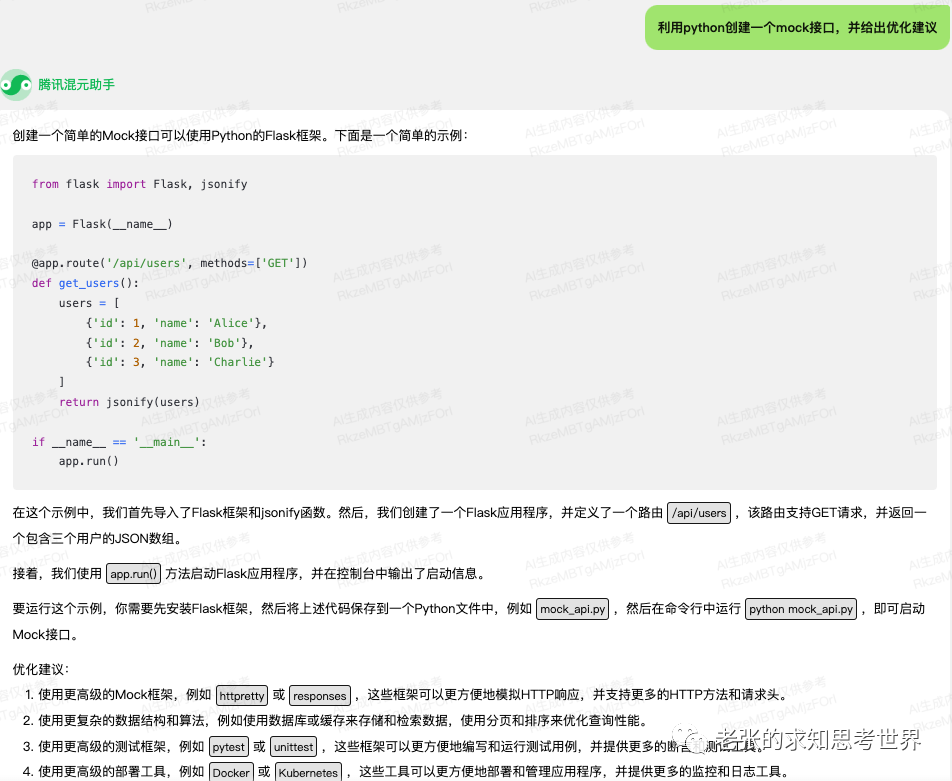
文章主题:阿里开源大模型, 多模态大模型, 通义千问-7B, 图像
阿里开源大模型,又上新了~
继通义千问-7B(Qwen-7B)之后,阿里云又推出了大规模视觉语言模型Qwen-VL,并且一上线就直接开源。

基于通义千问-7B构建的Qwen-VL多模态大模型具备强大的功能,能够接收图像、文本以及检测框等多種輸入形式,並且在處理文本信息的同时,亦能將檢測框的結果進行輸出。这样的設計使得Qwen-VL能夠应对各種複雜的問題場景,為用戶帶來更加全面且高效的解決方案。
以阿尼亚为例,当我们输入一张她的图片,并启动Qwen-VL-Chat工具时,该程序能够不仅准确地概括图片的主要内容,还能够精准地定位到画面中的阿尼亚。

在各种测试任务中,Qwen-VL充分展示了其“六边形战士”的独特魅力。在四大类多模态任务的标准化英语评估中(包括零散图像字幕/视觉问答/文档视觉问答/ grounded 语义表示),它均取得了领先地位(SOTA)。

开源消息一出,就引发了不少关注。


具体表现如何,咱们一起来看看~
首个支持中文开放域定位的通用模型
先来整体看一下Qwen-VL系列模型的特点:
多语言对话:支持多语言对话,端到端支持图片里中英双语的长文本识别;
多图交错对话:支持多图输入和比较,指定图片问答,多图文学创作等;
首先,我们成功研发出了一个全新的通用模型,它能够支持中文开放域定位。这个模型的主要特点在于,它可以使用中文开放域的语言表达来进行检测框的标注,从而在画面中精准地锁定目标物体。这一技术突破性的进展,无疑为我们提供了更精确、更高效的图像识别方式,也进一步提升了我们的技术实力。
相较于当前其他采用224分辨率的LVLM(大型视觉语言模型)而言,Qwen-VL作为首个公开的448分辨率LVLM模型,具有显著优势。更高的分辨率有助于提升文本识别中的细粒度、文档问答以及检测框标注的精确性。
按场景来说,Qwen-VL可以用于知识问答、图像问答、文档问答、细粒度视觉定位等场景。
在医疗环境中,有时会碰到一些外国朋友看不懂中文的情况。例如,有这样一个场景:一位无法理解中文的外国患者走进医院,面对复杂的导览图感到无所适从,不知道如何找到对应的科室。这时,他们可以尝试将导览图和问题一起交给Qwen-VL,利用其强大的图像识别和自然语言处理能力,实现中英文之间的转换,从而顺利地完成就医过程。

再来测试一下多图输入和比较:

虽然没认出来阿尼亚,不过情绪判断确实挺准确的(手动狗头)。
视觉定位能力方面,即使图片非常复杂人物繁多,Qwen-VL也能精准地根据要求找出绿巨人和蜘蛛侠。

技术细节上,Qwen-VL是以Qwen-7B为基座语言模型,在模型架构上引入了视觉编码器ViT,并通过位置感知的视觉语言适配器连接二者,使得模型支持视觉信号输入。

具体的训练过程分为三步:
预训练:只优化视觉编码器和视觉语言适配器,冻结语言模型。使用大规模图像-文本配对数据,输入图像分辨率为224×224。
多任务预训练:引入更高分辨率(448×448)的多任务视觉语言数据,如VQA、文本VQA、指称理解等,进行多任务联合预训练。
监督微调:冻结视觉编码器,优化语言模型和适配器。使用对话交互数据进行提示调优,得到最终的带交互能力的Qwen-VL-Chat模型。
研究人员在四大类多模态任务(Zero-shot Caption/VQA/DocVQA/Grounding)的标准英文测评中测试了Qwen-VL。

结果显示,Qwen-VL取得了同等尺寸开源LVLM的最好效果。
另外,研究人员构建了一套基于GPT-4打分机制的测试集TouchStone。

在这一对比测试中,Qwen-VL-Chat取得了SOTA。
如果你对Qwen-VL感兴趣,现在在魔搭社区和huggingface上都有demo可以直接试玩,链接文末奉上~
Qwen-VL支持研究人员和开发者进行二次开发,也允许商用,不过需要注意的是,商用的话需要先填写问卷申请。
— 完 —

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!