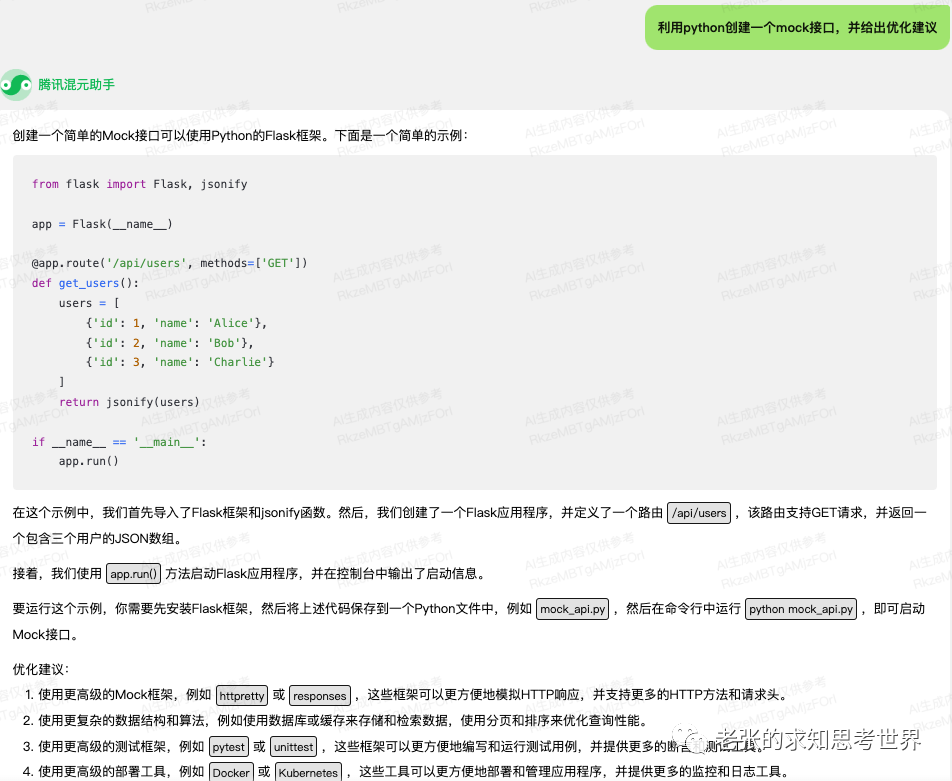
文章主题:AI写作, token, 文字, 模型训练数据
先说结论:AI作曲目前的水平已经很高,距离替代音乐人还很远,限制AI作曲发展最大的因素还是数据。
(利益相关:智能音乐创作工具TuneFlow开发者)
AI作曲的原理与AI写作或者AI绘画一样,都是序列预测:模型根据现有的token和模型的权重来推导下一个token。理论上来说,作曲相对写作和作画来讲更有数学规律,应该比另两者发展得更快才对。但现有的AI作曲模型却并不如GPT-3或者disco diffusion之类的文字或者图像模型那么亮眼。其中的原因在我看来就是缺乏大量的高质量数据。
训练AI写作时,token就是文字,而互联网上有无穷无尽的文字可以直接作为模型的训练数据;
在AI绘画的训练过程中,我们常常将token视为像素点。实际上,互联网上绝大多数图像都是由像素点构成的,因此这些图像可以被视为模型的优质训练数据来源。

训练AI作曲呢?我们有两个选择:
1. 学习音频,生成音频
2. 学习乐谱,生成乐谱,再用音乐制作软件将生成的乐谱合成为音频。

如果我们选择直接学习音频,那么所有网络上的音频文件理论上都可以作为训练数据。但问题来了,音频文件实际上是声音的波形离散化采样得来的:
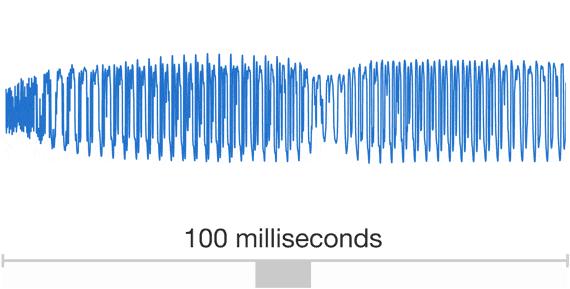
普通CD音质的音乐文件,需要大概44.1kHz的采样率才能将音乐完好的保存下来。这也就意味着模型每学习1秒的音频,就需要处理44100个token(采样点)。相比之下,一篇普通的文章总共就只有几千个token(文字),普通分辨率的图片也只有几十万个token(像素点),相比起来就是小巫见大巫了。如此长的序列,就连当前的SOTA模型也只能学个囫囵吞枣,感兴趣的同学可以了解一下OpenAI 2020年推出的,基于音频和歌词的音乐生成模型Jukebox。

生成的音频大多存在断裂和模糊的问题,这与其他形式的媒体如文字或图像相比,注定了其难以通过后期调整而达到流畅且悦耳的效果。因此,除非这类人工智能模型在未来能够进化到能直接创作出高品质音乐,否则其应用范围将受到极大的限制。
那么剩下的就是学习乐谱了。一首完整的曲子,几千个token(音符)学下来不成问题,并且生成出来的乐谱如果有不满意的地方,我们可以方便地进行修改。听起来很好对不对?对于作曲来说:是的 — 序列长度适中,数据有明显的内在结构,网上可以找到大量的数据(乐谱,MIDI)。这样的问题对于Transformer之类的生成模型实在太合适不过。也正是因此,单就作曲而言,当前的模型已经能够生成一些与人类水平相当的曲目了。

虽然作曲学的不错,但音乐制作远不止作曲这一步,之后还要通过编曲,混音,母带制作等一系列步骤,才能做出发行品质的音乐。好比一个画家只会画线稿,也是没法把画卖出去的。而编曲,混音这些步骤,可就不像作曲一样有大量公开的数据可以学了。
所以与其想着替代音乐人,我们为什么不换个思路,变成音乐人的智能辅助工具呢?(我们开发中的智能音乐创作工具TuneFlow,欢迎大家免费使用 ):


AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!