
文章主题:AI, ChatGPT, GPT-4, 模型训练
从一个AI学习者的视角来看待ChatGPT,站在业界巨匠的肩头之上探索各种技术细节。作为一名学术界的小型工匠,我的职责就是修复和补充各位专家所阐述的各项技术,如果您希望对这些技术有更深入的理解,请务必阅读文末的正统专家们所撰写的学术论文。
全文阅读时长:15min
背景介绍
ChatGPT太牛批引起了全球关注,不光卷AI圈内人,还连带卷了圈外人。
发展现状
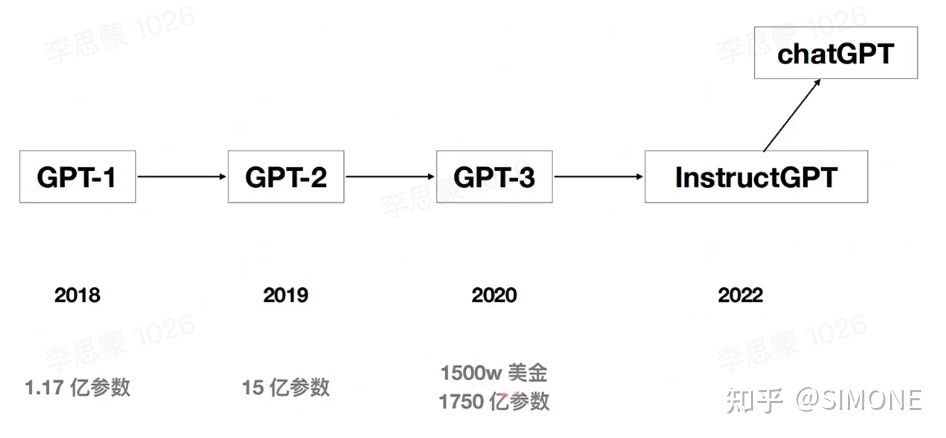
ChatGPT和去年公布的InstructGPT是一对姊妹模型,它们有时被称作GPT-3.5。这两款模型是在GPT-4发布之前的预热版本,因此,它们具有重要的历史地位。据传,尚未正式发布的GPT-4是一款多模态模型,这意味着它将能够处理多种类型的输入,包括文本、图像、音频等。这将使得GPT-4的输出更加丰富多彩,为用户带来更为丰富的体验。对于ChatGPT而言,它的能力也将得到进一步提升,不仅能够理解并生成文本,还可能能够理解并处理其他模态的信息,从而使得其回复内容更加生动有趣。
模型架构
ChatGPT 和 InstructGPT 在模型结构和训练方法上具有高度相似性,它们均采用了指令学习和人工反馈强化学习(RLHF)这两种技术进行模型训练。唯一的区别在于数据收集方式的差异。尽管 ChatGPT 的论文和代码细节尚未公开,但我们可以通过 InstructGPT 来推断 ChatGPT 的模型和训练方面的具体细节。
核心技术
指令学习(Instruct learning):其实就是prompt learningRLHF(Reinforcement Learning from Human Feedback):基于人工反馈的强化学习训练步骤
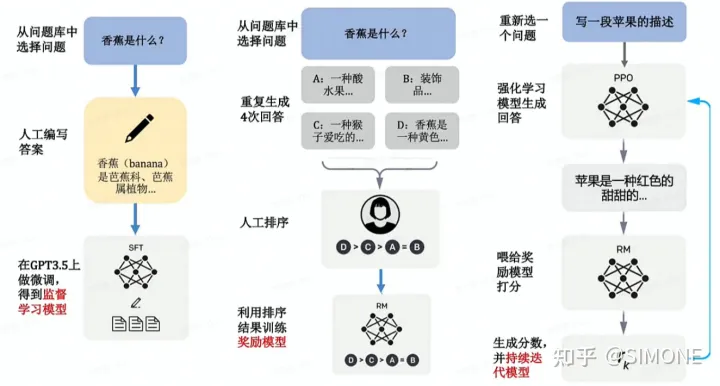
在本篇文章中,我们将深入探讨 InstructGPT/ChatGPT 的训练过程,并将其拆分为三个主要阶段:SFT、RM 和 PPO。接下来,我们将逐一剖析这些阶段的原理及实施方法。
1.SFT
ChatGPT 是一个对话模型,其工作原理依赖于一种名为SFT(Supervised FineTune)的技术。SFT是一种有监督微调技术,旨在对GPT-3进行优化,以便更好地生成人类喜欢的答案。具体而言,SFT利用人类提供的偏好数据集,对 GPT-3 进行训练,从而使其能够更好地理解人类的语言和意图,并相应地生成更准确的答案。因此,SFT是实现高质量对话的关键之一。
GPT原本是使用互联网海量语料库训练的大模型,但互联网上的语料非常杂乱,不一定是人类想要的答案,GPT依靠此数据生成的答案正确性和有用性不能保证。在此基础上,对数据集优化,把人们喜欢的答案喂给已经训练好的GPT再次微调,这样模型可以对齐人的思考模式得到提升。可以理解成升级后的模型只订阅人们喜欢的内容。对话机器人的雏形已经生成,它可以根据问题生成一系列的答案,但是缺陷是它不具备人的判断能力。机器生成了答案A,B,C,D,但哪个是想要的呢的答案呢?由此,引入RM奖励模型。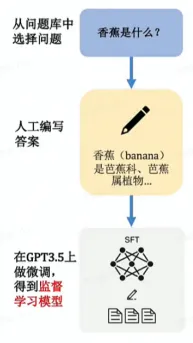
2.RM
强化学习(Reinforcement Learning,简称RM)是一种先进的机器学习方法,其主要目标是通过不断与环境的交互来优化模型的性能。相较于传统的模型训练方式,RM能够为模型提供关于其生成内容质量的反馈,而非仅仅告知如何改进,这为模型提供了更大的探索空间,从而提高了其泛化能力。以下是实施RM的具体步骤:
首先,模型根据问题生成多个答案。人工对给定的答案进行排序和打分。机器通过人工打分的数据训练奖励模型,可以预测用户更喜欢哪个模型输出。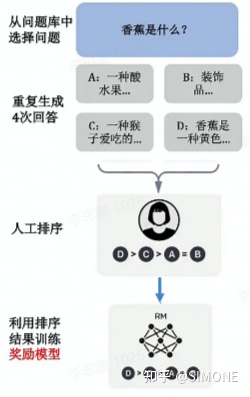
一个更通俗的例子,讲解SFT和RM的工作方式和区别:
SFT用「人工标注」的问题回答数据,并用监督性学习技术训练的自动回答问题的模型。RM用「人工打分」的问题回答数据,并用强化学习技术训练的自动给回答打分的模型,SFT是通过「人工标注」解决答案「有没有」的问题,RM则通过「人工打分」来解决答案「好不好」的问题。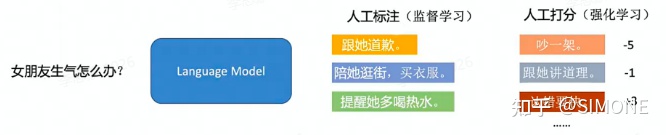
3.PPO
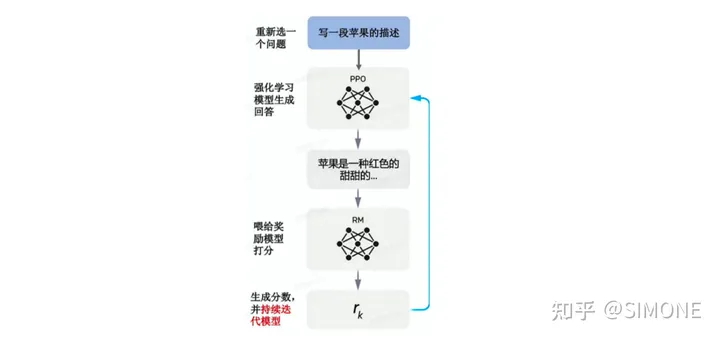
在此阶段,我们将之前训练好的SFT与RM两个模型融合,采用PPO(Proximal Policy Optimization)算法对SFT训练出的生成模型进行微调。然后,将生成的答案输入到RM评分模型中,根据RM的损失函数持续优化生成模型。这一过程的具体步骤包括以下几个方面:
由第一步fine-tune后的SFT模型来初始化PPO策略模型,由第二部生成的RM模型初始化价值函数。从PPO数据集中随机采样一个prompt,并通过第一步的PPO策略模型生成输出结果answer。对prompt和answer,带入RM模型计算奖励值reward。利用reward来更新PPO策略模型参数。重复2~4步,直至PPO策略模型收敛。近两年来,强化学习和预训练模型成为人工智能领域最热门的研究方向之一。尽管之前有许多科研工作者表示,强化学习并不适合应用于预训练模型,主要原因是难以通过模型的输出内容建立有效的奖励机制,但近期 InstructGPT/ChatGPT 的出现改变了这一局面。该算法通过融合人工标注,成功地将强化学习融入到预训练语言模型中,这无疑是该研究算法的最大创新点。
参考文献
https://arxiv.org/pdf/2203.02155.pdf
https://zhuanlan.zhihu.com/p/590311003
AI, ChatGPT, GPT-4, 模型训练



