
文章主题:关键词:抽象, 曲谱生成, 演奏生成, 声音合成
微软亚洲研究院在 AI 音乐创作领域有一系列的研究成果,包括词曲写作、伴奏生成、歌声合成等。
微软亚洲研究院主管研究员谭旭在2021全球人工智能技术大会(GAITC)的“当 AI 与艺术相遇”专题论坛上,深入介绍了深度学习如何辅助流行音乐的创作。
大家好!我是微软亚洲研究院主管研究员谭旭,这次报告的题目是“基于深度学习的流行音乐创作”,我们将详细探讨如何将深度学习应用到流行音乐的创作过程中。我们先来看一下流行音乐的创作流程是什么样的。
什么是流行音乐?按照字面的理解就是流行的音乐,实际上流行音乐我们通常指的是商品音乐,也就是通俗、大众、喜闻乐见,又能商品化制作的音乐。因此,这类音乐具有固定的制作流程,包括词曲创作、伴奏编曲、录制乐器声音和人声、进行混音,最后进入到唱片制作等环节。而这是典型的工业制作流程,我们需要将其进行抽象以便在音乐创作中充分利用深度学习技术。
经过抽象我们得到了以下三个环节:
1)曲谱生成,包括词曲和伴奏编曲的生成;
原内容表达了音乐创作中,演奏生成和曲谱到声音之间的关联。由于演奏技术的差异,即使是同一曲谱,经不同演奏者的演绎也会产生巨大的变化。因此,我们需要依据曲谱来发掘并形成相应的演奏技巧。为了更全面地阐述这一观点,我们可以从以下几个方面进行展开。首先,音乐创作是一个高度个性化的过程,演奏者对曲谱的理解和感悟会直接影响到最终的表现。由于每个人的成长背景、艺术追求和演奏风格都有所不同,因此在演奏过程中,同样的曲谱可能会呈现出截然不同的风格。这也说明了为什么我们需要重视演奏技巧的培训和发展,以便更好地传达音乐的情感和意境。其次,演奏技巧的掌握对于音乐创作的成色至关重要。一个优秀的演奏者能够运用丰富的表现手法和技巧,将曲谱中的静态音符生动地呈现出来,让观众或听众感受到作品的魅力。而缺乏技巧的演奏则可能让曲谱失去原本的意义,无法达到预期的艺术效果。因此,我们在学习和借鉴他人演奏经验的同时,也要注重自身演奏技巧的提高,形成自己独特的艺术风格。最后,通过不断实践和尝试,我们可以在演奏中逐渐找到适合自己风格的演奏技巧。这需要我们在实际操作中积累经验,勇于挑战各种曲目和演出形式,不断地丰富自己的音乐语言和技巧。只有这样,我们才能在音乐表演的道路上越走越远,为自己的艺术事业注入更多的活力和创造力。
3)声音合成,根据曲谱和演奏技巧合成音乐声音,包括人声和乐器声音的合成。
有了这个抽象以后,深度学习技术尤其是内容生成技术就可以应用到流行音乐的创作中了。其实音乐不只是艺术,它还包括逻辑和规则,而这些都是深度学习所擅长的。如果有足够的数据、模型容量和计算力,深度学习就能产生比较好的效果。所以我们可以把上述流程对应到典型的深度学习应用任务上。曲谱和演奏技巧的生成,可以对应自然语言处理里的语言生成,因为它们就是用 symbolic token 符号表示,而声音生成则可以对应到语音合成,这样我们就能借鉴这些成熟领域的深度学习技术来帮助音乐生成了。

过去一段时间,微软亚洲研究院在 AI 音乐创作方向上开展了一系列研究工作,包括 Song Writing(词曲写作)、Arrangement(伴奏生成)、Singing Voice Synthesis(歌声合成)等。在词曲写作方面又涵盖了:1) SongMASS,歌词到旋律以及旋律到歌词的生成;2) StructMelody,利用音乐结构信息生成旋律;3) DeepRapper,Rap歌词押韵和节奏的生成;4) MusicBERT,通过大规模音乐数据学习音乐表征以更好的理解音乐,对音乐的风格、情感、曲式结构的理解。在伴奏编曲方面有 PopMAG 伴奏生成。在歌声合成方面有 HiFiSinger 高保真的歌声合成。接下来,我们将依次介绍这些工作。

词曲写作
在词曲写作方面,我们探讨了歌词生成旋律以及旋律生成歌词两个任务,并分析了这两个任务的特点:
1. 要保证生成的歌词和旋律本身具有歌词性和旋律性。这个方面靠大量的数据做语言模型的建模可以做得还不错;
2. 要保证歌词和旋律的匹配度。按照传统的术语讲就是腔词关系 (腔就是旋律、词就是歌词),好的腔词关系能互相促进表达,而不好的腔词关系会导致腔害于词、词害于腔。
因此,建模歌词和旋律的关系是一个重点。要建模好关系,很重要的一个因素是要有数据,但往往歌词和旋律的配对数据比较缺乏。除此之外,歌词和旋律的连接也比较弱,一句歌词可以配不同的旋律,一句旋律也可以配不同的歌词。类比其它序列到序列学习的任务,比如语音识别、语音合成、机器翻译等,我们可以发现源序列和目标序列都有很强的对应关系。在语音识别中,一个语音片段会严格对应一个字。所以歌词和旋律这种弱的连接关系更加需要数据才能学得好,或者我们可以探索不用纯依赖数据的方发去学习这种关系。
我们可以从两方面去考虑上述问题,一方面是纯粹基于深度学习的方法,从数据中去学习。另一方面是利用先验知识,因为人类在创作歌曲时也是需要学习很多音乐知识的,比如音调、节奏、结构、曲式等,通过把音乐知识和深度学习相结合,可以更好地建模歌词和旋律的关系。

首先介绍 SongMASS,它是纯粹靠数据驱动,用深度学习来建模歌词和旋律关系的方法。因为歌词和旋律是弱耦合关系,缺乏数据,所以我们利用了预训练,通过无监督、自监督、半监督的方法从无标签数据中学习以弥补数据不足。歌词和旋律虽然在内容上是弱耦合,但它们之间需要严格对齐,一个字或者音节需要对应到具体的音符。为此,我们提出了通过序列到序列学习的 encoder-attention-decoder 里的 attention 来抽取对齐关系。

预训练采用了我们之前提出的 Masked Sequence to Sequence Pre-training (MASS) 方法,将歌词和旋律分别看成是自然语言的一个段落,每句歌词和旋律对应一个句子。再从源句子掩盖一个片段,然后在解码器预测这个片段,通过这样的方法我们就可以学习数据的知识了

我们对encoder-decoder attention机制进行了相应的约束,旨在让它能够更好地学习和理解歌词与旋律之间的对齐关系。具体而言,我们在两个层面上施加了约束:句子级别和词级别的约束。这些约束使得模型在训练过程中呈现出单调递增的对角线形态,从而提高了其对齐关系的捕捉能力。在预测过程阶段,模型可以从attention中提取出这种对齐关系,进一步优化其性能表现。

我们从客观和主观评价的方式分别评估了 SongMASS 和基线方法的效果,在两个评价方式上,SongMASS 都取得了比基线方法好很多的效果,具体实验结果可参考 SongMASS 论文(论文链接:https://arxiv.org/pdf/2012.05168.pdf),更多的生成样例可参见 demo 网页:https://speechresearch.github.io/songmass/ 。
在接下来的部分中,我们将探讨如何运用基于音乐知识辅助的深度学习方法来实现歌词到旋律的转换。那么,哪些音乐元素能够有效地推动这一过程呢?我们可以从音调、节奏以及歌曲结构这三个方面来展开讨论。
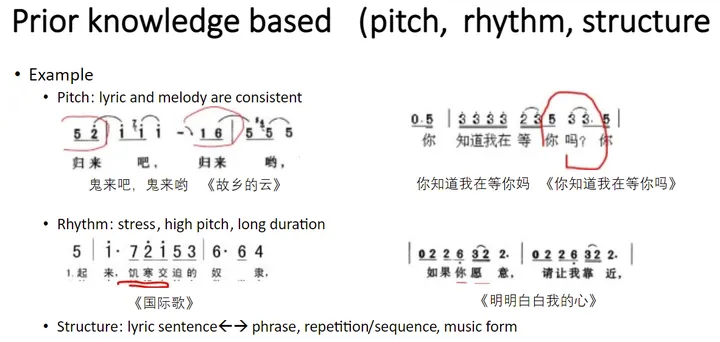
我们先来看一下这些知识应用得不好会产生什么样的问题。首先是音调的知识,我们的原则是保证歌词和旋律的音调要一致,不能相违背,比如《故乡的云》中“归来吧”听起来像是“鬼来吧”,而《你知道我在等你吗》中“你知道我在等你吗?”听起来像是“你知道我在等你妈!”。导致这个问题产生的原因就是因为歌词和旋律的声调不一致。
第二个是节奏知识,我们说重要的歌词要重拍、要高音、要持续。一个好的例子就是《明明白白我的心》,里面的“愿意”和“靠近”,对应的旋律就做到了强调。第三方面是结构知识,这里我们需要考虑歌词的语句和旋律的语句要对应,起承转合要对应,还要考虑旋律本身的重复、模进以及曲式结构。我们开展了相应的工作来利用这些音乐知识帮助旋律生成得更好。
我们的 StructMelody 工作利用音乐的结构信息实现了歌词到旋律的生成。我们构建了一个两阶段的旋律生成方法,利用结构信息作为歌词和旋律的桥梁。首先从歌词中提取结构信息,然后从结构信息生成旋律。第二阶段的结构信息生成旋律则可以利用自监督的方法,也就是从旋律中抽取结构,然后再训练结构到旋律的序列到序列模型。我们只需要让第一阶段生成的结构和第二阶段的结构尽量一致就可以。
举个例子,我们对古诗词《春晓》进行了谱曲,从歌词抽取的结构信息包括节奏和小节划分等信息,然后再配上和弦生成旋律。古诗词一般具有固定的格律,所以可以人工设计规则,而对于不规则的歌词,比如散文诗,就需要通过学习的方法预测结构信息了。

除了我们前面考虑的结构信息以外,还有一个非常重要的信息就是曲式结构,这个对于生成一首完整的旋律非常重要。我们常见的曲式结构有单一、单二、单三、回旋、变奏、奏鸣曲式以及流行音乐常见的主副歌结构,这些信息非常有助于音乐的生成。同时也需要考虑一首歌的情绪推动,起承转合,比如下图上这种经典的稳定开始、变化扩张、紧张运动、稳定结束的形式,还需要对旋律的情感、情绪做出理解。而这些知识都需要有对音乐的理解。

因此,我们开展了 MusicBERT 工作,利用大规模音乐数据进行预训练,从而更好地理解音乐,包括情感分类、流派分类、旋律伴奏抽取、结构分析等。

为了能够开展大规模的预训练,我们构建了一个大规模的音乐数据集 MMD 包含150万首音乐数据,比之前的音乐数据集大10倍。然后针对音乐理解任务我们提出了 OctupleMIDI 这种编码方式,其中含有8种基本的 token,包括拍号、速度、小节、位置、乐器、音高、时长、速度等。相比之前的 REMI、CP 等,编码方式 OctupleMIDI 能极大地缩短音乐序列长度,同时还可以容纳足够的音乐信息。更短的序列长度可以使模型一次性处理更长的音乐片段,从而提升模型对音乐的理解能力

我们使用了 BERT 的 Masked Language Modeling 训练方式,采用了 bar-level 的掩码策略,即一次性掩盖一个小节内相同类型的 token,以防止信息泄露。

MusicBERT模型的基础结构采用了Transformer模型,但在输入和输出端针对OctupleMIDI进行了独特的优化设计。具体来说,在输入阶段,将8个token的embedding拼接在一起,并通过一个线性层进行映射,最终到达模型的隐层维度。而在输出阶段,则利用8个softmax矩阵对对应的token进行预测。这样的设计不仅提升了模型的效率,也使得其能够更好地适应OctupleMIDI的特点。
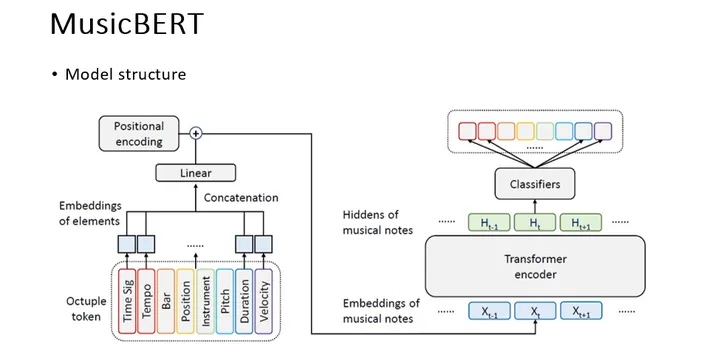
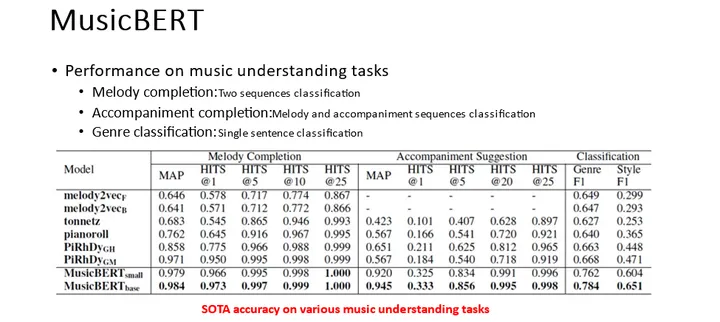
MusicBERT在三个下游任务中——Melody Completion、Accompaniment Completion以及Genre Classification上,都展现出了SOTA(State-of-the-art)级别的性能,这一成果显然远超过了以往的音乐理解模型。
伴奏编曲
在伴奏编曲的生成方面,我们进行了 PopMAG 这个工作。PopMAG 处理的任务形式是给定主旋律和和弦进而生成不同乐器的伴奏,包括鼓、贝斯、吉他、键盘、弦乐等。这其中的一个难点就是要保证多轨音乐的和谐。因此,我们提出了MuMIDI 的编码方式,将多轨音乐编码到一个序列里,使得多轨音乐生成变成了单个序列的生成,这样自然地建模了不同轨音符之间的依赖关系。
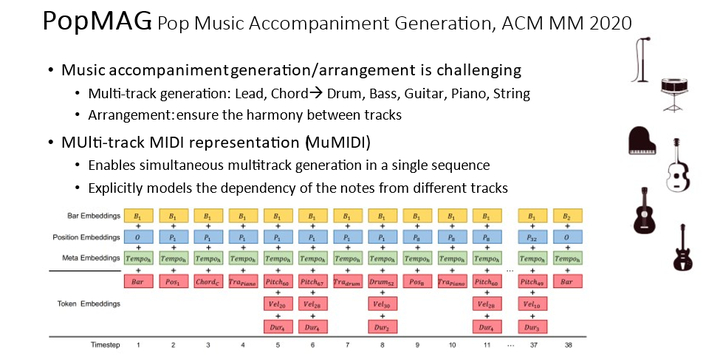
在三项不同的数据集上,我们对PopMAG的伴奏生成效能进行了评估。经过人类主观评价,我们发现生成的伴奏已经非常贴近真实伴奏的表现。

歌曲合成
针对歌声合成,我们做了 HiFiSinger 的工作。事实上,和说话的声音相比,歌声需要更高的保真度来传达表现力和情感。那么怎么实现高保真度呢?一个方面是提高声音质量,另一方面是提高声音的采样率。
之前的工作大都关注在提高声音质量,而我们考虑的是提高采样率。我们知道人耳对频率的感知范围为20到20kHz,如果采用16kHz或者24kHz的采样率的话,根据奈奎斯特-香农采样定理,它只能覆盖8kHz或者12kHz的频带范围,并不能很好地覆盖人耳的听觉范围。因此我们将采样率从24kHz升到48kHz来进行建模。

整个歌声合成的流程采用了声学模型和声码器级联的方式,如下图(右)所示。但是升级到48kHz的采样率有两个挑战:1)48kHz在频谱维度有更宽的频谱,这给声学模型的建模带来了挑战;2)48kHz在时间维度上有更长的语音采样点,这给声码器的建模带来了挑战。

所以,我们分别提出了针对声学模型的 Sub-frequency GAN 和针对声码器的 Multi-length GAN来解决上述问题。

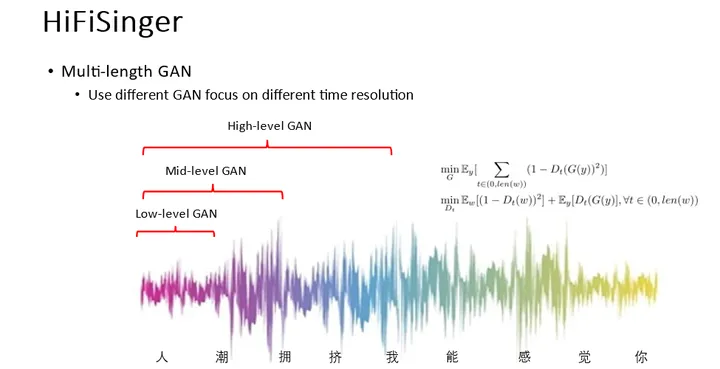
实验结果显示 HiFiSinger 相比之前的基线方法取得了明显的音质提升,表明了我们的方法对高采样率建模的有效性。同时采用48kHz采样率的 HiFiSinger 模型甚至超过了24kHz的录音音质,也证明了高采样率的优势。

以上就是我们在 AI 音乐生成方面开展的一系列研究工作。目前 AI 音乐生成仍存在一些研究挑战,包括以下几个方面:1)对音乐结构的理解有助于音乐的生成以及编排;2)音乐的情感以及风格的建模;3)交互式的音乐创作;4)对于生成音乐原创性的保证等。


微软亚洲研究院机器学习组一直致力于 AI 音乐的研究,研究课题包括词曲写作、伴奏编曲、歌声合成、音乐理解等。我们即将推出 AI 音乐开源项目 Muzic,涵盖了我们在 AI 音乐的一系列研究工作,敬请期待。
AI 音乐研究项目主页:
https://www.microsoft.com/en-us/research/project/ai-music/
Muzic 开源项目页面(页面将于近期公开):
https://github.com/microsoft/muzic
论文列表:
[1] SongMASS: Automatic Song Writing with Pre-training and Alignment Constraint, AAAI 2021, https://arxiv.org/pdf/2012.05168.pdf
[2] DeepRapper: Neural Rap Generation with Rhyme and Rhythm Modeling, ACL 2021, https://arxiv.org/pdf/2107.01875.pdf
[3] MusicBERT: Symbolic Music Understanding with Large-Scale Pre-Training, ACL 2021, https://arxiv.org/pdf/2106.05630.pdf
[4] PopMAG: Pop Music Accompaniment Generation, ACM MM 2020, https://arxiv.org/pdf/2008.07703.pdf
[5] HiFiSinger: Towards High-Fidelity Neural Singing Voice Synthesis, arXiv 2021, https://arxiv.org/pdf/2009.01776.pdf
本账号为微软亚洲研究院的官方知乎账号。本账号立足于计算机领域,特别是人工智能相关的前沿研究,旨在为人工智能的相关研究提供范例,从专业的角度促进公众对人工智能的理解,并为研究人员提供讨论和参与的开放平台,从而共建计算机领域的未来。
微软亚洲研究院的每一位专家都是我们的智囊团,你在这个账号可以阅读到来自计算机科学领域各个不同方向的专家们的见解。请大家不要吝惜手里的“邀请”,让我们在分享中共同进步。
也欢迎大家关注我们的微博和微信 (ID:MSRAsia) 账号,了解更多我们的研究。

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!


