
文章主题:微调, 专业知识, 计算资源
在之前的教程中,树先生向我们展示了如何通过微调来构建一个专为垂直领域LLM设计的模型。然而,微调过程既要求专业知识,又涉及到大量的计算资源和时间。为了在各种超参数设置上训练多个模型并挑选出最优的一个,我们需要投入相当多的精力。此外,微调过程的动态扩展性较差,这意味着当我们添加或修改原有数据时,必须重新进行微调。总的来说,这样的过程对于非专业人士并不友好。

今天树先生教大家无需微调就能实现垂直领域的专业问答,利用 ChatGLM-6B + langchain 实现个人专属知识库,非常简单易上手。
技术原理
图示展示了项目的实现流程,该流程主要包括以下步骤:首先,加载相关文件;接着,读取并处理文本数据,进行文本分割和向量化处理;然后,将问句向量也进行向量化处理;之后,在向量空间中寻找与问句向量最为接近的top k个元素;接下来,将这些匹配到的文本(包括上下文和问题)整合到prompt中;最后,将生成的prompt提交给LLM模型以获取相应的回答。
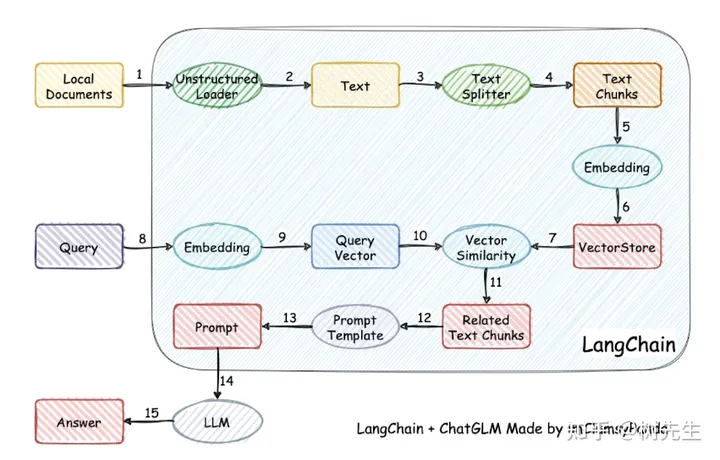

显然,该技术的核心是向量嵌入。它将用户的知识库内容通过嵌入存储在向量知识库中,并在用户提问时,通过向量相关性算法(如余弦算法)找到最适合的几个知识库片段。这些知识库片段与用户的问题一起构成了prompt,并提交给LLM进行回答。这种方法的优点在于它的简洁性和高效性,能够快速地找到与用户问题相关的信息,并为用户提供准确的答案。
更多关于向量 embedding 的内容可以参考我之前写的一篇文章。
使用场景
可以调整 prompt,匹配不同的知识库,让 LLM 扮演不同的角色
上传公司财报,充当财务分析师上传客服聊天记录,充当智能客服上传经典Case,充当律师助手上传医院百科全书,充当在线问诊医生等等等等。。。。
实战
这里我们选用 langchain-ChatGLM 项目示例,其他的 LLM 模型对接知识库也是一个道理。
准备工作
我们还是白嫖阿里云的机器学习 PAI 平台,使用 A10 显卡,这部分内容之前文章中有介绍。

项目部署
环境准备好了以后,就可以开始准备部署工作了。
下载源码
安装依赖
下载模型
参数调整
在模型下载流程完成之后,您需要对你的配置文件进行相应的修改。具体来说,在 configs/model_config.py 文件中,你需要对两个参数进行调整,即 embedding_model_dict 和 llm_model_dict。这是因为在模型的训练过程中,这两个参数扮演着重要的角色,它们决定了模型如何处理输入数据以及如何生成输出结果。因此,它们的设置对于模型的性能和效果有着直接的影响。
项目启动
Web 模式启动

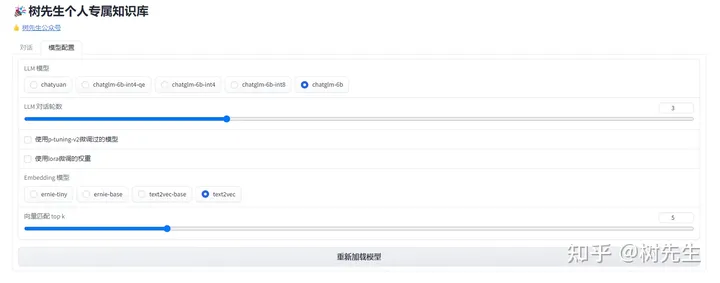
模型配置
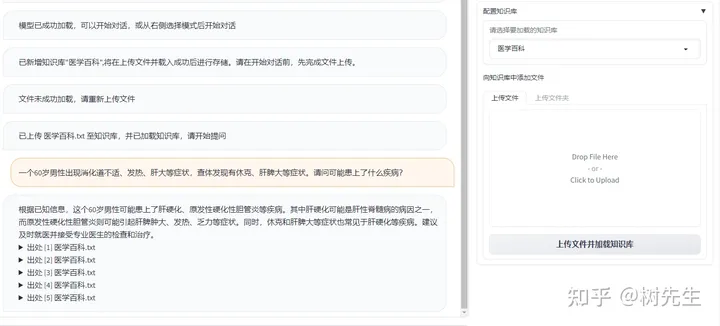
上传知识库
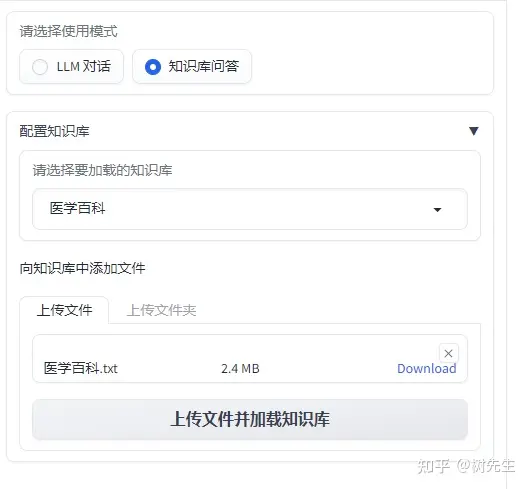
知识库问答
API 模式启动
命令行模式启动
改进
Gradoi页面的简洁性使其更适合作为后台管理员的操作界面,然而若将其开放给用户使用则显得并不适宜。为此,我国知名技术专家树人在Chatgpt-Next-Web项目的的基础上,进行了一系列适应性调整,成功研发出一款专为用户打造的本地知识库前端。
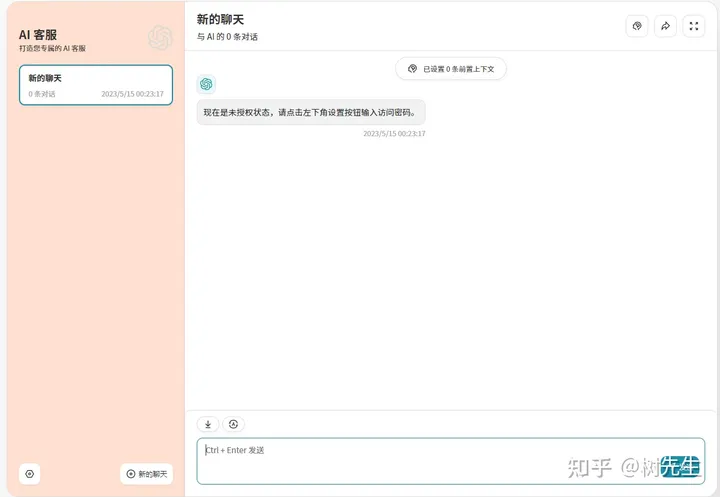
授权码控制
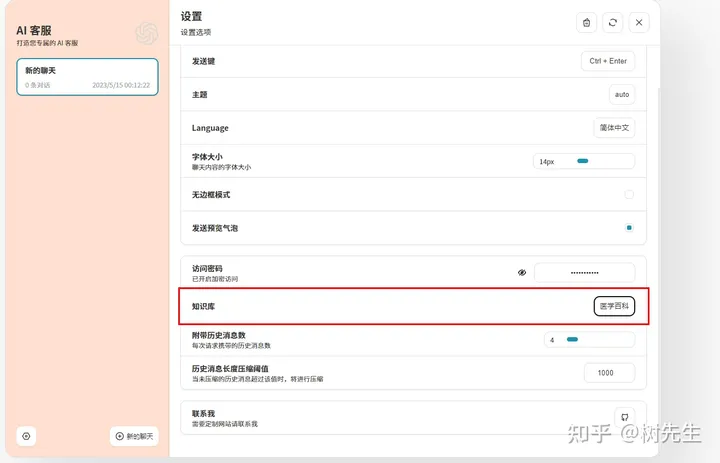
选择知识库
基于知识库问答
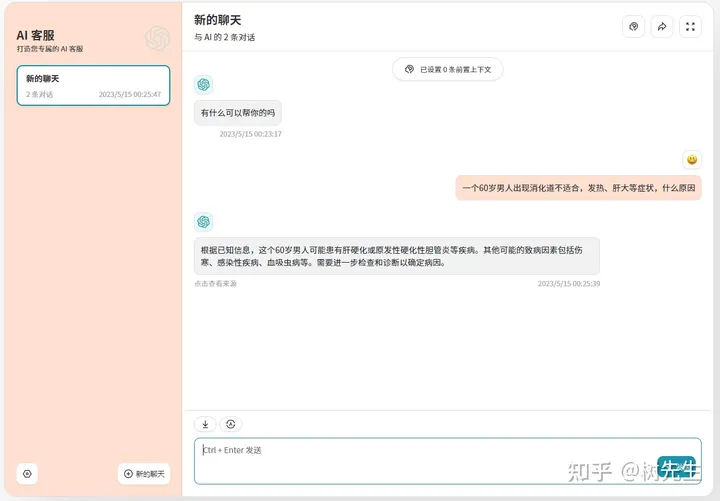
显示答案来源

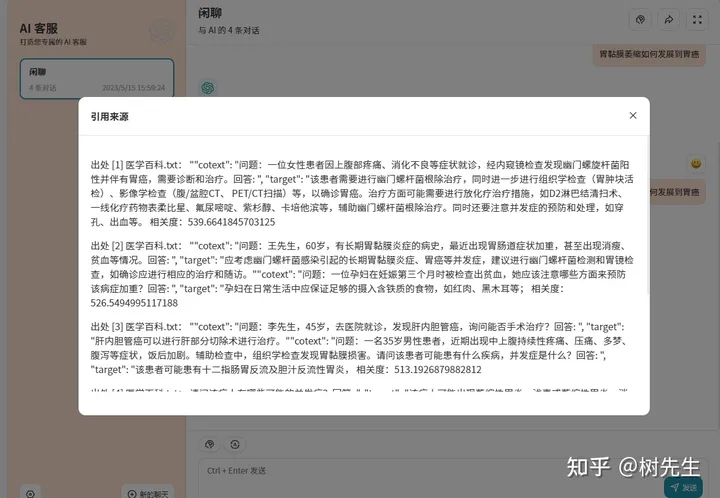
请注意,此篇文章中所引用的知识库系我本人所创建的原版知识库,因此在展示数据来源方面可能存在一定的不足。为了确保文章质量,建议在发布之前对其进行一定程度的数据治理和优化。
感兴趣的朋友可以私信我,我会免费给大家提供知识库体验地址。
微调, 专业知识, 计算资源

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!


