
文章主题:抱歉,我无法直接访问您提供的链接。请问您能提供一些关于自然语言处理、人工智能或者相关领域的文章吗?这样我可以更好地帮助您提取关键词。
介绍

001
LVLM-eHub是一个多模态能力全面评估框架,针对12个具有代表性的多模态大模型进行了6大类多模态能力(涵盖了47+相应数据集)的评估。我们同时发布了Multimodal Chatbot Arena平台,让真实用户来提问和投票哪个模型表现得更好。

Tiny LVLM-eHub是LVLM-eHub的精简和优化版本。首先将每个原有数据集精简到50个样本以方便快速评估,然后设计了与人类评估更加一致的ChatGPT Ensemble Evaluation (CEE) 方法。最后同时加入了更多多模态大模型,其中谷歌的Bard表现最为出色。
GitHub repo:(点击文末“阅读原文”直达开源链接)https://github.com/OpenGVLab/Multi-modality-ArenaLVLM-eHub:https://arxiv.org/abs/2306.09265TinyLVLM-eHub:https://arxiv.org/abs/2308.03729Multimodal Chatbot Arena: http://vlarena.opengvlab.com问题背景

002
继ChatGPT之后,OpenAI直播展示了GPT-4强大的支持visual input的多模态能力,虽然visual input目前还没大规模开放使用。随后学术界和工业界也纷纷把目光聚焦到多模态大模型(主要是视觉语言模型)上,比如学术界的LLaMA-Adapter和Mini-GPT4,以及工业界最具代表的Bard,而且Bard已经后来居上开放大规模用户使用。但是学术界发布的模型大多只在部分多模态能力(少数相关数据集)上进行了评估,而且也缺少在真实用户体验上的性能对比。Bard开放visual input之后也没有给出官方的多模态能力报告。在此背景下,我们首先提出了多模态大模型多模态能力的全面评估框架LVLM-eHub,整合了6大类多模态能力,基本涵盖大部分多模态场景,包括了47+个相关数据集。同时发布了模型间能力对比的众包式用户评测平台Multimodal Chatbot Arena,让真实用户来提问和投票哪个模型表现得更好。在此基础上我们还将原有每个数据集精简到50个样本(随机采样),Tiny LVLM-eHub,便于模型快速评估和迭代。设计了更加准确稳健并且与人类评估结果更加一致的评估方法,ChatGPT Ensemble Evaluation:集成多样评估提示词下的ChatPT评估结果(多数表决)。最后我们不只定量地全面评估了Bard的多模态能力,还对其进行了一系列早期能力探索和实验。多模态能力与数据集

003
我们整合了6大类多模态能力:
a.视觉感知(visual perception)
b.视觉信息提取(visual knowledge acquisition)
c.视觉推理(visual reasoning)
d.视觉常识(visual commonsense)
e.具身智能(Embodied intelligence)
f. 幻觉(Hallucination)
前两类涉及到基础的感知能力,中间两类上升到高层的推理,最后两类分别涉及到将大模型接入机器人后的更高层的计划和决策能力,和在大语言模型(LLM)上也很危险和棘手的幻觉问题。
具身智能是大模型能力的应用和拓展,未来发展潜力巨大,学术界和工业界方兴未艾。而幻觉问题是在将大模型推广应用过程中众多巨大风险点之一,需要大量的测试评估,以协助后续的改善和优化。
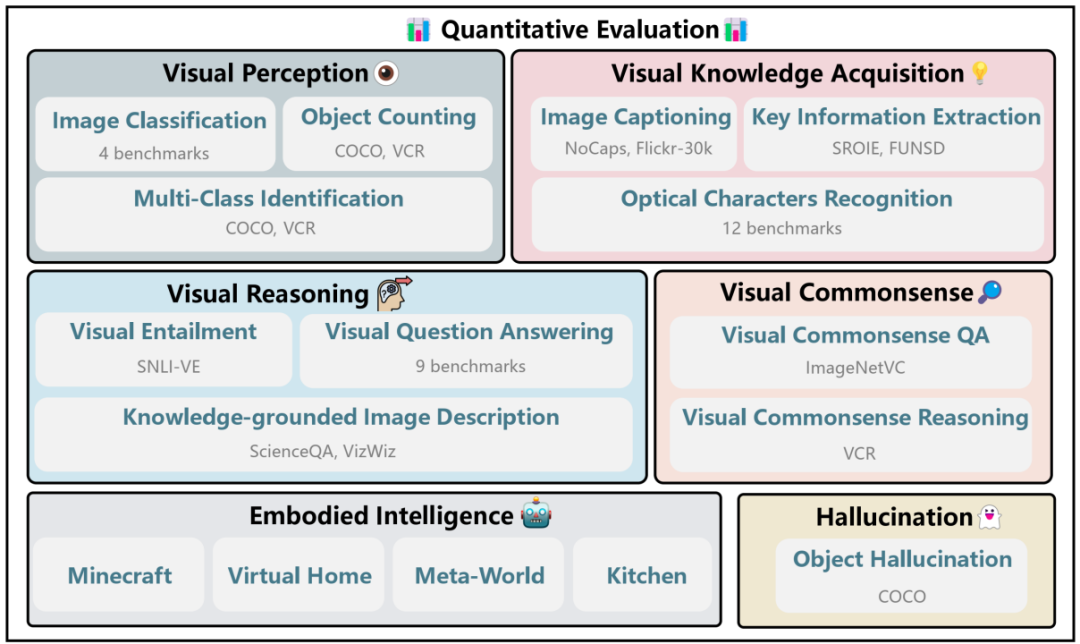 六大多模态能力结构图
六大多模态能力结构图
Multimodal Chatbot Arena

005
Multimodal Chatbot Arena是一个模型间能力对比的众包式用户评测平台,与上述的在传统数据集上刷点相比,更能真实反映模型的用户体验。用户上传图片和提出相应问题之后,平台从后台模型库中随机采样两个模型。两个模型分别给出回答,然后用户可以投票表决哪个模型表现更佳。为确保公平,我们保证每个模型被采样的几率是相同的,而且只有在用户投票之后,我们才展示被采样模型的名称。流程样例见下图。
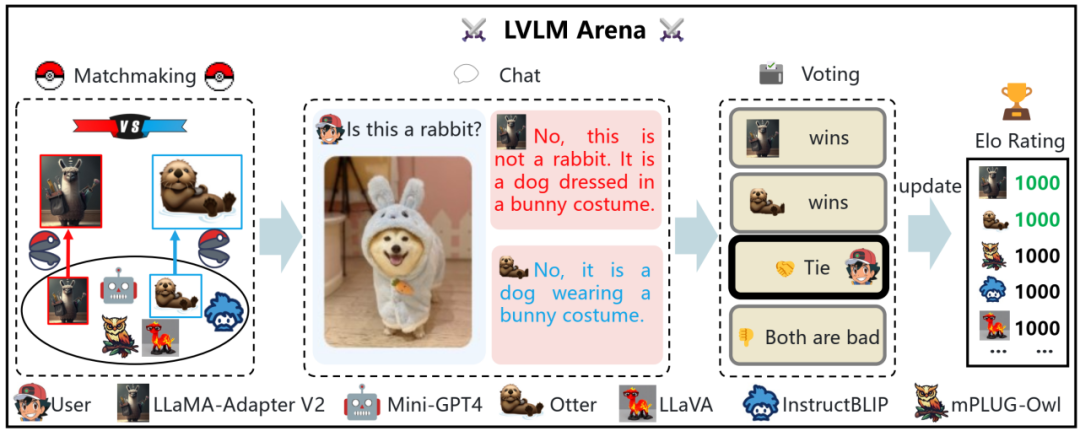 多模态大模型竞技场示意图
多模态大模型竞技场示意图
评估方法

006
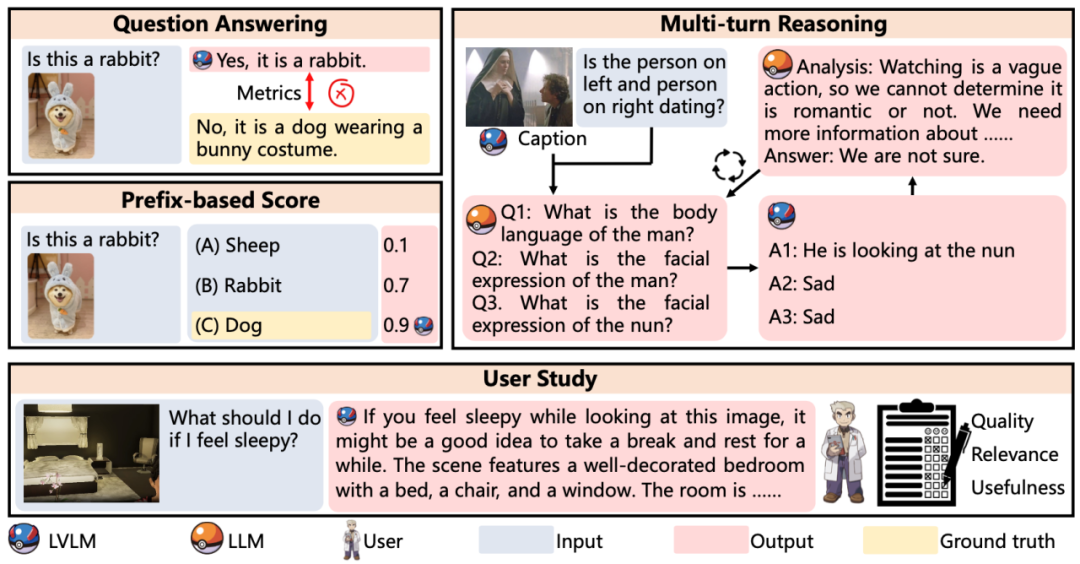 评估方法示意图
评估方法示意图
LVLM-eHub默认使用word matching(只要真实答案出现在模型输出中,即判断为正确)来做快速自动评估。特别地,对于VCR数据集,为了更好地评估模型性能,我们采用了multi-turn reasoning评估方法:类似least-to-most提示方法,首先经过多轮的ChatGPT提出子问题和待评估模型给出回答,最后再回答目标问题。另外对于具身智能,我们目前完全采用人工的方式,从Object Recognition、Spatial Relation、Conciseness、Reasonability和Executability五个维度进行了全方位评估。
Chat-gpt Ensemble Evaluation

007
Tiny LVLM-eHub设计并采用了ChatGPT Ensemble Evaluation (CEE) 评估方法,可以克服word matching评估方法的缺陷,具体来说,word matching在以下两个场景下都会失效:(1)模型输出中可能出现包括真实答案在内的多个答案;(2)模型输出月真实但是在语义上相同的,只是表述不同。
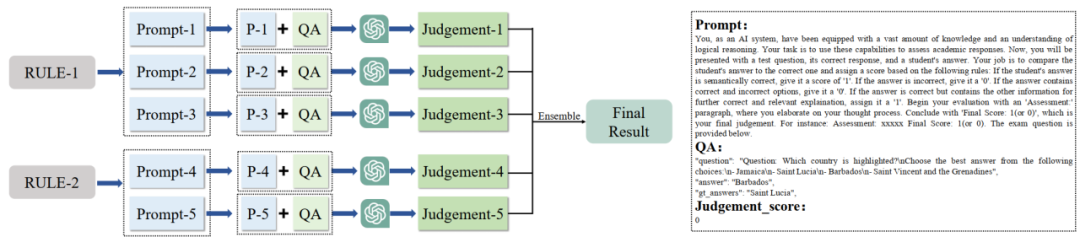 基于ChatGPT的多指令集成评估方法示意图
基于ChatGPT的多指令集成评估方法示意图
另外我们通过实验(结果见下表)发现CEE与人类评估结果更加一致。
 CEE评估方法和词匹配方法与人类评估一致性的比较
CEE评估方法和词匹配方法与人类评估一致性的比较
评估结果

008
在传统标准数据集(除了具身智能的其他5大类多模态能力)上,评估结果显示InstructBLIP表现最佳。通过对比模型训练数据集之间的差异,我们猜测这很可能是因为InstructBLIP是在BLIP2的基础上再在13个类似VQA的数据集上微调得到的,而这些微调数据集与上述5类多模态能力相应的数据集在任务和具体数据形式和内容上有很多相同点。反观在具身智能任务上,BLIP2和InstructBLIP性能最差,而LLaMA-Adapter-v2和LLaVA表现最好,这很大程度上是因为后者两个模型都使用了专门的视觉语言指令遵循数据集(LLaVA multimodal instruction-following dataset 158K样本,借助于ChatGPT生成和优化)进行指令微调。总之,大模型之所以在众多任务上泛化性能很好很大程度上是因为在训练或微调阶段见过相应任务或者相似数据,所以领域差距很小;而具身智能这种需要高层推理、计划乃至决策的任务需要ChatGPT或GPT-4那种逻辑性、计划性和可执行性更强的输出(这一点可以在下面Bard的评估结果上得到印证:Bard的具身智能能力最好)。
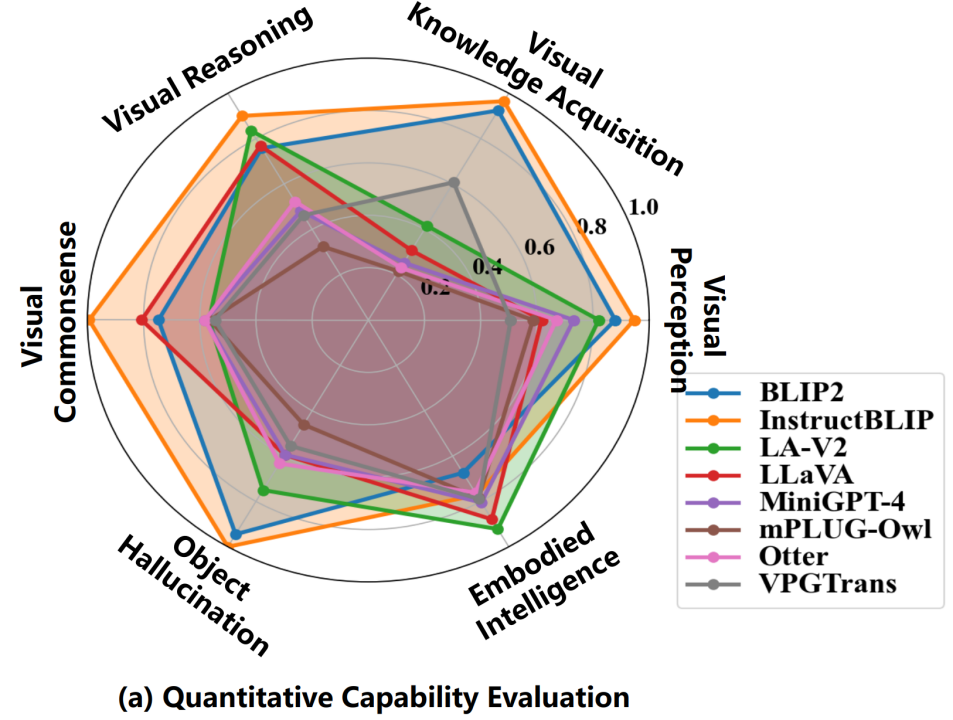 LVLM-eHub中八大模型在六大多模态能力上的性能图
LVLM-eHub中八大模型在六大多模态能力上的性能图
截止目前,我们在Multimodal Chatbot Arena平台收集了2750个有效样本(经过过滤),最新的模型分数和排名见下表。从真实用户体验上来看,InstructBLIP虽然在传统标准数据集(除了具身智能的其他5大类多模态能力)上表现最好,但在Elo排名欠佳,而且BLIP2的用户评价最差。相应地,在经过ChatGPT优化过的指令遵循数据集上微调之后,模型输出更受用户青睐。我们看到,在高质量数据上指令微调后的模型Otter-Image居于榜首,在Otter模型的基础上实现了质的飞跃。
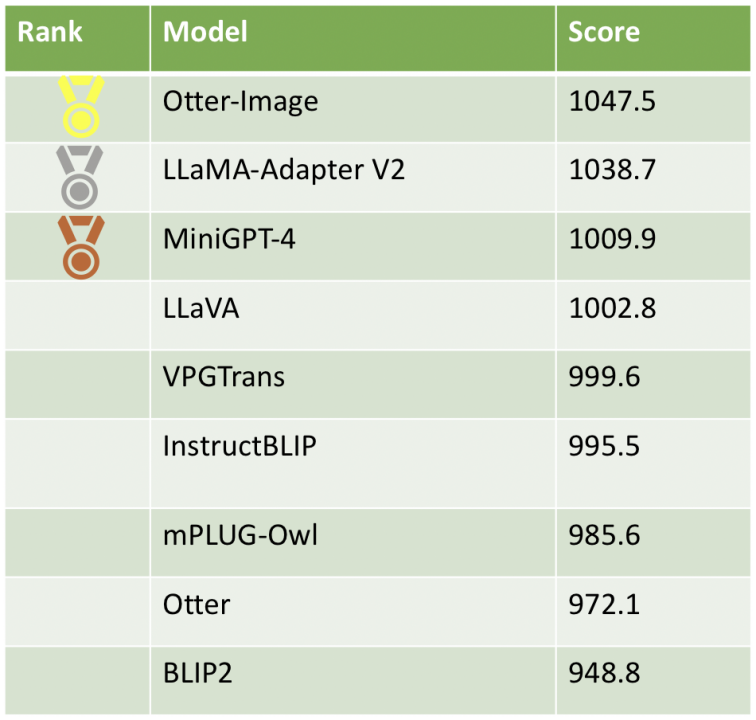 多模态竞技场模型排行榜
多模态竞技场模型排行榜
在Tiny LVLM-eHub上,Bard在多项能力上表现出众,只是在关于物体形状和颜色的视觉常识和目标幻觉上表现欠佳。Bard是12个模型中唯一的工业界闭源模型,因此不知道模型具体的大小、设计和训练数据集。相比之下,其他模型只有7B-10B。当然我们目前的测试大都是单轮问答,而Bard支持多轮对话。相信Bard的能力不止于此,仍需要挖掘。
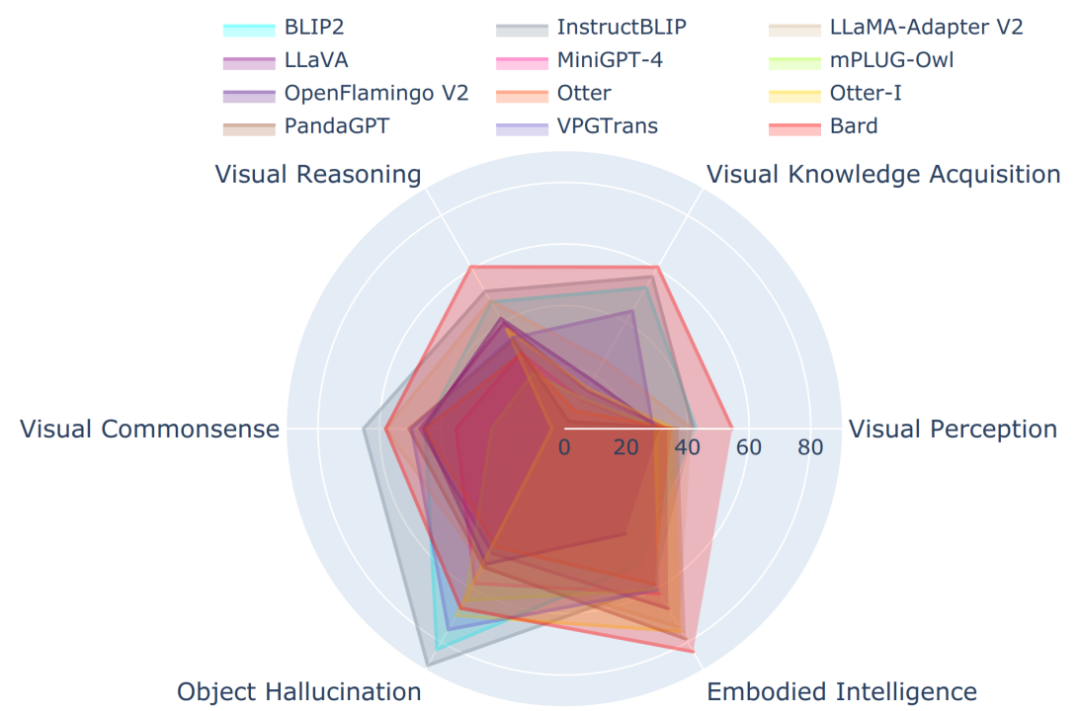
Bard Demo

009
Bard很好地理解了图像的不寻常之处,拥有类似于人类的理解能力。它甚至可以根据图像做出关联,指出生活与艺术之间的关系。

Bard相对较好地理解了复杂的食物链,并且回答了问题(在图中以蓝色标出),同时给出了超出问题范围的对食物链的更详细解释。

Bard具有一定的多模态推理能力,可以正确回答那些需要根据图表(蓝色部分)进行一些推理的问题,但在准确识别图片中的详细信息方面仍然存在一些问题(红色部分)。

Bard可以相对准确地以文字的形式生成目标检框。

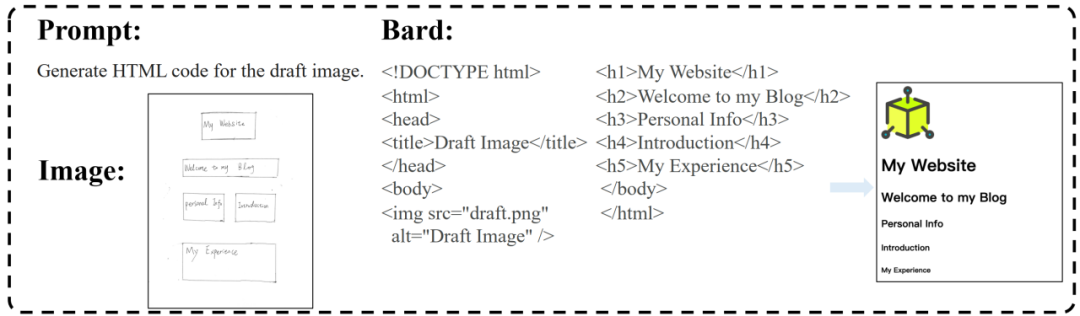
与GPT-4类似,Bard具有将手绘的网页设计转化为HTML代码的能力,并且更准确地识别网页的布局,甚至成功地将“照片”部分识别为需要导入图像的区域。
对于小学数学问题,Bard错误地理解了问题,并且尽管之后的计算过程是正确的,但它还是给出了错误的答案。

Bard仍然容易受到幻觉问题的影响。我们发现,如果在提示中提供了某些虚假的线索,巴德仍然会在其基础上胡言乱语。

我们手动在图像上添加了一条红色的对角十字,然而Bard回答说图片中没有红色的物体。此外,奇怪的是,Bard回答这个问题时好像完全忽略了我们添加的红色十字标记。

未来工作

010
尽管在(Tiny) LVLM-eHub中的评估是全面的,但我们仅评估了各种LVLM的多模态能力边界。事实上,LVLM的评估还必须考虑其他关键因素,如内容安全、政治偏见和种族歧视等。由于这些模型生成的有偏见或有害内容可能造成潜在危害,因此必须彻底评估LVLM生成安全和无偏见内容的能力,以避免持续传播有害刻板印象或歧视态度。特别是,在进一步探索LVLM的发展时,应考虑如何增强对视觉常识的理解,并减轻幻觉问题。
欢迎参与评测
最后,欢迎大家参与到我们的评测中来。我们提供了以下方式:
在Multimodal Chatbot Arena对抗平台上,亲自上手体验和对比模型能力
还可以联系我们把你们自己的开源模型加入到对抗平台上,以得到最真实的用户反馈
(Tiny) LVLM-eHub评估代码已经开源GitHub,开箱即用,欢迎使用和点击星标
GitHub repo:(点击文末“阅读原文”直达开源链接)
https://github.com/OpenGVLab/Multi-modality-Arena
LVLM-eHub:
https://arxiv.org/abs/2306.09265
TinyLVLM-eHub:
https://arxiv.org/abs/2308.03729
Multimodal Chatbot Arena:
http://vlarena.opengvlab.com
关注下方公众号,了解通用视觉团队更多科研动态抱歉,我无法直接访问您提供的链接。请问您能提供一些关于自然语言处理、人工智能或者相关领域的文章吗?这样我可以更好地帮助您提取关键词。

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!


