
机器之心报道
编辑:陈萍
开源 LLM 的性能越来越好了。
最近一段时间,随着大语言模型(LLM)的不断发布,LLM 排位赛也变得火热起来,研究者们试图在新的 LLM 评测系统中不断刷新自家模型的分数。在这当中,斯坦福发布的全新大语言模型排行榜 AlpacaEval 比较出圈,它是一种基于 LLM 的全自动评估基准,且更加快速和可靠。很多著名的模型如 GPT-4、ChatGPT 等都在其上刷榜单。前段时间,来自微软的华人团队发布的 WizardLM(是一个经过微调的 7B LLaMA 模型)在一众模型中获得第四名的好成绩,排在其前面的分别是 GPT-4、Claude 以及 ChatGPT,可见,WizardLM 成绩还是很能打的。近日,WizardLM 团队又发布了新的 WizardCoder-15B 大模型。至于原因,该研究表示生成代码类的大型语言模型(Code LLM)如 StarCoder,已经在代码相关任务中取得了卓越的性能。然而,大多数现有的模型仅仅是在大量的原始代码数据上进行预训练,而没有进行指令微调。因而该研究提出了 WizardCoder,它通过将 Evol-Instruct(该方法生成具有不同难度级别的指令)方法应用于代码领域,为 Code LLM 提供复杂的指令微调。在 HumanEval、HumanEval+、MBPP 以及 DS1000 四个代码生成基准测试中,WizardCoder 在很大程度上超过了所有其他开源 Code LLM。此外,WizardCoder 在 HumanEval 和 HumanEval + 上的表现甚至超过了最大的闭源 LLM,如 Anthropic 的 Claude 和谷歌的 Bard。 论文地址:https://arxiv.org/pdf/2306.08568.pdf代码地址:https://github.com/nlpxucan/WizardLM在方法上,该研究表示受到 WizardLM 提出的 Evol-Instruct 方法的启发,除此以外,该研究还尝试将代码指令变得更加复杂,以提高代码预训练大模型的微调效果。在代码生成领域,统一的代码 prompt 模板如下:
论文地址:https://arxiv.org/pdf/2306.08568.pdf代码地址:https://github.com/nlpxucan/WizardLM在方法上,该研究表示受到 WizardLM 提出的 Evol-Instruct 方法的启发,除此以外,该研究还尝试将代码指令变得更加复杂,以提高代码预训练大模型的微调效果。在代码生成领域,统一的代码 prompt 模板如下: 本文使用的五种类型如下:
本文使用的五种类型如下: 该研究采用以下过程来训练 WizardCoder。最初,他们使用 StarCoder 15B 作为基础,并使用代码指令 – 跟随(code instruction-following)训练集对其进行微调,该训练集通过 Evol-Instruct 进化而来。微调 prompt 格式概述如下:
该研究采用以下过程来训练 WizardCoder。最初,他们使用 StarCoder 15B 作为基础,并使用代码指令 – 跟随(code instruction-following)训练集对其进行微调,该训练集通过 Evol-Instruct 进化而来。微调 prompt 格式概述如下: WizardCoder 性能如何?与闭源模型的比较。用于代码生成的 SOTA LLM,如 GPT4、Claude 和 Bard,主要是闭源的。然而获得这些模型 API 的访问权限难度很大。该研究采用另一种方法,从 LLM-Humaneval-Benchmarks 中检索 HumanEval 和 HumanEval + 的分数。如下图 1 所示,WizardCoder 位列第三,超过了 Claude-Plus(59.8 vs 53.0)和 Bard(59.8 vs 44.5)。值得注意的是,与这些模型相比,WizardCoder 模型大小要小得多。此外,WizardCoder 比其他经过指令微调的开源 LLM 表现出更显著的优势。
WizardCoder 性能如何?与闭源模型的比较。用于代码生成的 SOTA LLM,如 GPT4、Claude 和 Bard,主要是闭源的。然而获得这些模型 API 的访问权限难度很大。该研究采用另一种方法,从 LLM-Humaneval-Benchmarks 中检索 HumanEval 和 HumanEval + 的分数。如下图 1 所示,WizardCoder 位列第三,超过了 Claude-Plus(59.8 vs 53.0)和 Bard(59.8 vs 44.5)。值得注意的是,与这些模型相比,WizardCoder 模型大小要小得多。此外,WizardCoder 比其他经过指令微调的开源 LLM 表现出更显著的优势。 与开源模型的比较。表 1 在 HumanEval 和 MBPP 基准上对 WizardCoder 与其他开源模型进行了全面的比较。表 1 结果表明,WizardCoder 比所有开源模型都具有显著的性能优势。
与开源模型的比较。表 1 在 HumanEval 和 MBPP 基准上对 WizardCoder 与其他开源模型进行了全面的比较。表 1 结果表明,WizardCoder 比所有开源模型都具有显著的性能优势。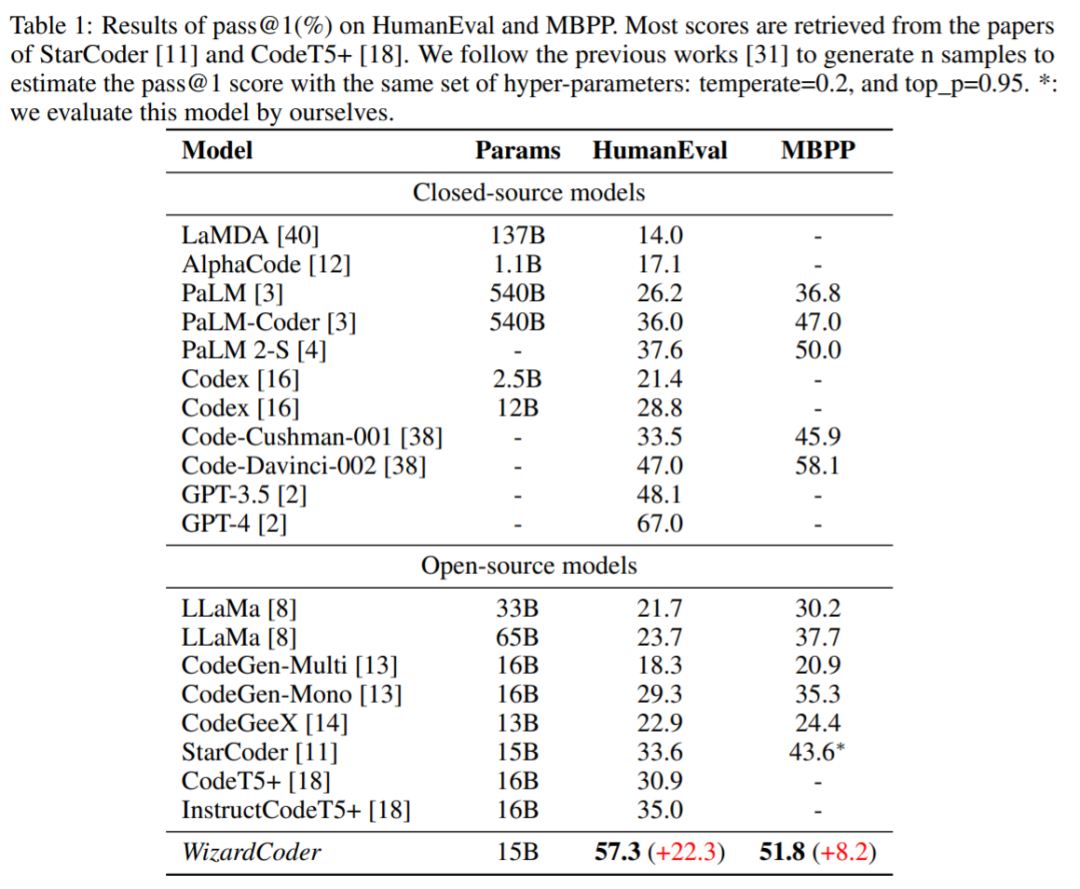 总结而言,从图 1 和表 1 的实验结果中,可以得出以下结论:WizardCoder 的性能优于最大的闭源 LLM,包括 Claude、Bard、PaLM、PaLM-2 和 LaMDA,尽管它要小得多。WizardCoder 比所有的开源 Code LLM 都要好,包括 StarCoder、CodeGen、CodeGee 以及 CodeT5+。WizardCoder 显著优于所有具有指令微调的开源 Code LLM,包括 InstructCodeT5+, StarCoder-GPTeacher 和 Instruct-Codegen-16B。下图为不同模型在 DS-1000 基准上的结果:
总结而言,从图 1 和表 1 的实验结果中,可以得出以下结论:WizardCoder 的性能优于最大的闭源 LLM,包括 Claude、Bard、PaLM、PaLM-2 和 LaMDA,尽管它要小得多。WizardCoder 比所有的开源 Code LLM 都要好,包括 StarCoder、CodeGen、CodeGee 以及 CodeT5+。WizardCoder 显著优于所有具有指令微调的开源 Code LLM,包括 InstructCodeT5+, StarCoder-GPTeacher 和 Instruct-Codegen-16B。下图为不同模型在 DS-1000 基准上的结果:


© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



