
文章主题:开源, 大模型, 编程版本, Code Llama
在成功推出开源可商用的大模型Llama 2之后,Meta近日正式发布了该模型的编程版本Code Llama。这一举措极大地补足了之前在代码任务上表现不足的缺陷,从而进一步缩小了与闭源的GPT模型的差距。此外,Code Llama的测试效果甚至达到了GPT-4的水准,展现了其强大的实力和潜力。
在我国知名的开源与闭源模型提供商Code Llama发布新产品的两天前,OpenAI却抢先一步,推出了其GPT-3.5模型的微调功能。这一举动,无疑让业界感到惊讶,因为这不仅满足了开发者和企业根据自身需求定制模型的需求,更是在一定程度上挑战了现有的竞争格局。就目前来看,这两大模型在开源和闭源领域的综合实力上的较量,似乎正在变得更加激烈,甚至让人感觉到了一丝火药味。
编程作为大型语言模型最主要的应用方向之一,同时也是当今众多科技产品和服务的核心要素,对于提升其性能和改善用户体验具有关键作用。
在本篇中,我们将探讨的是Code Llama,这是一款经过特殊设计的编程语言模型。它是在Llama 2的基础上,通过特定的代码数据集进行深入训练而得出的。这使得Code Llama具备了处理多种编程语言的能力,包括C、Java、Python、PHP、Typescript(即JavaScript)以及C++等。
Code Llama是一款极具实用性的工具,对于编程领域的专家和初学者而言,它的价值不可忽视。无论用户采用何种编程语言——不论是专业的编程语言还是日常生活中所使用的普通话——Code Llama都能轻松理解并根据用户的实际需求生成与之匹配的代码,同时还能提供相关解释。这一特性极大地降低了编程的门槛,提高了开发效率。
多版本模型覆盖更多特定场景需求
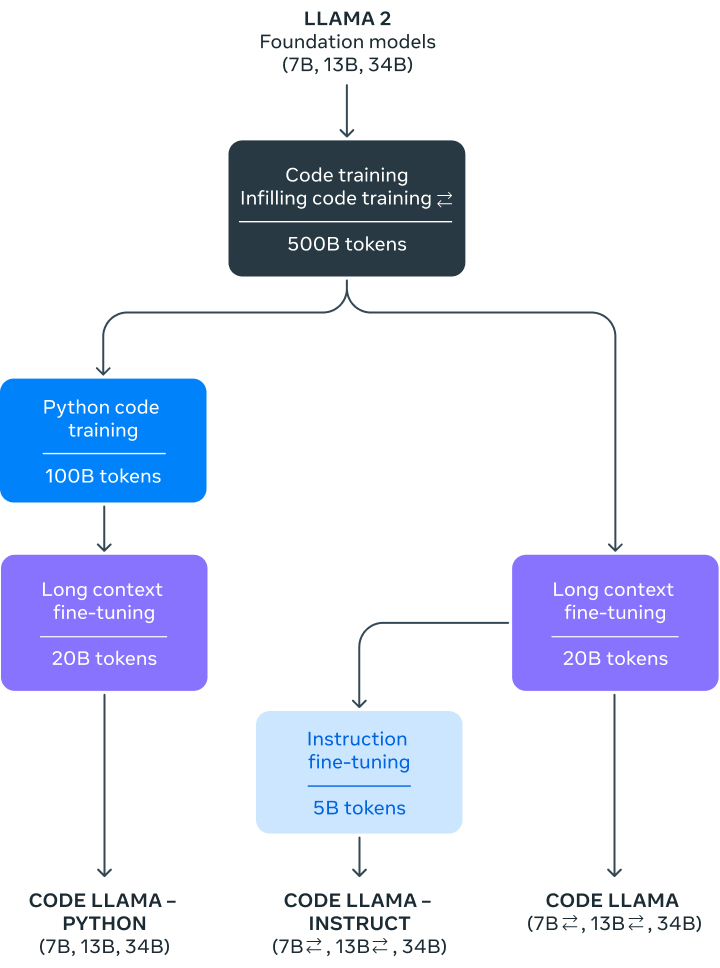
在Meta的官方博客中,我们可以看到Code Llama这款工具被划分为三种不同的版本,分别为7B、13B和34B,它们各自对应着不同的服务需求和延迟标准。值得注意的是,无论是哪个版本, Code Llama所采用的训练方法都是相同的,即利用500B tokens的代码相关数据进行训练。
图源:Meta
在众多7B参数模型中,选择最小的一款,能够在单个GPU上高效運行,展现出卓越的响应速度,特别适用于对低延迟有严格要求的场景。然而,如果相较于更大规模 model,它在代码生成或理解的精确性上稍逊一筹。最大规模的34B模型则具有无与伦比的编码辅助能力,能在复杂编程任务中游刃有余,但其对计算资源的需求较大,延迟也相对较高。在中等规模的第13B参数模型中,性能与延迟之间的平衡被恰到好处地实现。此外,7B和13B模型经过中间填充(fill-in-the-middle,FIM)功能训练,能够理解在现有代码中插入新代码的技巧,因此,它们可以直接应用于自动代码补全等任务,无需额外的设置或训练。
Code Llama是一款功能强大的文本处理工具,它能够一次性理解并记忆高达10万token的上下文信息。其卓越的文本处理能力对于处理大型代码库或者长篇文章都具有极大的帮助。举例来说,当程序员需要处理大量的代码时,可以整个代码片段的形式将其交给Code Llama进行处理。
值得一提的是,为了满足更多特定需求,Meta还进一步针对Python和自然语言指令微调了两个Code Llama的变体,分别称作Code Llama-Python和Code Llama-Instruct。
Python是目前最受欢迎的编程语言之一,在多个领域有着广泛应用,特别是在数据科学、机器学习等领域。一个专门针对Python的模型能更准确地生成和理解Python代码,提高模型在处理相关任务时的性能。
另一个子版本Code Llama-Instruct更注重理解自然语言指令,非常适合那些不是很熟悉编程但又有这方面需求的用户。这个版本更容易理解用自然语言给出的指令,也就是更适合非专业用户,除了可以用于代码生成,也能胜任其他与代码相关的自然语言处理任务,如代码注释或文档生成。
通过提供更多垂直的子版本,Code Llama模型能够覆盖更广泛的用例和人群,满足不同场景下的特定需求,更容易获得竞争优势。
不过,Meta也有在博文中说明,由于Code Llama更专注于代码任务,因此并不适合作为聊天或写文章等日常语言任务的基础模型,它主要是为了帮助人们编程或处理代码问题而设计的。
性能和安全性双领先
而有关Code Llama的具体性能,在多个代码基准测试中,Code Llama达到了开源模型中最先进的性能。Code Llama所有模型在MultiPL-E上都优于其他公开可用的模型。34B参数版本在HumanEval上得分为53.7%,在MBPP上得分56.2%,这与ChatGPT(GPT 3.5)相当,优于其他所有开放解决方案。

图源:相关论文截图
在安全性上,Meta采取了许多措施,为做评估,研究者特意用一些指令请求恶意代码,测试Code Llama是否会生成不好的输出。并对比ChatGPT做了同样的测试。结果显示,Code Llama更不容易生成有问题或者有害的代码。
Meta还发表了一篇详细介绍Code Llama的论文(题为Code Llama: Open Foundation Models for Code),披露了Code Llama开发的细节以及如何进行基准测试等信息。
值得一提的是,在Meta发布的论文中出现一个名为“Unnatural Code Llama”的模型(见上图),各项评分都非常之高,但该模型只在论文中一闪而过,Meta并未提及,或许后续Code Llama会迎来进一步增强。
开源, 大模型, 编程版本, Code Llama



