前言
对于一款数字时代的图片编辑工具而言,抠图工具扮演着越来越重要的角色。它能轻松地将图像中的目标与背景进行分离,为用户提供便捷高效的编辑体验。
在过去,抠除图像背景往往是一件复杂又繁琐的工作,而实现一个 AI 自动抠图工具也并非易事,因为它需要不少服务器的算力消耗以及大量训练模型的成本。
而现在,我将展示在仅使用 1核1G运存 的超低服务器资源下,可以实现多么令人惊叹的抠图工具!如下所示,只需上传图片,便可自动抠除背景。在线体验[1]
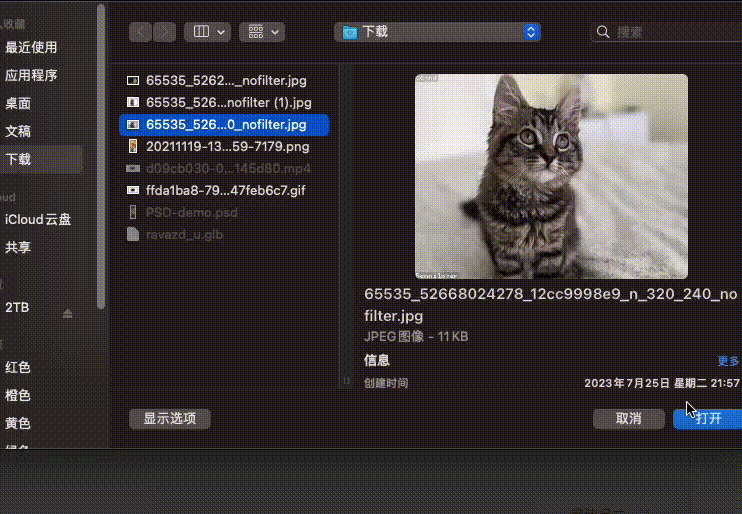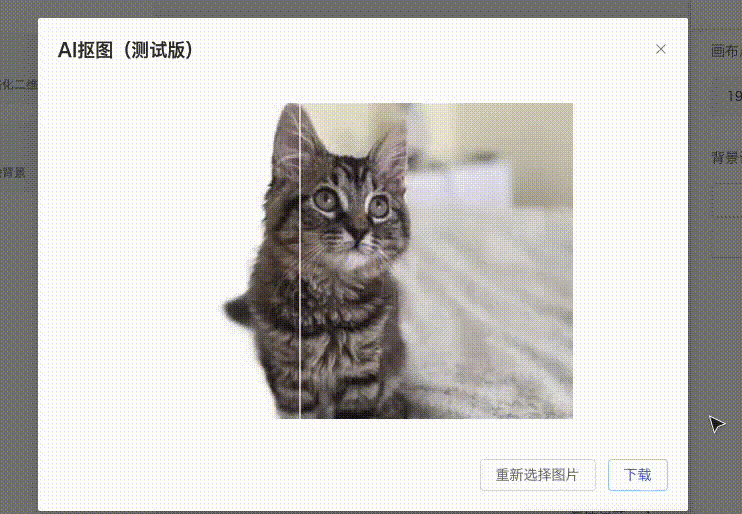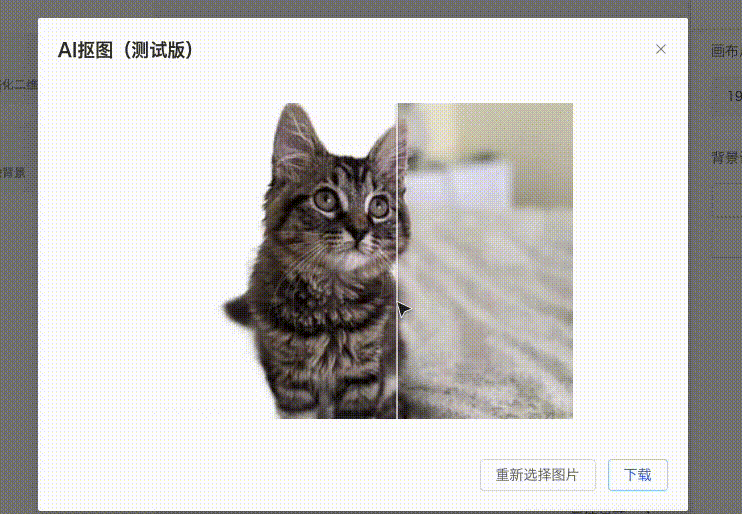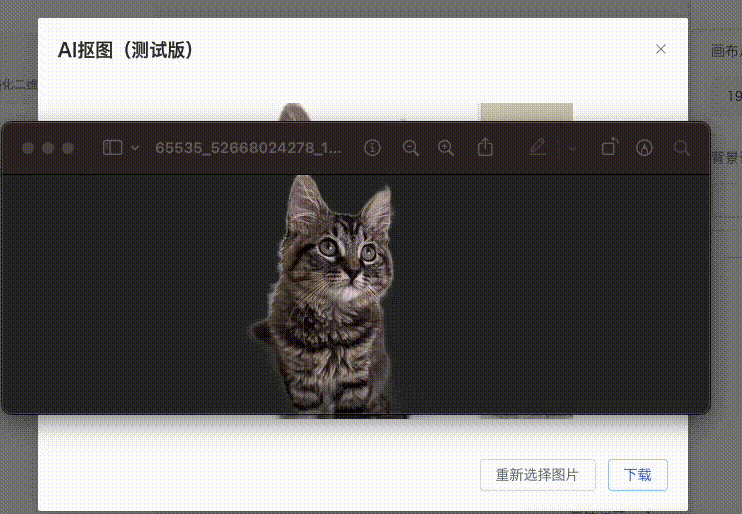
因为带宽也很小(仅 1M )所以在线体验建议不要上传太大的图像。
接下来,我将带你学习如何部署,通过简单几步即可实现这款强大的 AI 抠图工具。同时,我也将用通俗易懂的文字带你剖析 AI 抠图工具背后的工作原理,帮助你更好地理解其背后的算法和逻辑。废话不多说,让我们开始吧!
开始部署
首先我们需要使用 Rembg 这个库,它是基于 U^2-Net 模型构建的一个用于图像背景去除的 Python 工具。

为了让开发者快速掌握它,我们并不需要学习 Python(除非自己训练模型),我们只需要会一点 docker 的使用,然后运行以下命令:
docker run -d -p 5000:5000 –restart always danielgatis/rembg s运行完毕后会启动一个服务容器,映射在 5000 端口,此时访问 http://(服务器IP):5000 就可以看到类似这样的界面:

恭喜你,已经成功部署好了 AI 抠图工具,是不是 so easy ~
在第一次提交图像处理时,程序会自动下载所需模型到服务器上。标准预训练模型(u2net)为 176 MB 大小,而其精简版预训练模型(u2netp)则仅为 4.7 MB 大小,越小的模型消耗的内存就越少,在本例中正是使用了精简版模型,才得以在如此低配的服务器上良好地运行,制约其生产速度的反而是网络带宽。
这里的 Model 选项为抠图所指定的预训练模型,常用的几种有:
• u2net:适用于一般用例的预训练模型。• u2netp:u2net 模型的轻量级版本。• silueta:一个社区精简版,与 u2net 效果相同,但大小缩减到 43Mb。• u2net_human_seg:适用于人体分割的预训练模型。• isnet-anime:动漫角色的高精度分割。如何使用
前面我们部署好了服务,那么该怎样结合到项目中使用呢?有两种方式。
调用 API 接口(不推荐)
访问 http://(服务器IP):5000/api 就可以看到一个 Swagger 构建的文档,程序提供了两个接口,都是接收一个图像然后返回其去除背景的图像结果,区别在于:
1. GET 方法接收的是 URL 参数,传递的是一个网络可访问的图像链接2. POST 方法则是接收 file 参数,传递的是前端表单提交的二进制流文件
但是,我要说但是了,这种使用方法虽然使用简单,但经过测试,在服务端会有一定程度的内存泄露问题,由于本文主打一个低配服务器部署教程,不必要的内存消耗是无法接受的,所以并不推荐使用此方法。
通过 websocket 调用(推荐)
在前端项目中,我们需要安装依赖:
npm i @gradio/client然后引入并在项目中初始化一下 socket 服务:
import { client } from @gradio/client const app = await client(http://(服务器IP):5000/)接着我们写一个简单的上传按钮,例如:
<input type=“file” onChange=“selectFile” />在选择文件的事件回调 selectFile 中,将文件传递给服务接口便可获得抠图结果:
const selectFile = async (file) => { const result = await app.predict(“/predict”, [file, “u2netp”, “”]); // u2netp 可改为其它模型 console.log(result?.data[0]); // 这里为返回的图像 };成功后返回的是 Base64 格式数据,可以直接设置在 img 标签的 src 属性上以显示在页面中,如果要点击下载的效果可以参考如下方法:
function DlBase64 (base64Data, fileName) => { const link = document.createElement(a) link.href = base64Data link.download = fileName link.click() }在实际案例中使用 Vue 代码实现,具体代码可参考:Github – ImageCutout.vue[2]
AI抠图原理
早在 2015 年,德国图像处理研究所(Institut für Informatik)的研究人员就提出了一种图像分割任务解决方法,它是为了解决医学领域中的器官、细胞等图像的分割问题,后成为了一种经典的深度学习模型。由于其网络结构形状类似于字母 U,遂取名为 U-Net 模型。
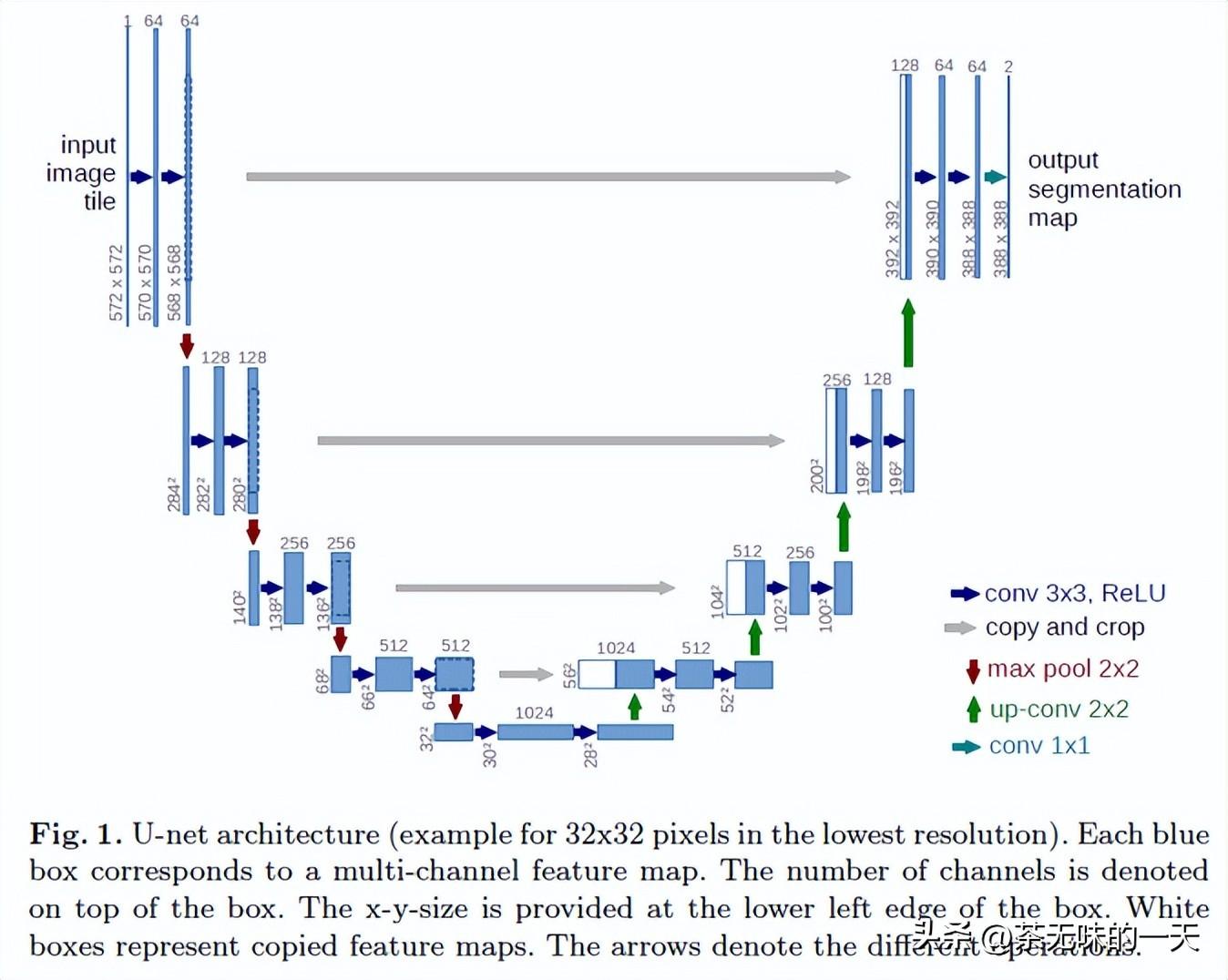
简单来说,这个模型会先对图像进行卷积和池化,再对特征图进行上采样或反卷积操作,左右对称的特征图拼接后再进行卷积和上采样,这个过程重复4次,最终得到输入图像的分割图。
卷积算法是一种常用的数字信号处理技术,是深度学习中卷积神经网络(CNN)的核心操作,可以看做是一个窗口滑动点乘运算,对输入信号或图像不同位置进行加权求和,从而提取出不同位置的特征信息。
池化从某种程度上来说,类似于图片压缩,只不过压缩是直接删除一些不重要的信息、或是损失一定图像质量来达到与原始图像相同或近似的目的。而池化则是一种降维处理,它的目的不是单纯的减小尺寸,而是为了提高计算效率,从而提取出更重要的特征信息。
而上采样则是将特征图反卷积,提升分辨率。所以这个处理结构也被提出者称为:编码器-解码器结构。
由于 U-Net 模型主要解决的是医学图像上的分割问题,这类图像通常有着较为简单的特征和结构,所以在处理复杂图像上则存在一些问题,无法直接应用于自然图像分割等场景,这时候就该 U^2-Net 登场了。

在 U-Net 模型基础上,秦雪彬等人提出了 U^2-Net 模型(他们发布的论文在去年被国际顶级学会 ICPR 评选为 2020 模式识别最佳论文),该模型通过改进 U-Net 结构和特征融合方法,在几乎不增加计算成本的前提下,提高了图像分割任务的准确性和效果。并且值得一提的是,它在性能表现上同样很优秀,因此能广泛应用于计算机视觉领域的各种应用中。
结尾
到这里,相信你已经学会如何在自己服务器上部署一款 AI 抠图工具了,是不是等不及要亲自尝试一番了呢?希望看完本文能对你有所帮助!如果想了解关于文中提到的在线图片设计器,也欢迎访问我的开源项目:迅排设计[3],相关介绍可以查阅这篇文章:
开源在线图片编辑器,支持PSD解析、AI抠图等,基于Puppeteer生成图片[4]
引用链接
[1] 在线体验: https://design.palxp.com/home?koutu=1[2] Github – ImageCutout.vue: https://github.com/palxiao/poster-design/blob/main/src/components/business/image-cutout/ImageCutout.vue[3] 迅排设计: https://design.palxp.com/[4] 开源在线图片编辑器,支持PSD解析、AI抠图等,基于Puppeteer生成图片: https://juejin.cn/post/7261774602481188923