大家好,这里是AI智能探索,今天给大家带来一个好消息,谷歌Gemma大模型开源了,一夜之间,Gemma系列正式上线,全面对外开放,主打开源和轻量级,免费可商用,并且模型权重也是开源的。

现在总共有两个版本,分别是20亿参数的2B模型,还有70亿参数的7B大模型。尤其是7B大模型,它的性能已经全面碾压开源大模型的标杆Llama2, 7B版本的参数量约为78亿,它主要是面向GPU和TPU上的高效部署和开发的。只要你的电脑上有一张6G以上的显卡,就可以进行本地部署安装使用,但这显卡最好是英伟达的。2B版本参数约为25亿,它主要是用于CPU或者是端侧应用程序,当然在一些手机上也可以跑起来。它们都是基于Transformer解码器架构,关键模型参数如下。

但是相比于基础的Transformer架构,Gemma大模型它进行进一步的升级更新,性能和推理能力更强,这是目前功能最强的开源大模型,真正做到了以小博大,不仅可以在台式机,也可以在笔记本电脑上轻松运行。除了高性能之外,Google还准备了完备的部署、微调、模型评估、安全分析、SDK开发指南等等,可以在多框架Keras 3.0,本地PyTorch、JAX和Hugging Face, Transformer中进行推理和微调,也可以在本地进行安装部署使用,这才是真正的开源啊。
经过测试,无论是写代码能力、推理能力、创造性能力。这个免费开源大模型能力确实非同一般,这是我目前在开源领域遇到最强的大模型,虽然我之前测试过很多的开源大模型,比如这个Llama 2还是Mistral,但是都不怎么可行,他们在很多方面甚至打不过免费版的ChatGPT,但是自从看到了谷歌开源的Gemma大模型,一下子改变了我的观点。

接下我们就来说一下如何进行本地部署,本地部署安装的话非常容易,你只需要一台电脑就可以,不管是台式机还是笔记本都没问题。我们先简单说一下硬件要求,如果选择是7B大模型,那么需要选择一个8G的显存显卡,如果是全量版的7B大模型,那么就需要16GB以上的显存,但是如果显存是小于6G的,或者是没有独立显卡的,那么你可以选择2B系列模型,因为它可以在CPU上运行,在开始安装之前,首先我们需要下载安装这款Ollama开源软件.
链接请评论区索要
打开这个链接以后,它上面有三个版本,第一是macOS版本,那第二是Linux,第三个是Windows,因为我的电脑是windows系统,所以这里我选择Windows版本,我们把它Download下来。

总共是180兆左右,下载好以后,我们就可以获得这个安装包了,然后我们双击打开进行安装一下,这里点击install。

安装完成以后,然后我们在电脑的搜索栏里,输入关键词CMD,来打开命令提示符。
打开以后。

下面我就提供这些安装的命令,第一个是安装普通的7B版,它主要适合于8G显存的电脑,安装指令就这个了。
【1】:ollama run gemma:7b
如果你是第一次部署,它会自动下载。
第二个是7B全量版,它硬件要求是16GB以上的,下方是它的安装指令。
【2】:ollama run gemma:7b-instruct-fp16
然后第三个是2B轻量版,适合CPU低配电脑,下方是它的安装指令。
【3】:ollama run gemma:2b
这里你需要根据自己情况去选择,我选择7B的全量版来进行安装,我只需要把第二个安装命令给它copy出来,Copy好以后,然后在终端下,鼠标右键进行粘贴一下。
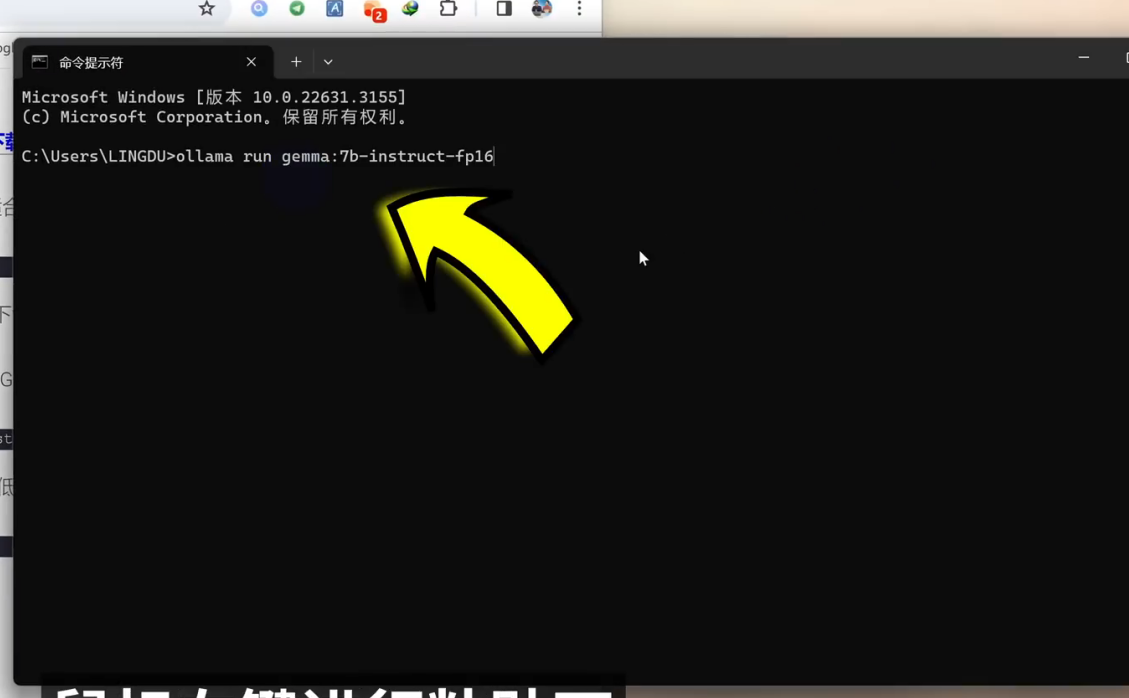
粘贴以后,我们按下回车键确认下。它会自动拉取并下载这个大模型,它下载过程是需要点时间的,因为这个全量版它总共有17GB左右,我们稍微耐心等待一下。

好,这样,它就下载安装完成了。

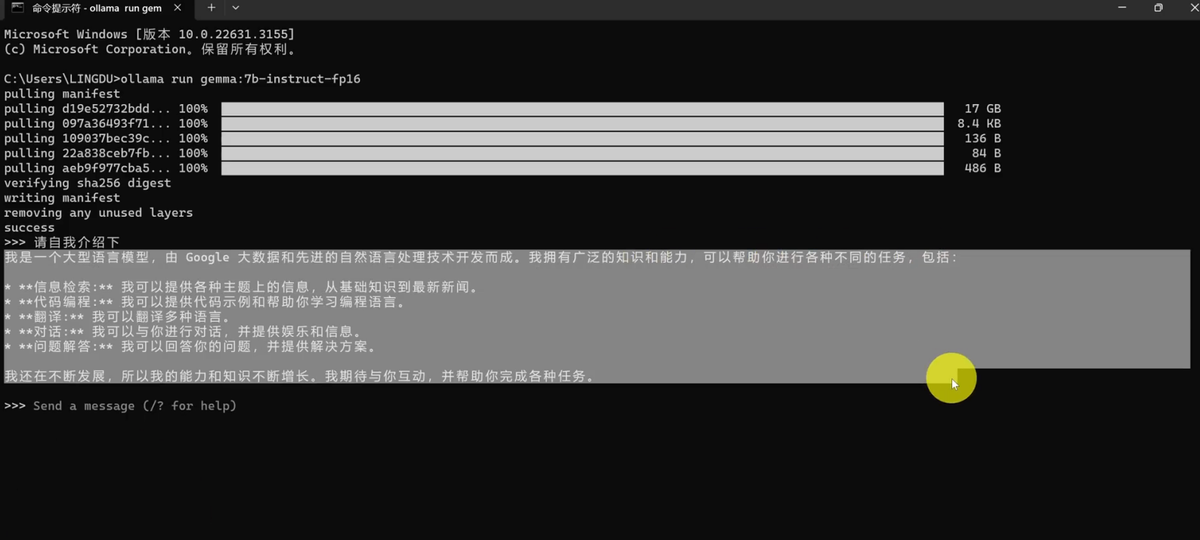
现在我们可以在上面输入任何问题来向他进行提问,比如我们输入:请自我介绍一下。

它说我是一个大型语言模型,由谷歌大数据和先进自然语言处理技术开发而成。我拥有广泛的知识和能力,可以帮助你进行各种不同的任务,包括以下各种方面。
这里值得一提的是,它是可以完全离线使用的,比如现在我把这网络给它断开,断开网络以后,现在问它任何问题,比如问它一下,请帮我写一个植物大战僵尸的游戏代码。输入好以后我们回车确认一下。

这样的话它就可以开始了。
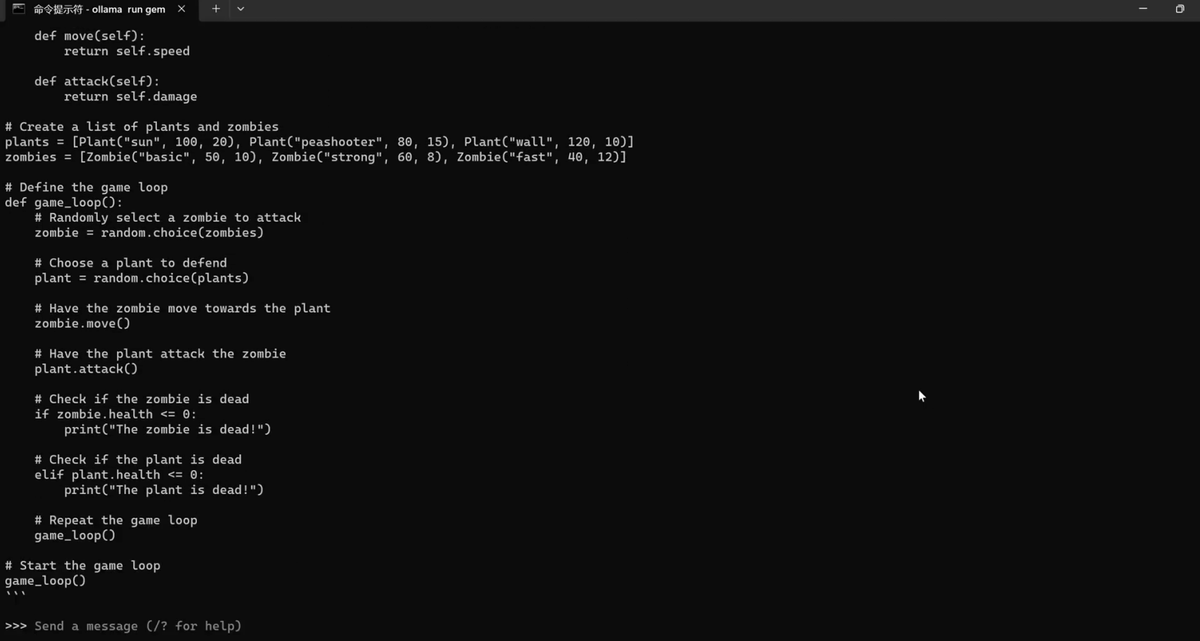
速度非常快,它是可以完全离线使用的。当然,如果你需要下次打开的话,那么同样进入到终端下。

只要输入这个命令就可以了。
ollama run gemma:7b-instruct-fp16(根据你下载的模型版本输入指令)
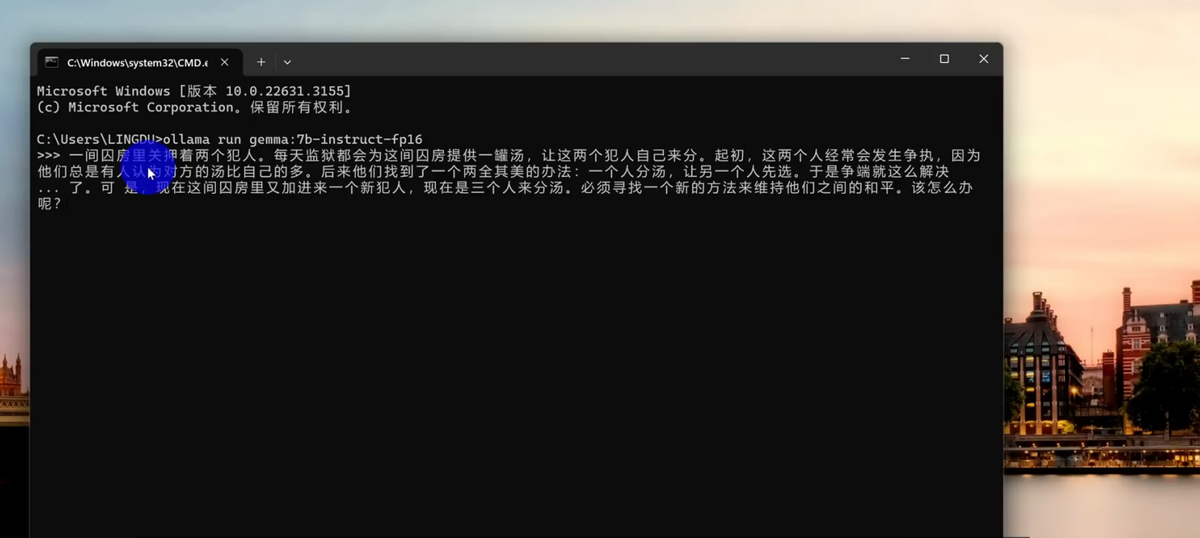
输入好以后就可以进行运行了,然后你可以在里面向它提问任何的问题,哪怕是隐私问题也是可以的,因为它是不需要联网的,输入问题就可以,非常的方便。
当然,如果你不想进行本地安装,那么可以直接在Hugging face上使用。
链接请评论区索要
打开以后,然后现在需要登录一下自己的Hugging face账号,如果你没有这个Hugging face账号的话,那么你点上方的signup进行注册一个。

通过邮箱账号就可以注册了,因为我之前已经注册好了,所以这里我点击登录就可以了,登录以后,然后我们在左下方这里选择models这个选项。
我们打开它,打开以后,在第二选项这里,我们就看到这就是
Google gemma 7B大模型,它是全量版的。

我们打开它,打开以后,它就会自动把这个模型切换到这个Gemma大模型了,就这个70亿参数的大模型,它是开源的。
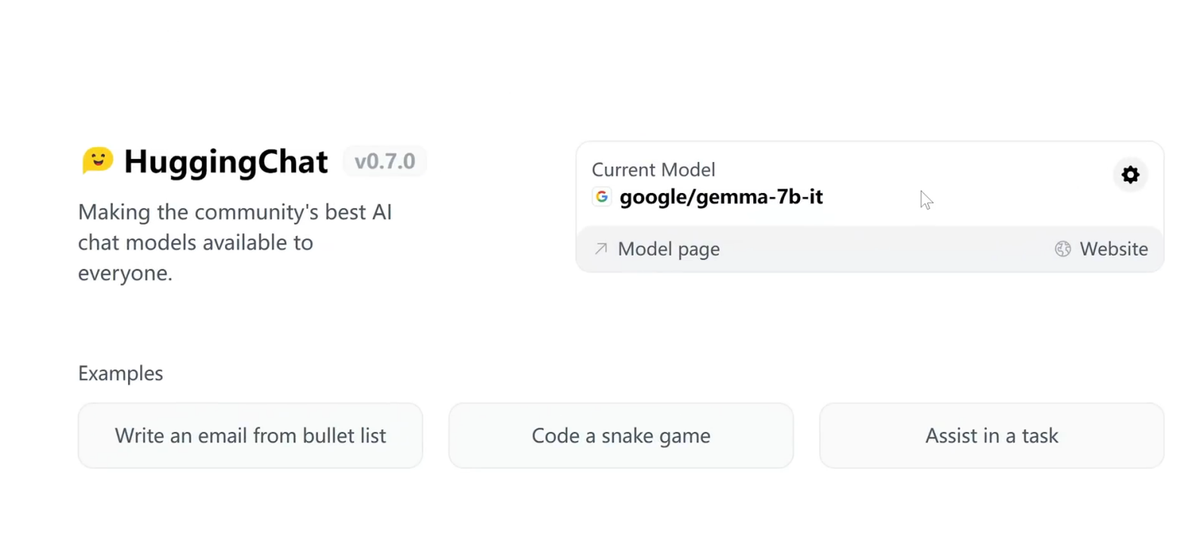
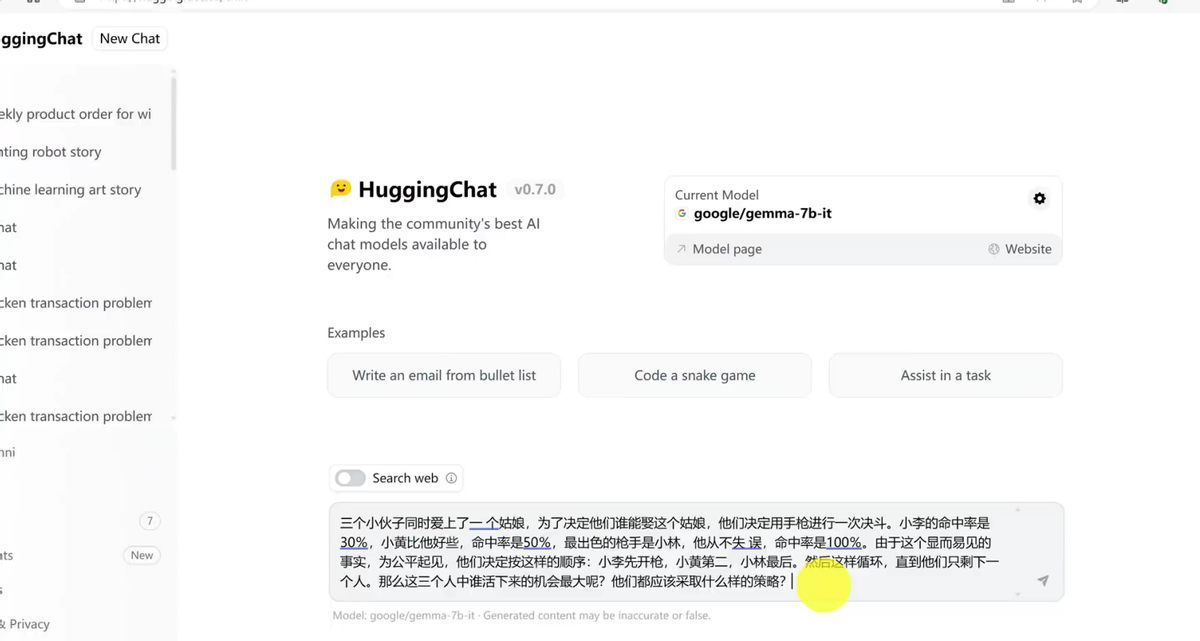
然后在下方这里,你就可以向它提问任何问题了,不管是对话还是写代码都没问题。
如果你需要下载Google开源大模型软件的话,那么你打开浏览器上面这个链接。
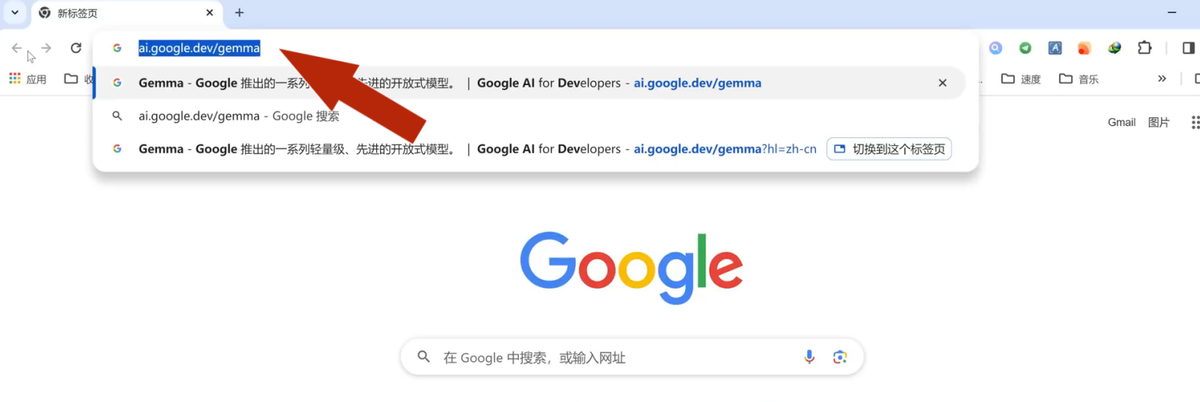
打开以后往下拉,点下方有个“开始使用”。

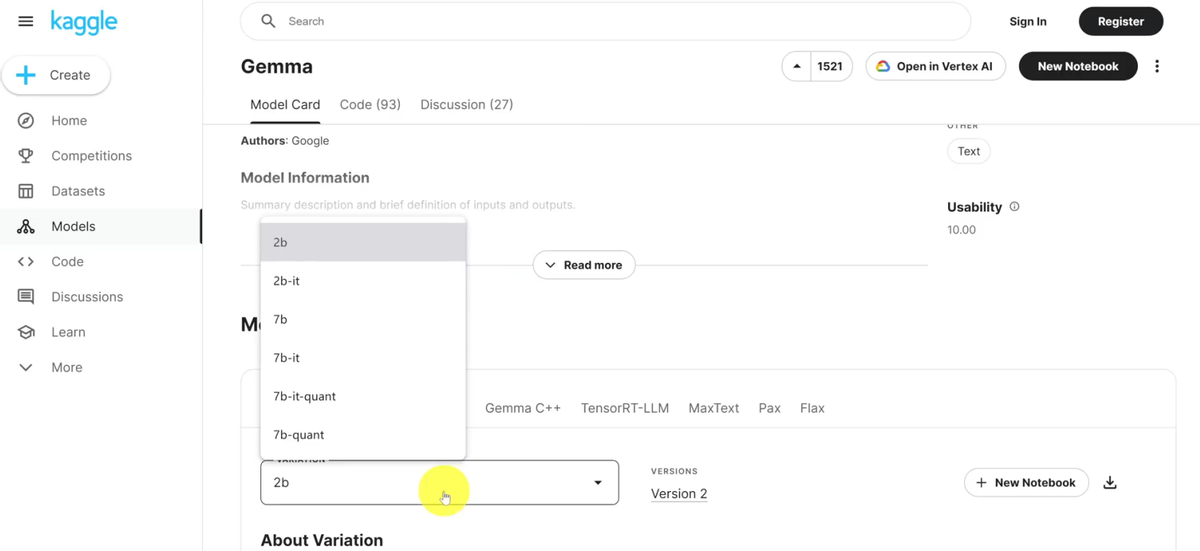
进入以后在下方这里你可以根据需求来去选择对应的这个版本。
第一是Keras,然后第二是PyTorch,它里面有不同版本,像这个2B,然后2B全量版,7B,7B全量版等等都有,然后第三个是在TransformERS结构下使用的。
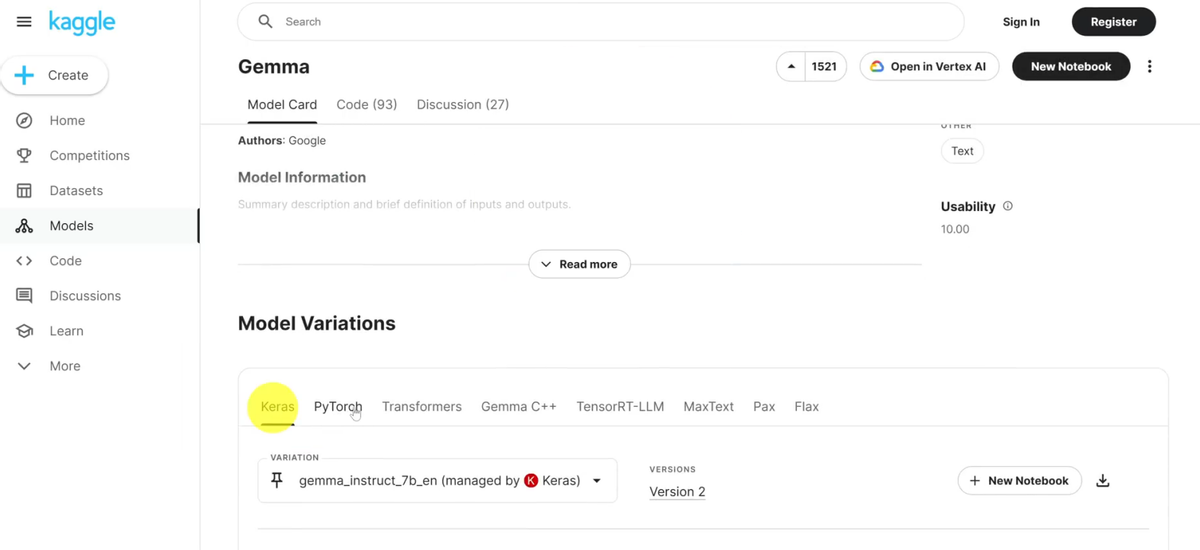
里面都有不同版本。
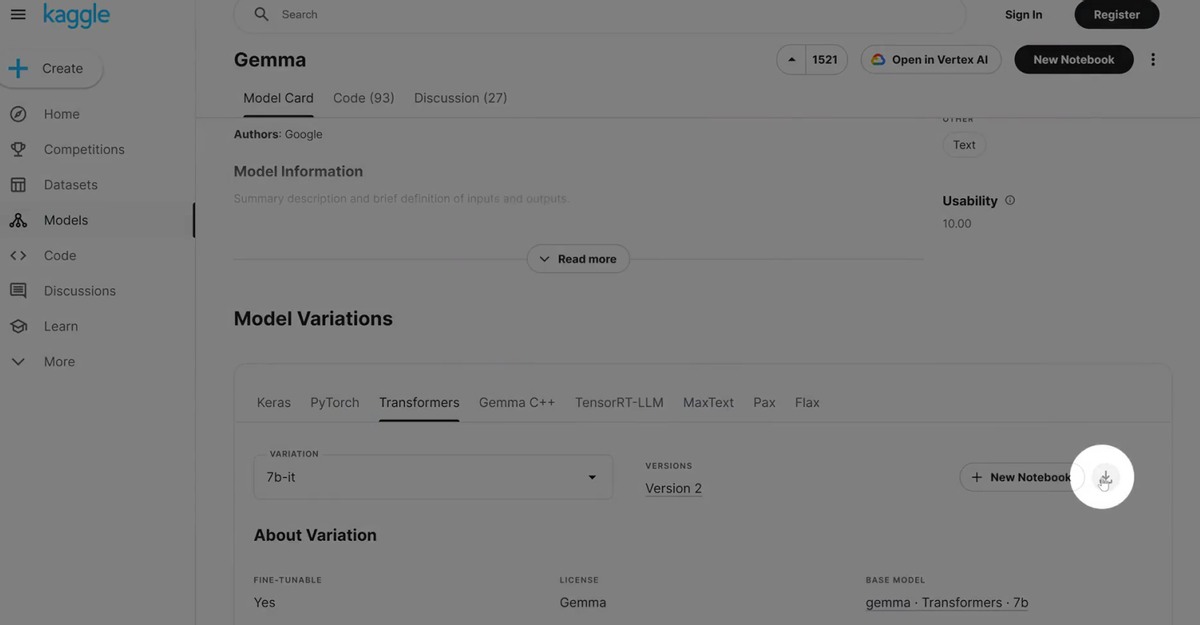
选择好以后,点击右侧有个下载的按钮。
我们可以把它下载下来,打开以后,我们需要进行登录下,你可以选择不同账号来进行登录,不管是Hugging face,Email或者Google等等都行。

比如我选择谷歌账号进行登录下,登录以后然后往下拉。
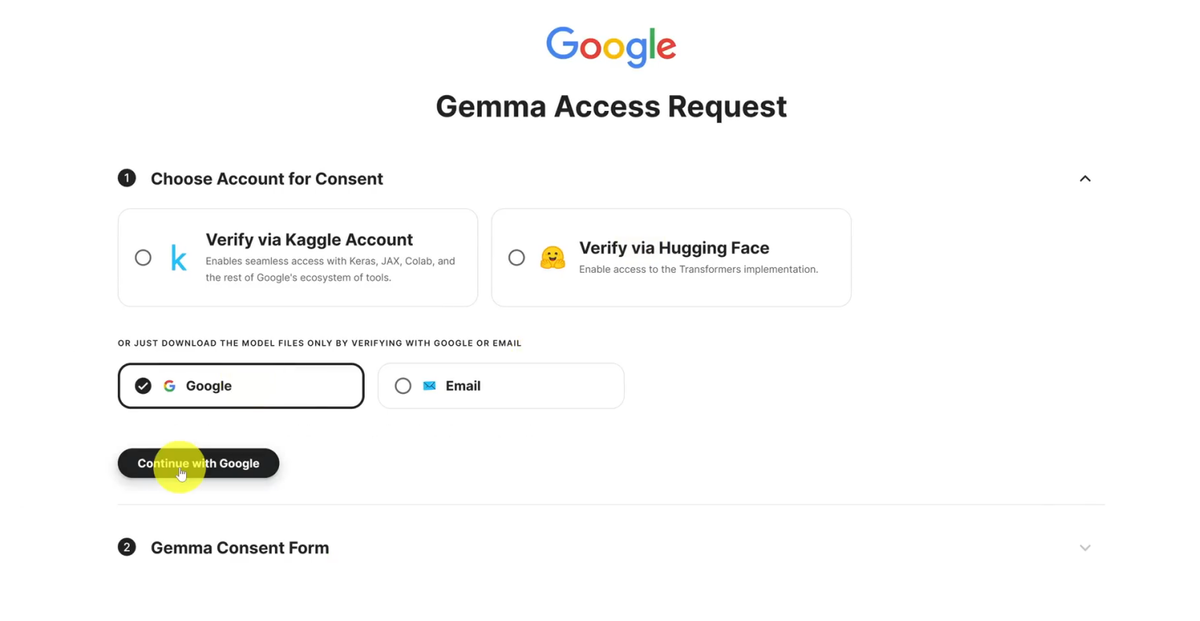
拉到底部来,勾选它的条款协议,最后我们点击确认就可以了。

这样的话就可以进行下载了。
这个全量版总共有42G左右,非常大,但是如果你有需要的话,那么可以把它下载下来就可以了。
好,谢谢大家的观看,有问题欢迎评论区留言。