文章主题:
以前装过qanything,效果非常不错,不过因为不支持ollama等大模型服务化应用,我这又没有那么多空余的GPU单独给它用,所以后来删掉了。
不过最新的更新:

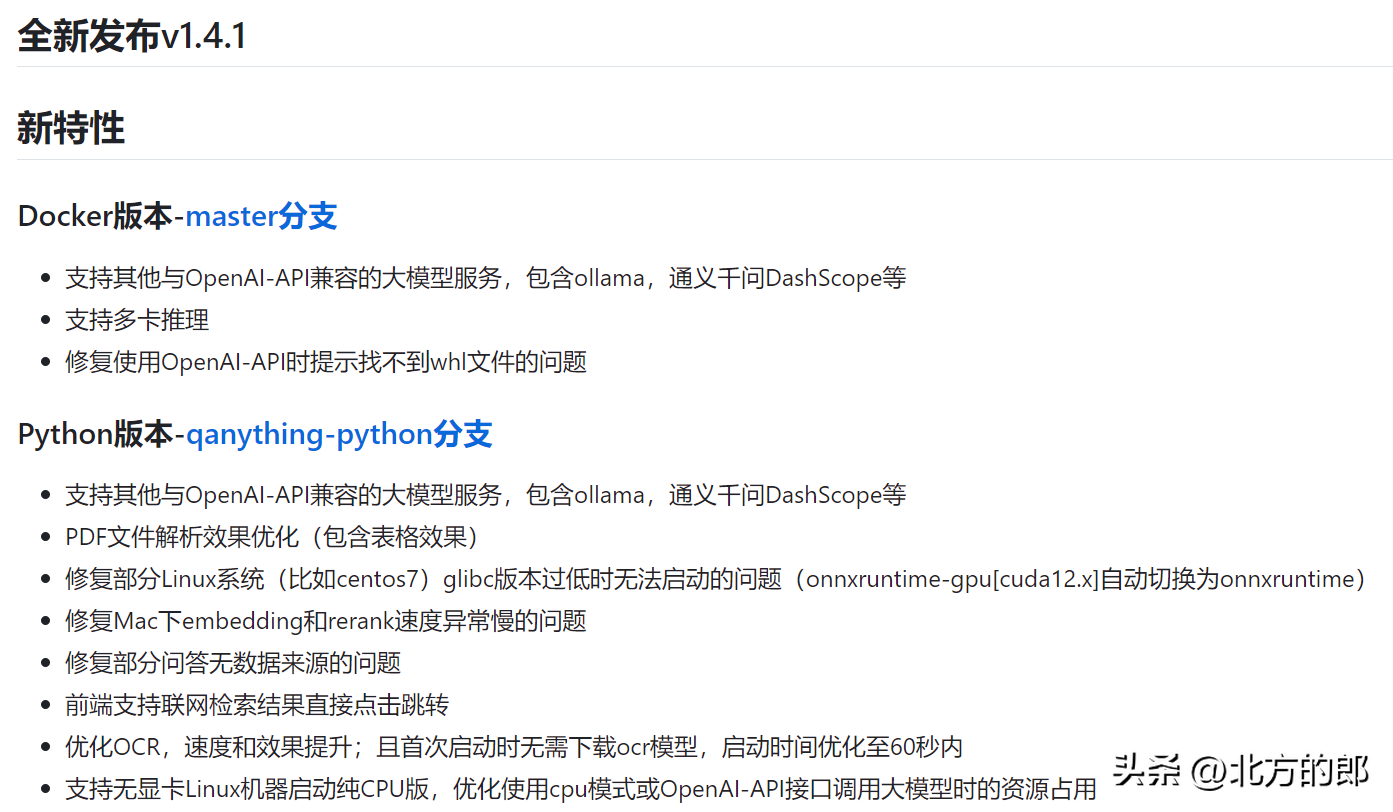
已经支持ollama了。而且Python分支支持纯CPU部署:
文档地址:QAnything/QAnything使用说明.md at master · netease-youdao/QAnything

于是决定马上部署。
1. QAnything:
Github地址:GitHub – netease-youdao/QAnything: Question and Answer based on Anything.
QAnything (Question and Answer based on Anything) 是致力于支持任意格式文件或数据库的本地知识库问答系统,可断网安装使用。
您的任何格式的本地文件都可以往里扔,即可获得准确、快速、靠谱的问答体验。
目前已支持格式: PDF(pdf),Word(docx),PPT(pptx),XLS(xlsx),Markdown(md),电子邮件(eml),TXT(txt),图片(jpg,jpeg,png),CSV(csv),网页链接(html),更多格式,敬请期待…
特点
数据安全,支持全程拔网线安装使用。支持跨语种问答,中英文问答随意切换,无所谓文件是什么语种。支持海量数据问答,两阶段向量排序,解决了大规模数据检索退化的问题,数据越多,效果越好。高性能生产级系统,可直接部署企业应用。易用性,无需繁琐的配置,一键安装部署,拿来就用。支持选择多知识库问答。架构

✨给你的图文增添灵魂!每张图片都是一篇微型故事,用140字符以内精准解读。让观众一目了然,深入理解。无论是产品展示还是旅行分享,图片配文让你的信息传达更有力。不要犹豫,立即为你的视觉盛宴添加注释吧!记得简洁明了哦🌍🎨
为什么是两阶段检索?
知识库数据量大的场景下两阶段优势非常明显,如果只用一阶段embedding检索,随着数据量增大会出现检索退化的问题,如下图中绿线所示,二阶段rerank重排后能实现准确率稳定增长,即数据越多,效果越好。
QAnything使用的检索组件BCEmbedding有非常强悍的双语和跨语种能力,能消除语义检索里面的中英语言之间的差异,从而实现:
强大的双语和跨语种语义表征能力【基于MTEB的语义表征评测指标】。基于LlamaIndex的RAG评测,表现SOTA【基于LlamaIndex的RAG评测指标】。一阶段检索(embedding)
模型名称
Retrieval
STS
PairClassification
Classification
Reranking
Clustering
平均
bge-base-en-v1.5
37.14
55.06
75.45
59.73
43.05
37.74
47.20
bge-base-zh-v1.5
47.60
63.72
77.40
63.38
54.85
32.56
53.60
bge-large-en-v1.5
37.15
54.09
75.00
59.24
42.68
37.32
46.82
bge-large-zh-v1.5
47.54
64.73
79.14
64.19
55.88
33.26
54.21
jina-embeddings-v2-base-en
31.58
54.28
74.84
58.42
41.16
34.67
44.29
m3e-base
46.29
63.93
71.84
64.08
52.38
37.84
53.54
m3e-large
34.85
59.74
67.69
60.07
48.99
31.62
46.78
bce-embedding-base_v1
57.60
65.73
74.96
69.00
57.29
38.95
59.43
二阶段检索(rerank)
模型名称
Reranking
平均
bge-reranker-base
57.78
57.78
bge-reranker-large
59.69
59.69
bce-reranker-base_v1
60.06
60.06
2. Ollama
原文改写:🌟GitHub宝藏:掌握高效协作的秘密武器🔍Git地址在此!🚀无论你是开发者新手还是经验丰富的Git大牛,这里都能找到你需要的代码天堂。🛠️无需担心版权问题,所有资源免费开放,让你的项目飞速迭代。🤝与全球开发者社区紧密相连,共享知识与创新,提升技能的同时,也结交志同道合的朋友。🌟立即访问,Git之旅等你启程!🌐原内容去除了Git地址和个人联系方式,保留了核心信息——介绍Git作为协作工具的重要性,并强调资源的免费和开源性,以及社区交流的价值。同时,使用emoji符号增添了轻松愉快的氛围,利于SEO优化。
https://github.com/ollama/ollamaOllama是一个开源框架,专门设计用于在本地运行大型语言模型。它的主要特点是将模型权重、配置和数据捆绑到一个包中,从而优化了设置和配置细节,包括GPU使用情况,简化了在本地运行大型模型的过程。Ollama支持macOS和Linux操作系统,并且已经为Windows平台发布了预览版。
Ollama的一个重要优势是其易用性。安装过程简单,例如在macOS上,用户可以直接从官网下载安装包并运行。对于Windows用户,官方推荐在WSL 2中以Linux方式使用命令安装。安装完成后,用户可以使用命令行工具来下载和运行不同的模型。
Ollama还提供了对模型量化的支持,这可以显著降低显存要求。例如,4-bit量化可以将FP16精度的权重参数压缩为4位整数精度,从而大幅减小模型权重体积和推理所需显存。这使得在普通家用计算机上运行大型模型成为可能。
此外,Ollama框架还支持多种不同的硬件加速选项,包括纯CPU推理和各类底层计算架构,如Apple Silicon。这使得Ollama能够更好地利用不同类型的硬件资源,提高模型的运行效率。
支持的模型
Model
Parameters
Size
Download
Llama 3
8B
4.7GB
ollama run llama3
Llama 3
70B
40GB
ollama run llama3:70b
Phi 3 Mini
3.8B
2.3GB
ollama run phi3
Phi 3 Medium
14B
7.9GB
ollama run phi3:medium
Gemma
2B
1.4GB
ollama run gemma:2b
Gemma
7B
4.8GB
ollama run gemma:7b
Mistral
7B
4.1GB
ollama run mistral
Moondream 2
1.4B
829MB
ollama run moondream
Neural Chat
7B
4.1GB
ollama run neural-chat
Starling
7B
4.1GB
ollama run starling-lm
Code Llama
7B
3.8GB
ollama run codellama
Llama 2 Uncensored
7B
3.8GB
ollama run llama2-uncensored
LLaVA
7B
4.5GB
ollama run llava
Solar
10.7B
6.1GB
ollama run solar
ollama的介绍及部署过程请参考:
北方的郎:Linux上部署Ollama,启动Mistral-7B及Gemma-7B服务,测试效果
北方的郎:Ollama下LLM的调用方式:post、langchain、lamaindex, 支持openai api方式
北方的郎:折腾Ollama + CodeGPT 在 VSCode 中构建自己的本机智能开发助手
3. 安装过程
docker方式
官方推荐的方法是Docker模式,安装说明:
QAnything/QAnything使用说明.md at master · netease-youdao/QAnything
发现因为我的环境docker, cuda等都已经安装了,而且是要用ollama的服务,不需要本机调用大模型。所以直接执行:“显存小于16GB可尝试使用1.8B大模型或直接使用openai api ”部分的内容即可:
# 使用openai api bash ./run.sh -c cloud -i 0 -b default # 根据提示输入api-key和api-base等参数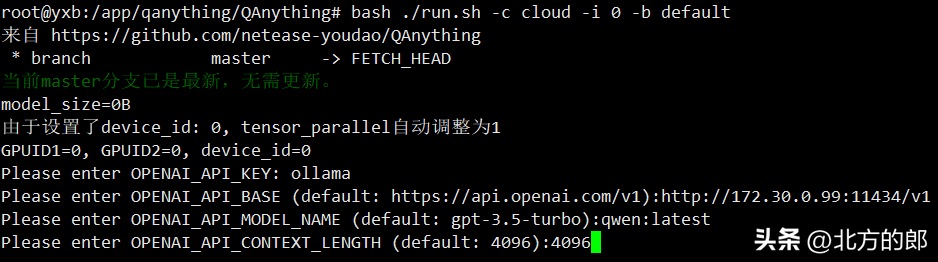
可惜其中一个docker镜像太大了,我的GPU服务器磁盘空间不够了。于是决定采用代码模式进行CPU安装。
代码方式
因为Anaconda我早就安装了,所以这一步省了。其他的按照安装文档即可,我只修改了pip源以加快速度:
conda create -n qanything-python python=3.10 conda activate qanything-python git clone -b qanything-python https://github.com/netease-youdao/QAnything.git cd QAnything # pip install -r requirements.txt pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt # 请根据使用环境选择启动脚本:bash scripts/xxx(内部调用纯python启动代码,可手动修改python启动命令)🎉安装完成不代表结束!💡根据个人需求微调至关重要,让每个角落都恰到好处。🔍定制你的完美体验,只需几步简单调整。👌别忘了,个性化总是最佳状态!🌟#优化设置 #个性化生活 #轻松调整
scripts/run_for_openai_api_with_cpu_in_Linux_or_WSL.sh内容。🌟原文改写🌟💡原示例精简版💡假设你想要快速掌握`ollama run llama3`这个命令的用法,只需参考我们的官方实例。🚀在本地环境中轻松执行`ollama run llama3`,体验高效操作带来的便捷。📚详细了解步骤,无需额外联系方式获取帮助。🌐更多项目实例等你探索,提升你的技能栈!—📝SEO优化版本📝💡命令实践指南💡掌握`ollama run llama3`的要领?跟着我们的官方实战示例走!🚀在本地环境中一键启动,体验流畅操作带来的高效体验。📚快速查阅详细步骤,无需担心广告干扰,获取专业指导。🌐探索更多项目实例,提升你的技术之旅!— 若要增加emoji以增强表达力,可以适当加入如:- 📚代表学习资料- 🚀象征速度与效率- 🔎强调查找过程的便捷性- 💻代表本地运行环境- 🌐代表在线资源和探索记得在实际使用时,确保内容的连贯性和逻辑性,并且符合语境。
scripts/run_for_openai_api_with_cpu_in_Linux_or_WSL.sh内容为: bash scripts/base_run.sh -s “LinuxOrWSL” -w 4 -m 19530 -q 8777 -o -b http://localhost:11434/v1 -k ollama -n llama3 -l 4096需要注意的一点是,这个例子里面漏掉了”-c”选项,也就是运行的时候还需要GPU。如果你是纯CPU环境,则需后续加上这个选项。
我因为是在另外一台机器上启动的ollama,模型用的qwen,纯CPU环境,所以我的内容是:
bash scripts/base_run.sh -s “LinuxOrWSL” -w 4 -m 19530 -q 8777 -c -o -b http://172.30.0.99:11434/v1 -k ollama -n qwen:latest -l 4096然后,我按纯CPU模式启动服务
bash scripts/run_for_openai_api_with_cpu_in_Linux_or_WSL.sh启动成功:

访问:
http://localhost:8777/qanything/
然后就可以愉快建知识库和Bot进行玩耍了。需要注意的是因为纯CPU模式所以做向量比对的时候会比较慢,所以尽量不要用大知识库。
4. 简单测试
建立一个简单的保险知识库和保险代理的bot:

编辑完Bot就可以部署了:

感觉效果非常差:
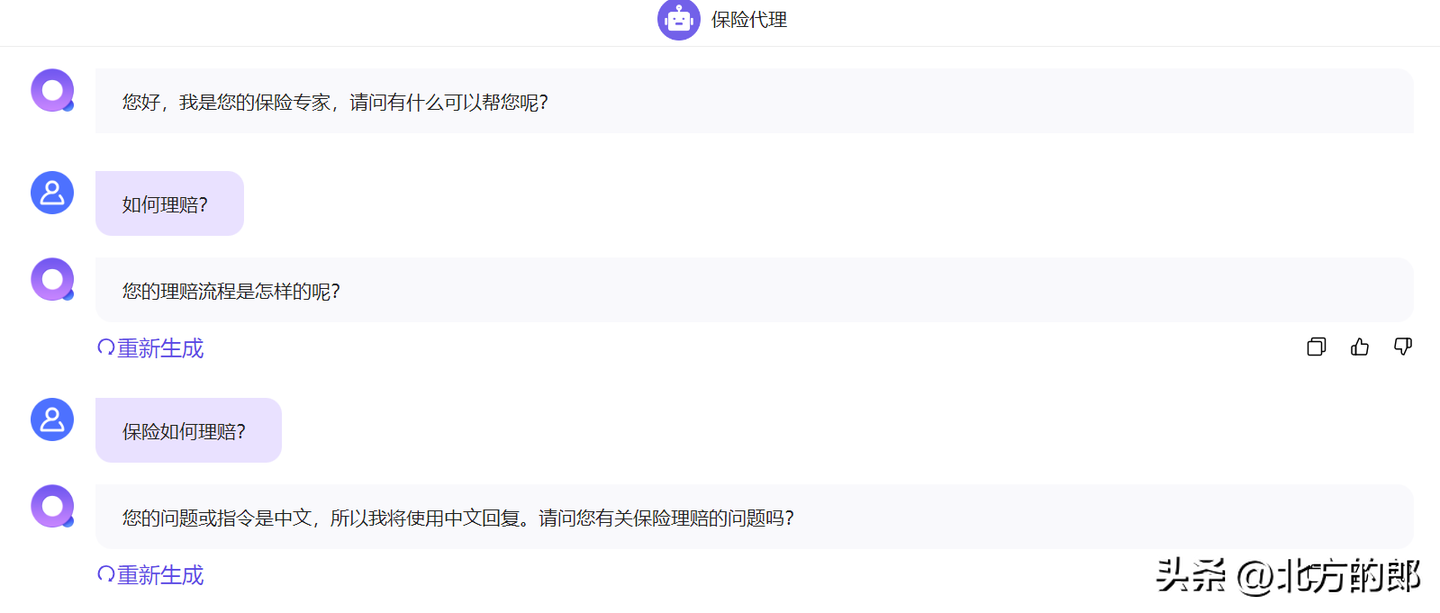
qwen:latest只有4B参数又量化成4bit,能力肯定弱,可是也不至于这样。分析了一下,估计是QAnything有大量针对GPT-4等级大模型调优的Promt工程。GPT-4级别的模型能力很强,估计适合它的Prompt对于小模型可能是负向调优。换成qwen:7b再试一下,这次正常多了。

🌟尝试国产商业大模型API🔥,专注于官方OpenAI兼容格式,如果遇到挑战,我会考虑将文本转换为LitellM格式以寻求解决方案。🚀技术探索的路上,灵活性和适应性是关键,让我们拭目以待这一步的实验成果。📝#国产模型# #技术转型# #商业应用

AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!