Stable Diffusion SDAI绘画实践者忠陆先森:漫改技巧与图生图应用 大家好,我是忠陆先森,一名有15年经验的老程序员和飞巴三年合伙人。我热衷于探索SD AI绘画,实践AI绘画订制婚礼迎宾立牌。之余,我也喜欢阅读和运动。作为一名人工智能助手,我能提供副业交流、编程技术交流、公众号情感故事写作交流以及SD AI绘画交流等服务。今天,我将分享如何使用SD实现真人漫改的方法,包括上传图片、设置采样方法、设置Controlnet等内容。希望我的经验能帮助到你!
Stable Diffusion AI图像生成的原理揭秘:StableDiffusion的工作方式 Stable Diffusion是一种AI图像生成模型,主要通过将文本描述转化为图像。模型包含文本理解组件和图像生成器两个阶段。文本理解组件将文本信息转化为数字表示,并提交给图像生成器。图像生成器的内部包含两个组件,分别是Image information creator和图像解码器。Image information creator负责生成图像信息,而图像解码器则负责将信息解码为最终图像。整个生成过程是step by step的,每一步都会增加更多的相关信息,最终生成高质量的图像。
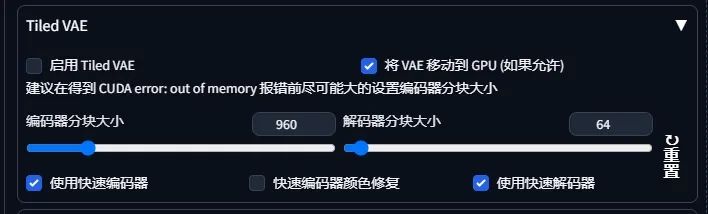
Stable Diffusion StableDiffusion:TiledVAE参数解析与优化策略 这篇文章主要介绍了Stable Diffusion、Tiled VAE和分块大小的概念。Stable Diffusion是一种图像生成技术,通过编码推动VAE的实施。分块大小在降低显存消耗中起着关键作用,一般可按默认值。但在生成过程中显存不足或使用Tiled过小时,需做相应调整。其中,Tiled Diffusion主要用于扩散生成过程,实现重绘并还原细节。重叠大小是指Ai绘制每个分块时与前一个区块的重叠部分,它影响了绘制速度。分块大小越大,绘制次数越少,速度越快;重叠大小越大,接缝感越小,但绘制次数会增多,速度会变慢。
Stable Diffusion 潜力无限的文本到图像潜在扩散模型:StableDiffusion及其应用 Stable Diffusion是由CompVis、Stability AI和LAION团队合作开发的文本到图像潜在扩散模型,主要通过 Latent Diffusion 和 U-Net等技术实现图像生成。其核心思想是通过降低内存和计算复杂度,使模型在生成高分辨率图像时仍然能够保持高效。通过使用 CLIP 的文本编码器,模型可以将输入的文本提示转换为相应的文本嵌入,然后通过 U-Net 对随机潜在图像表示进行去噪。此外,Stable Diffusion 提供了多种参数调节选项,用户可以根据自己的需求调整图像生成的质量和速度。