
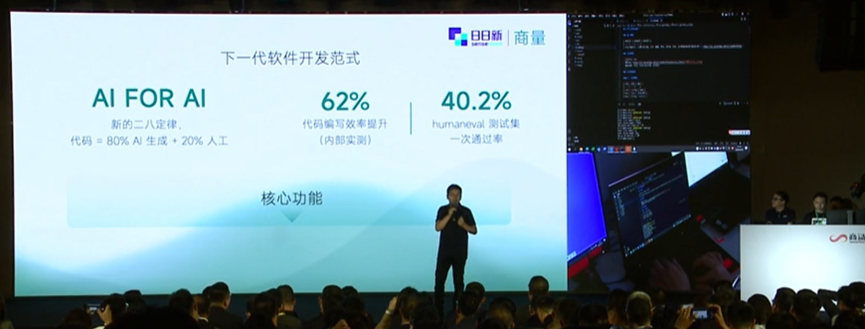
文章主题:AI大模型, 参数量, 数据量, 计算量

摘要
■ 投资逻辑及建议
行业观点:
商汤是我国领先的人工智能企业,业务范围涵盖智慧商业、智慧城市、智慧生活、智慧汽车四大板块,技术能力覆盖感知智能、自然语言处理、智能决策、智能内容生成等关键领域,同时公司还提供AI芯片、AI传感器及AI算力基础设施。公司于2023年4月10日举办技术交流日,发布大模型“日日新SenseNova”及其衍生产品,包括自然语言处理领域的“商量SenseChat”、文生图“秒画SenseMirage”、数字人平台“如影SenseAvatar”、空间3D模型“琼宇SenseSpace”及“格物SenseThings”。
▪ “商量SenceChat”模型规模达1,800亿参数,支持问答、生成、超长文本知识理解等全面中文语言功能,同时模型具有较强的多轮对话能力,可通过互动式引导实现逻辑推演,并不断精进判断力与创作智能。商量模型可应用于文案生成、辅助程序开发、医疗辅诊等领域。
▪ “秒画SenseMirage”模型拥有10亿参数,功能可类比海外图像生成应用Midjourney,支持6K高清图像快速生成,并可根据指令调整绘画风格。
▪ “如影SenseAvatar”平台支持AI数字人动作表情生成、AI文案生成、AI跨语言文稿生成等功能,可应用于直播带货、AI换装、视频制作等,可以大幅节约零售场景的销售费用支出。
▪ “琼宇SenseSpace”与“格物SenseThings”分别支持场景生成和物体生成。其中,“琼宇”可实现城市场景厘米级精度重建;“格物”支持复杂结构物体复刻、光照精准复刻以及物体材质还原,可应用于商业广告、影视作品创作、虚拟场馆展示等。
目前商汤已面向政企客户开放“日日新”模型API,有望带动AIGC技术加速落地。此外,商汤SenseCore大装置可提供AI算力支撑,公司临港AIDC拥有2.7万片GPU,能够提供5,000PFlops算力,可支持20个千亿级参数大模型同步训练。SenseCore大装置于2022年开始赋能行业客户的模型开发,目前已累计支持超过10个客户大模型训练项目。
投资建议:
商汤作为我国人工智能行业龙头公司,在算法、算力领域均处于行业顶尖水平,本次“日日新”大模型产品及API发布有望带动AIGC技术快速落地,并催生更多训练算力需求,有望为商汤带来增量收入。建议关注商汤、科大讯飞等头部AI公司。
风险提示:
海外基础软硬件使用受限,应用落地不及预期,行业竞争加剧风险。
正文
商汤科技CEO徐立博士开场演讲:
当前,AI大模型备受瞩目,业界习惯用大模型的参数量来评估其性能。有的甚至达到千亿参数,甚至万亿参数。然而,要全面了解AI大模型的能力,仅依赖参数量是不够的,我们还需要结合训练数据量进行分析。事实上,AI模型的能力应当由模型参数与训练数据量的结合来衡量,这才是评价AI大模型真实能力的唯一标准。在计算资源日益紧张的今天,我们需要用一种新的方式来衡量算法和算力的价值。那就是将参数量与数据量相乘,得出一个新的计算量指标。由于总的计算量是有限的,因此在有限的计算量下,我们需要合理分配资源,将计算资源分配给参数或训练数据。这样,我们才能更准确地衡量AI大模型的能力,使其在实际应用中发挥更大的作用。

在过去两三年中,大模型参数量几乎每年翻10倍的增长,最新的模型如GPT4可能达到上千至上万亿的参数量。在数据量方面,GPT3的公开数据显示,其大约处理了5,000亿token,目前已知最大自然语言模型的训练量达2万亿token,而人类高质量语言数据总存量大约在9万亿token,因此很快会面临高质量语料被消化完的局面。

人类80%的信息是通过眼睛来获得的,人脑中处理视觉和处理语言的神经连接个数的比例是10:1,也就是虽然有150万亿的参数,但其中大部分是处理视觉的,少量的是处理语言的,语言是对这个世界的一种高浓度的压缩表达。通过语言能够很快了解世界,但是一定会有更多的信息从视觉当中获得,商汤致力于用大的通用的视觉感知模型将非结构化数据转化为结构化数据,已经在过往积累了大量的有人的反馈的视觉类的信息,这类信息如果再输入到更大的网络中,形成多模态的输入,可能会给带来一个完全不一样的输入基础。
在未来的探讨中,我们将更加关注大型模型的计算性能。如图所示,横坐标代表处理的数据规模,纵坐标则是模型的参数数量。它们之间的表现关系,即所占用的计算资源,正是模型能力的直观反映。具体来说,当模型的计算能力增强时,其在右上角的通用性也会相应提升,这表明通用性与计算能力之间存在着密切的联系。因此,在评估模型性能时,我们应当将计算资源的占用情况纳入考虑,这将有助于我们更全面地了解模型的能力。
在计算资源有限的情况下,我们需要更加灵活地分配计算资源。在这种情况下,将更多计算资源分配给数据而不是仅仅给予参数是非常有必要的。这是因为网络可能还没有达到充分的训练状态,因此需要更多的数据来提高其性能。通过这种方式,我们可以更有效地利用有限的计算资源,从而提高模型的准确性和泛化能力。

商汤临港大型智能计算中心具备输出5000p的算力以及500p的国产化算力,这使其成为我国乃至整个亚洲最大的智算中心之一。该中心能够支持20个拥有千亿规模参量的模型以千卡并行的方式运行,同时也能应对稠密5000亿参数的训练需求。除此之外,商汤临港大装置还允许将模型部署到平台上,实现大规模增量训练,并且成功地将增量训练成本降低了90%。

商汤推出大模型体系:“日日新”:

“日日新”模型体系融合了公司自然语言的大模型、文生图的大模型、感知类的大模型和模型增量服务。

1、自然语言大模型:SenseChat“商量”
自然语言大模型“商量”:模型拥有1800亿参数,支持长文本理解(支持上传PDF文件)、多轮对话、辅助编程、手写OCR等功能,并现场演示在线问诊应用。

自然语言大模型的能力在于通过多轮互动,挖掘出解决问题的方案,提升逻辑能力,实现长文本理解,同时还带有知识更新的模块,能使得它生成的信息更加准确。

“商量”的典型应用场景:
① 互动式对话生成
使用的时候是互动式的形式,不是一次性的问答,需要去提供输入,使其能够逐步的找到一些很好的适用于场景的内容。
②文本分析能力
支持长文本理解分析,现场通过上传法律文件进行演示,可以对大模型进行提问,实现文本分析。
③AI辅助编程
现场演示计算两个数的最大公约数,AI通过递归辗转相除法实现,又演示了判断两个数是否互为质数。
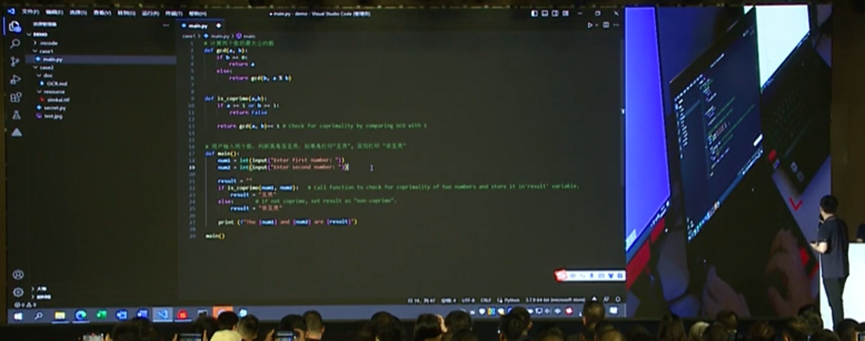
通过自然语言编程大模型的迭代和提升,可以大幅提升工作效率,尤其是对于企业级用户。

④实现手写OCR
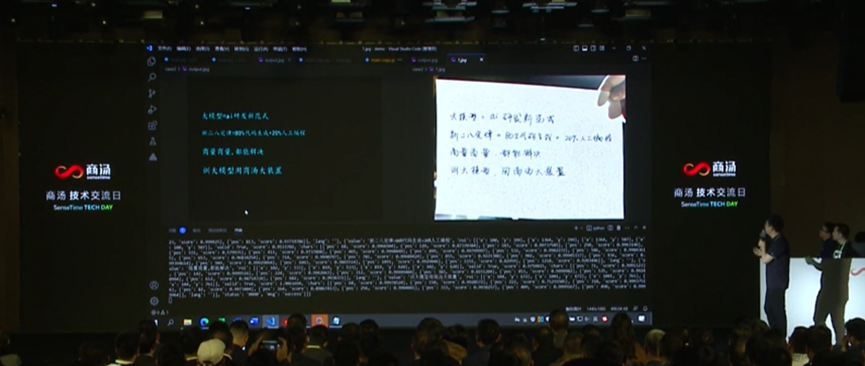
⑤医疗诊断
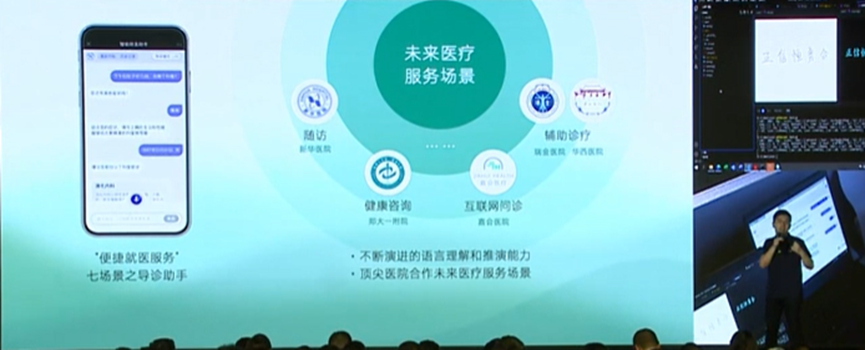
与AI医生进行互动,现场演示“熬夜带来身体变化的原因”,通过引导给予用户建议,大语言模型在未来医疗服务场景应用十分广阔。

2、AI内容生成平台:“秒画”

模型拥有超过10亿参数,可辅助提供提示词,并生成符合描述的图片,通过上传图片实例训练模型,使结果更精确。
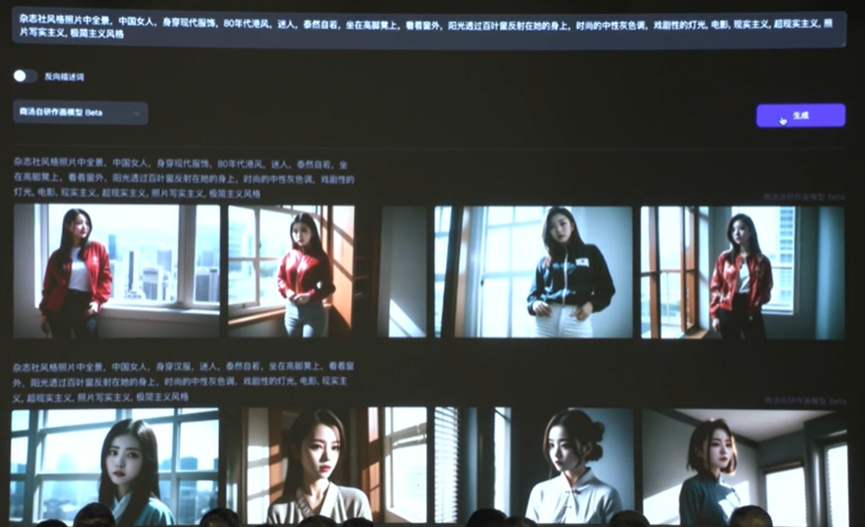
3、数字人生成平台:“如影”
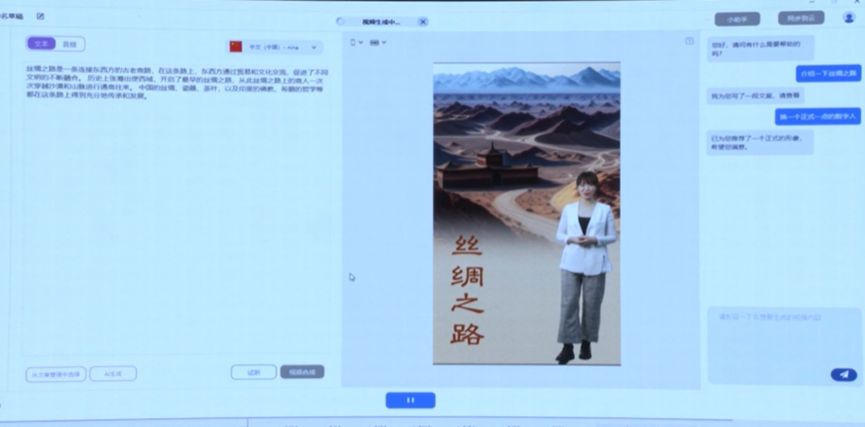
可根据5min视频创作属于自己的数字人,并进行AI换装、文案生成,可用于直播、营销视频生成等场景。

现场演示了生成介绍丝绸之路的短视频。
4、生成和复刻3D场景的平台——“琼宇”和“格物”

琼宇:如要构建一个100平方公里的城市场景,人工建模大概需要1万人*天,非常费时费力。但琼宇系统只需要两天,而且可以做到高逼真还原场景细节,并且实现厘米级别的重建精度。



琼宇涵盖的场景包括城市及园区的数字孪生,建筑物设计、影视创作,以及文旅和电商的一系列应用场景。
格物:传统中3D建模有几个难点:一是复杂物体的建模往往会牵连到背景;二是有光泽的物体无法分辨材质。公司的系统综合扫描效率提升了400%,把原来的成本降到了5%左右。


格物”的行业应用包括空间的创意设计,可以做家装、影视作品的嵌入、综艺视频中的物体摆件等。
3D场景做到了可实时交互,解决了行业中的难点。具体的应用场景如数字成生的直播间,可以实现产品生成和内容互动。

5、商汤算力中心大装置
除了服务日日新自研大模型体系之外,商汤大装置有超过7000张GPU算力,目前对外服务8家大型客户,用来训练他们超过千亿规模的大参数模型。

首席科学家王晓刚介绍商汤人工智能大模型的布局
随着ChatGPT的出现,通用人工智能掀起了一波人工智能技术的革命,以更高效的方式解决了海量开放式任务,带来了新的研究范式。
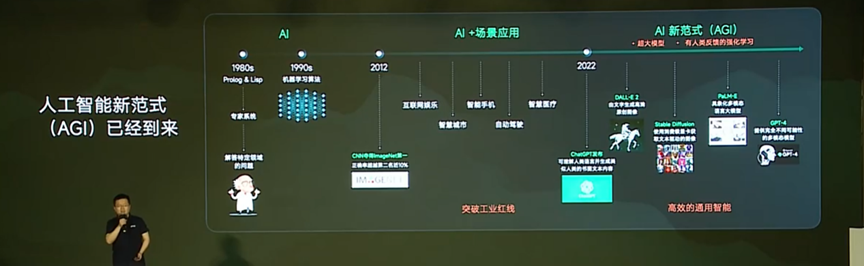
通用人工智能是可以输入提示词,输出多模态的数据。不需要对AGI的模型做出改动,只需要选择合适的提示词就能覆盖非常广泛的开放式任务。

在通用人工智能系统中不用预先给定任务,AGI模型就可以给出公司答案。
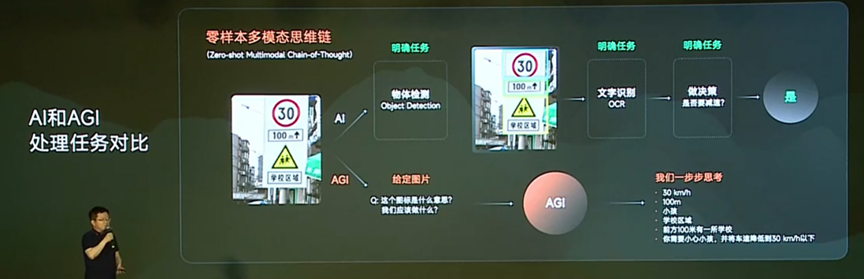
AGI模型能实现模型和人之间的互动,即人机共治。现有的AI系统实现了数据飞轮。而在AGI系统中,实现了智慧飞轮。
 fill=%23FFFFFF%3E%3Crect x=249 y=126 width=1 height=1%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
商汤赋能百业,有非常丰富的应用场景。
商汤实现了全栈的大模型研发能力,针对大模型底层序列做了很多优化,包括分布式训练优化、数据并行优化等。在此基础上,又针对超大模型做了技术优化。
高质量的大模型离不开数据支持,需要涵盖丰富场景的高质量数据。商汤和客户一起定义了丰富多样的任务,最近商汤也为社区贡献了基于真实感知、重建和生成的多模态数据集OmniObject3D。这个数据集包含190个类别,超过6000个物体的扫描数据。每个物体包含5条环绕的视频,支持多个任务。
商汤今日发布了“日日新”大模型,其实公司在在过去5年间,一直沿着该方向演进。2019年,公司发布了第一个10亿参数的大模型用于人脸识别的领域;2022年公司有了320亿参数的视觉模型,它是迄今为止最大的一个视觉模型;2022年年底公司已经有了10亿参数的AIGC的模型支持“文生图”和“图成图”;今天发布会上所展示的自然语言大模型是基于一个千亿参数的模型;前不久公司开源了书生2.5,它是一个30亿参数的多模态的模型,先前的积累也不断推动着公司训练一个更加强大的多模态大模型。
商汤未来的通用的人工智能的大模型体系里面,就包括了视觉感知、语言理解、内容生成和决策推理。大模型已经覆盖了公司的核心的业务,在智慧城市、智慧商业、智慧汽车、智慧生活4大板块里面有超过20个场景所实现了扎扎实实的落地。
2021年,在感知大模型的指导下,公司开发了BEV感知算法,它是基于环视的摄像头作为输入,将这些多个摄像头的感知的数据直接映射,在Waymo的挑战赛当中以绝对的优势夺得冠军。
在V2版本中,模型架构升级为书生2.5,实现时域更好对齐,在NuSences上得到了榜单第一名的成绩。
UniAD是首个实现感知决策一体化,端到端的自动驾驶的解决的方案,将环视的图片经过transformer映射到BEV的特征,同时进行目标的追踪、在线建图、预测目标的轨迹,并对障碍物进行预测,所以最终实现驾驶的行为。相比SOTA方法,效果得到显著提升。
公司未来还有非常大的潜力,利用多模态的大模型,去继续推动自动驾驶的技术。比如说可以用AIGC生成大量的困难的图片,用环视感知的数据及多模态的数据作为大模型的输入,实现感知决策一体化的集成。在输出中,通过环境的解码器去重构3D环境;通过行为解码器去预测规划路径;还有动机的解码器去解释自动驾驶的动机。在大模型的推动下,希望将来的自动驾驶的系统更加的安全可靠,能够有可解释性,也更加接近人的驾驶的行为。
通过大模型的助力,我们可以构建一个感知与决策数据的闭环系统。由于车辆端可以实时产生大量数据,这个系统可以持续地获取并处理这些数据。相较于人工标注的方式,大模型具备自动化处理能力,从而使得整个系统变得更加智能且高效。
在人工智能新范式的加持下,数据标注服务效率大幅提升,现在可以基于大模型实现自动的标注,成几百倍地去降低成本,进行快速迭代优化。
以书生2.5为例,在ImageNet分类任务上,在所有的开源的模型当中,是唯一一个Top one的准确率能够超过90%的,在业界知名的COCO的数据集检测的任务上,也是唯一一个能够突破65成绩的大模型。
基于感知模型,商汤的明眸提供自动数据标注服务,有12个模型,包括通用模型,还有一些专业领域的专业模型。通过上传图像,它就可基于大模型,自动进行数据标注、目标检测、属性识别。它涵盖了超过1000个不同的目标的类别,包括2D和3D,有超过10个行业里面的专有的专业大模型。
基于日日新的大模型的体系,公司开放了API,主要包括我自然语言生成的API、图片生成的API、通用视觉感知任务和标注的API。
前面大家也可以看到几个模型的能力包括在图片生成中,API可支持“文生图”和“图生图”,能够快速生成6k的高清的图像,用户还可以根据自己的需要,用API进行自助训练。自然语言生成的服务里面,支持的中文的多轮的对话、超长文本的理解的能力,而且它还可以不断的学习进化。标注服务和感知支持2D和3D的视觉的任务,能够极大提升效率,降低成本。
人工智能新的技术革命已经到来,商汤会继续加大在基础设施上的建设,重塑整个研发体系,也非常期待和客户、生态伙伴合作,投入到通用人工智能的时代大潮中。
往期报告
+AI行业系列深度
2.《AI系列深度之二:大模型时代,AI技术向效率提升演进》
3.《AI系列深度之三:ChatGPT训练及多场景推理成本测算》
4.《AI系列深度之四:AI掘金潮下的“燃料”,新场景催化数据采标需求加速释放》
5.《AI系列深度之五:“文心一言”发布,国内应用预计加速》
6.《AI系列深度之六:文心一言、GPT-3.5及GPT-4的应用测评对比》
7.《AI系列深度之七:不止于AI,探索AI+研发设计工业软件星辰大海》
8.《AI行业点评:重视GPT上线插件系统对入口型应用的重塑》
+
团队介绍
孟灿:07-14年就读于中南财经政法大学金融学院投资专业。曾任职于苏州高新创投、兴全基金、华创证券研究所。近4年一级市场TMT投资及4年以上二级市场计算机行业研究经验。2021年计算机行业新财富第六名、新浪金麒麟最佳分析师第五名团队核心成员、联席首席分析师。2022年加入国金证券研究所,任计算机组首席分析师。
李忠宇:信息安全专业出身,网安行业12年从业经历,资深网安产业专家。拥有CISP、NPDP等多项培训经历,具备多年网安产品规划、产品管理相关经验。曾担任奇安信战略部研究总监、投关部总监,专注于网络安全行业宏观环境、竞争格局、产品技术发展趋势等领域研究,对数字经济下网络安全产业发展具备独特的研究观点。目前覆盖网络安全、信创、数字经济、数据要素、国防信息化、政务信息化等计算机细分板块。
王倩雯:18年毕业于北京大学汇丰商学院西方经济学系。曾任职于商汤科技、天风证券研究所,主要覆盖金融科技、企业服务、人工智能、自动驾驶板块。
陈矣骄:波士顿大学理学硕士,曾就业于美国AI公司研发部、天风证券研究所。主要覆盖工业软件、能源IT、企业服务板块。
纪超:本硕就读于吉林大学计算机科学与技术、金融专业,曾任东软集团软件工程师,2022年加入国金证券研究所,任计算机组研究员助理,覆盖网络安全、信创等板块。
赵彤:复旦大学管理学学士,新加坡国立大学经济学硕士,2023年加入国金证券研究所,覆盖金融科技、人工智能、自动驾驶、企业服务等板块。
追踪优秀企业,贴近产业一线。
国金计算机组,欢迎各位关注!
点击下方阅读原文,获取更多最新资讯

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!

