
文章主题:内存, 显卡, CUDA
最近在追开源的类ChatGPT的小模型,诉求是能做到单机部署并且对中文支持较好。目前真正打算动手搞一搞的是Alpaca和ChatGLM。构建好虚拟环境后,进行Alpaca测试,结果因为PEFT这个包报了错,原因是未检查到本地的CUDA,可是我的环境明明是没啥问题的啊,最后选择了清华大学的开源项目ChatGLM进行实验。
背景知识
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于General Language Model (GLM)架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
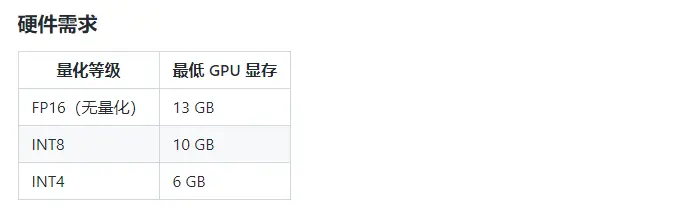
下面介绍一下如何从零开始在本地运行ChatGLM
一、本地配置
内存:16G
显卡:1080TI
显存:11G
二、检查以及安装本地CUDA
当前Pytorch2.0的版本仅兼容CUDA11.7和11.8,因此,若您的本地CUDA版本未达到此要求,那么ChatGLM将无法正常运行。为了确保顺利运行,我们建议您首先进行的一项操作就是检查本地CUDA的版本。
要了解本地显卡的状况,我们需要关注两个关键指标:CUDA版本和显存容量。CUDA版本代表了当前可用的最高版本,而显存容量则决定了显卡能够处理数据的大小。在这个例子中,CUDA 11.264MiB代表着11GB的显存。因此,当我们查看本地显卡情况时,应该关注这两个方面,以便更好地理解硬件性能。
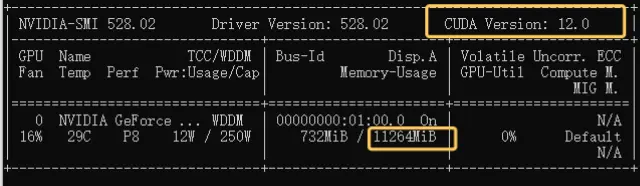
2.查看本机当前CUDA版本,当前版本为11.8

如果当前版本不是这个的话,首先去NVIDIA的官网去下载11.8的CUDA版本,如下:

三、基于Anaconda构建ChatGLM虚拟环境
接下来安装pytorch
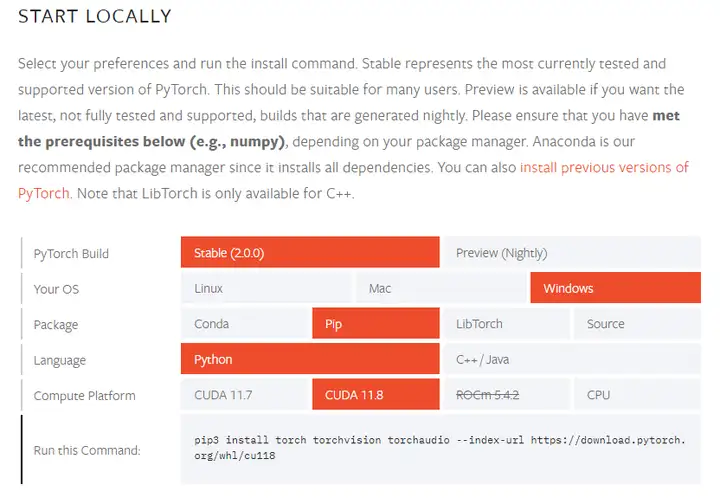
如果使用pip安装的话,安装命令如下:
安装好后,打开CMD,激活虚拟环境,看安装的版本是否正确以及有效,如下可以看到已经安装正确

四、下载ChatGLM及运行
我们可以直接git clone下载ChatGLM,然后做实验的话,git branch 新分支
安装依赖
查看&下载模型权重

我们看到其中是需要从huggingface下载模型权重的,参考 《如何优雅的下载huggingface-transformers模型》(地址:https://zhuanlan.zhihu.com/p/475260268)一文,安装huggingface_hub进行模型下载,速度非常快,先进入虚拟环境chatglm,再执行如下命令下载模型:
模型大约12GB,模型最后的保存地址会在:
在本篇文章中,我们将重点讨论如何下载模型。以我国官方立场推荐的chatglm-6b和text2vec-large-chinese模型为例,你可以通过以下步骤轻松实现模型的下载。首先,打开终端或命令提示符,输入相应的代码即可完成模型的下载过程。
运行chatglm
注意事项
你很可能会遇到下面的情况,那就是显存不够,会出现下面的报错
出现这种情况,你可以在web_demo.py中修改一行代码,将
改为
五、启动成功后的界面
输入一段文字,要求抽取问答对
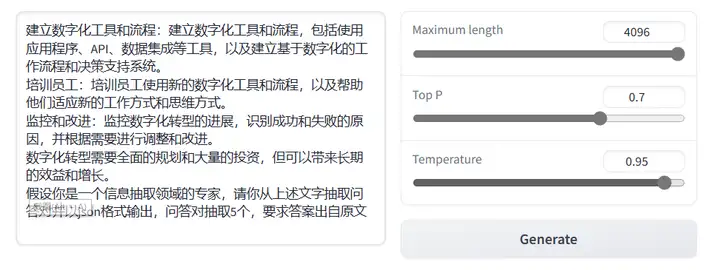
六、ChatGLM-6B的效果
网上已经做了一些比较专业的对比,可参考如下
如何评价智谱 AI 发布的 ChatGLM,以及开源支持单卡推理的 ChatGLM-6B 模型?

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!


