internlm2_5-7b-chat 模型[1],是商汤的最新开源的大模型,引入了一个70亿参数的基础模型以及一个为实际应用设计的聊天模型。根据该模型发布的基准测试,internlm2_5-7b 展示了卓越的推理能力,在数学推理任务中得到水平领先的结果,超过了 Llama3 和 Gemma2-9B 等友商模型。
InternLM2.5 拥有高达100万词的上下文窗口,使其在处理大量数据方面表现卓越,在如 LongBench 的长上下文挑战中处于领先地位。该模型还能使用工具,整合来自超过100个网络来源的信息,并在遵循指令、选择工具和反思过程方面具有优异的能力。
本文中,我们将以 internlm2_5-7b-chat[2] 为例,介绍如何:
在本地运行此模型并启动一个与 OpenAI 兼容的 API 服务使用本地大语言模型运行 Obsidian-local-gpt 插件我们将使用 LlamaEdge[3](Rust + Wasm 技术栈)来开发和部署这个模型的应用程序。无需安装复杂的 Python 包或 C++ 工具链!了解我们选择这项技术的原因[4]。
在本地运行 internlm2_5-7b-chat 并启动兼容 OpenAI 的 API 服务
第一步:通过以下命令行安装 WasmEdge[5]
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install_v2.sh | bash -s — -v 0.13.5 –ggmlbn=b3259第二步:下载 internlm2_5-7b-chatGGUF 文件[6]。由于模型大小为5.51G,下载可能需要一段时间。
curl -LO https://huggingface.co/second-state/internlm2_5-7b-chat-GGUF/resolve/main/internlm2_5-7b-chat-Q5_K_M.gguf第三步:下载一个 API server 应用。它也是一个可以在多种 CPU 和 GPU 设备上运行的跨平台可移植 Wasm 应用。
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/latest/download/llama-api-server.wasm第四步:使用以下命令行启动模型的 API 服务器。
wasmedge –dir .:. –nn-preload default:GGML:AUTO:internlm2_5-7b-chat-Q5_K_M.gguf \ llama-api-server.wasm \ –prompt-template chatml \ –ctx-size 500000 \ –batch-size 256 \ –model-name internlm2_5-7b-chat打开一个新的终端窗口,可以使用下面的 curl 与 API 服务器进行交互。
curl -X POST http://localhost:8080/v1/chat/completions \ -H accept:application/json \ -H Content-Type: application/json \ -d {“messages”:[{“role”:“system”, “content”: “You are a sentient, superintelligent artificial general intelligence, here to teach and assist me.”}, {“role”:“user”, “content”: “Write a short story about Goku discovering kirby has teamed up with Majin Buu to destroy the world.”}], “model”:“internlm2_5-7b-chat”}完整的 API server与 Obsidian-local-gpt Plugin
LlamaEdge 将构建一个与 OpenAI 兼容的 API 服务器来运行你的开源大语言模型。这使你能够将功能强大的本地语言模型能力整合到 Obsidian 笔记应用中,通过 AI 赋能的特性如文本生成、摘要、拼写检查等增强用户体验。
确保你已安装了 Obsidian 应用。
安装 Obsidian-local-gpt Plugin
打开 Obsidian 设置,进入 “Community plugins” 并搜索 obsidian-local-gpt。点击 “Install” 安装 plugin。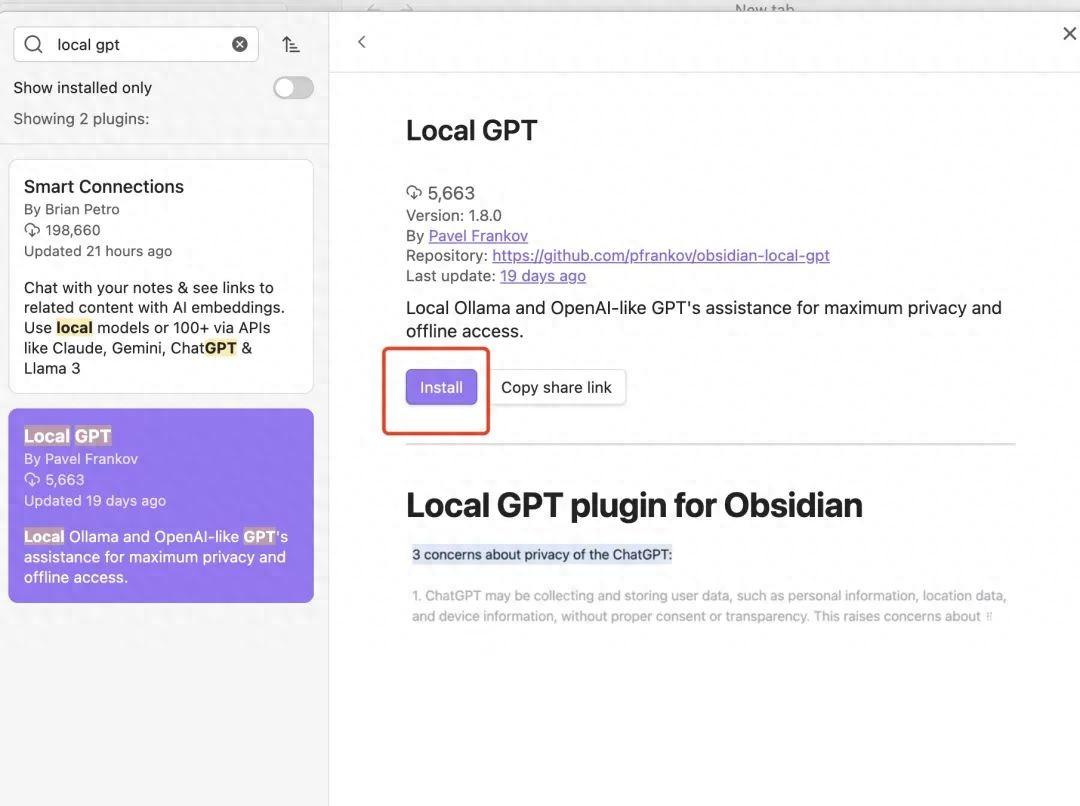
然后点击 “Enable”。
配置 Plugin
进入插件设置。“AI Provider”选择“OpenAI compatible server”。设置服务器 URL。如果你在本地运行 LLM,请使用 http://localhost:8080/配置 API 密钥到 LLAMAEDGE在默认模型下,确保点击刷新按钮并选择 internlm2_5-7b-chat 模型

配置 Obsidian 快捷键
打开 Obsidian 设置。进入 Hotkeys。输入“Local”,你应该会看到“Local GPT: Show context menu”。点击 + 图标并按下想设置的快捷键(例如 ⌘ + M)。设置好了快捷键后,当你写作或编辑笔记时,选中你想互动的文本,并按下你设置的快捷键来调用这个由大模型驱动的插件!

使用 Plugin
配置好插件后,用户就能直接在 Obsidian 笔记中使用 AI 功能。可以生成内容,总结长篇信息,或从笔记中提取任务——同时确保他们的数据保持私密和安全。
这一集成为记笔记的人提供了无缝的体验,能优化他们的工作流程,并通过 AI 优化工作流,且无需担心隐私。这对于需要有 AI 加持的强大记笔记功能的研究人员、学生和专业人士特别有帮助。
结论
internlm2_5-7b-chat 模型展示了现代大语言模型适应各种环境和需求的能力。无论是聊天界面还是增强记笔记应用,internlm2_5-7b-chat 都是开发者和终端用户的强大工具。它能够整合到不同的软件架构中,为 AI 应用开辟了众多实际场景的可能性。
这篇指南只展示了几种潜在的应用,但 internlm2_5-7b-chat 的灵活性允许更多令人激动的 AI 应用发展。加入 WasmEdge discord[8] 向我们提问,分享你的看法吧。
参考资料
[1]
internlm2_5-7b-chat 模型: https://huggingface.co/internlm/internlm2_5-7b-chat
[2]
internlm2_5-7b-chat: https://huggingface.co/second-state/internlm2_5-7b-chat-GGUF
[3]
LlamaEdge: https://github.com/second-state/LlamaEdge/
[4]
了解我们选择这项技术的原因: https://www.secondstate.io/articles/fast-llm-inference/
[5]
WasmEdge: https://github.com/WasmEdge/WasmEdge
[6]
GGUF 文件: https://huggingface.co/second-state/internlm2_5-7b-chat-GGUF/resolve/main/internlm2_5-7b-chat-Q5_K_M.gguf?download=true
[7]
http://localhost:8080/
[8]
WasmEdge discord: https://discord.com/invite/U4B5sFTkFc
关于 WasmEdge
WasmEdge 是轻量级、安全、高性能、可扩展、兼容OCI的软件容器与运行环境。目前是 CNCF 沙箱项目。WasmEdge 被应用在 SaaS、云原生,service mesh、边缘计算、边缘云、微服务、流数据处理、LLM 推理等领域。
GitHub:https://github.com/WasmEdge/WasmEdge
官网:https://wasmedge.org/
Discord 群:https://discord.gg/U4B5sFTkFc
文档:https://wasmedge.org/docs