区和行业客户的多方面认可。
虽然GPT-4依然强势,但国内开源大模型已经能够进行部分替代。在私有化部署、轻量化应用及自主可控要求高的场景中,以Baichuan 2为代表的大模型找到市场空缺,快速行动。
与此同时,相比于ChatGPT强调的语言对话能力,国内大模型在数学、逻辑、代码等领域都在加速突破。这些能力代表着大模型要真正摆脱“幻觉”,从而开拓着更广阔的潜在市场。

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!