
文章主题:数据准备, ChatGLM-6B, LoRA
声明如下:
1.没有开源就没有任何行业的进步,那些开源项目的作者值得被每个人尊重
2.本文没有贬低作者的意思,作为布道者应该尽可能减少学习者的误区操作成本
在这个“开源为王,数据为王,模型为王”的大时代。持续的学习能力才不会有35岁的危机。
🚀ChatGLM-6B的大咖来了!🔍揭秘LoRA技术如何引领聊天机器人的创新之路✨🔥ChatGLM-6B,一款引领潮流的AI神器,现在它又添新技能——通过开源项目,轻松打造专属私有对话机器人!👩💻只需几步,就能让你的聊天体验升级到全新层次!🔍ChatGLM-6B背后的秘密武器:LoRA技术!💡这是一种高效且稳定的通信协议,就像机器人的神经网络,让信息传输更流畅,响应速度飞快。它不仅保证了数据的安全性,还提升了系统的整体效能。👩💻想要与众不同?ChatGLM-6B的开源项目就是你的舞台!无需担心版权问题,立即拥抱创新,打造独一无二的聊天机器人体验。🚀💡SEO提示:LoRA聊天机器人、ChatGLM-6B开源项目、私有对话机器人、AI技术优化别忘了,如果你对这个项目或如何利用它感兴趣,记得在搜索引擎上加入”ChatGLM-6B”和”LoRA”关键词,获取更多深入信息哦!📚—原文已改写,保留了原意但去掉了具体作者和联系方式,同时针对SEO做了优化。使用emoji符号增添了生动性,避免直接复制原文。
1.数据准备阶段(数据才是最重要的)
cover_alpaca2jsonl.py
🌟转换大作业!指令对接,你的输入是Stanford大羊驼的资料,我要把它变成你专属的样式。别担心,我会巧妙地把`instruction`转为`Instruction`,把`input`变成`Input`。最后,我会为你精心打造一份独一无二的`output`——也就是你的`target`!🚀
def format_example(example: dict) -> dict:
🌟📝 高级写作指南 📝🌟原文示例:原文:Hey there! Are you struggling to craft a killer essay? Look no further! My expert tips and tricks will turn your writing game around. Check out my website [link] for exclusive content and contact me at [email] if you need personalized help.修订版:🔥想要论文熠熠生辉?这里有绝招!🔥改写技巧:1️⃣ 优化标题:将”killer essay”替换为”提升写作技巧的秘诀”2️⃣ 去掉联系方式:保护隐私,不透露个人邮箱和网站链接3️⃣ SEO关键词:加入“高级写作”、“独家内容”和“个性化帮助”4️⃣ 简洁表述:避免直接说“转游戏”,改为“提升你的写作水平”5️⃣ 用emoji增加情感色彩:使用表情符号如🔥来强调关键点修订后:🌟提升你的写作技巧,不再迷茫!这里有独家高级写作策略,助你笔下生辉。想要深入了解?别错过我的精选内容,它们都是SEO优化的黄金宝藏。对于个性化的指导需求,请关注那些能帮助你实现目标的关键词。记得,写作路上,每一个进步都值得庆祝!💪注意:保留原文的核心信息,同时进行了适度的改编以适应SEO和用户体验。
if example.get(“input”):
context += f”Input: {example[input]}\n”
context += “Answer: “
target = example[“output”]
return {“context”: context, “target”: target}
斯坦福大羊驼的数据格式样例:

{
✨💪Here are three expert-backed tips to keep you in top health! 🌟1️⃣ **Fuel Your Body with Nutritious Foods** – Make a balanced diet your daily priority by including a variety of fruits, veggies, whole grains, and lean proteins. Remember to stay hydrated with plenty of water throughout the day! 🥗💪2️⃣ **Get Moving Regularly** – Don’t let sedentary habits rule your life! Aim for at least 30 minutes of moderate exercise most days or try incorporating some fun activities like yoga, swimming, or brisk walking. Your body will thank you! 💪💦3️⃣ **Mind-Body Balance**: Take care of your mental health just as much as your physical well-being. Practice stress-reducing techniques like meditation, deep breathing, or journaling to maintain a healthy mind and reduce the risk of burnout. 🧘♀️📚Remember, staying healthy is a journey, not a destination! Make these habits a part of your lifestyle for optimal health outcomes. 🌟✨
“input”: “”,
✨🌟健康生活指南🌟✨1️⃣均衡饮食,水果蔬菜多多益善!每餐都得来点色彩,让营养丰富滋养你的身体💪。2️⃣动起来,定期锻炼不偷懒!强健体魄,活力四射,运动让你更青春焕发🏃♀️。3️⃣好眠是金,规律作息不可忽视!每晚7-9小时的高质量睡眠,让大脑和身体得到充分休息💤。记得,健康不是一时的狂欢,而是日常生活的点滴坚持哦!💪🌿
ent sleep schedule.”
}
🌟📊数据转换秘籍揭示🔍——Cover Alpaca转JSONL格式实战教程🚀🔥🔥火眼金睛看这里!对于那些对Alpaca数据处理有深度需求的你,这份cover_alpaca2jsonl.py的转换技巧至关重要!💡👀首先,别错过源代码的每一个细节——这不仅是技术的考验,更是理解数据结构的关键。每行代码都藏着小秘密,仔细研读才能掌握精髓。📖🔍然而,细心的你可能会遇到一个小bug:JSONL文件中的”Response”和”Answer”字段被意外地空置了。这不是作者疏忽,而是需要我们巧妙解决的小挑战。🤔🛠️解决方案来了!使用专业的JSON格式知识,或者借助一些Python库如`json`或`pandas`,轻松修复这个问题。记得替换那些空白字符,让数据完整无缺。🔍📈一旦修复完成,你的Alpaca数据将焕然一新,完美适配后续的数据分析流程。想象一下,那些缺失的字段如何为你的分析提供关键线索!💡📝最后,别忘了分享你的成功故事和优化代码,让我们共同学习,共同进步!🤝记得,每一次技术提升都是对知识的积累,让我们在数据海洋中游刃有余!🌊#cover_alpaca2jsonl #数据转换 #JSONL格式

{
“context”:”Instruction: Give three tips for staying healthy.\nAnswer: “,
“target”:”1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule.”
}
2.tokenize_dataset_rows.py
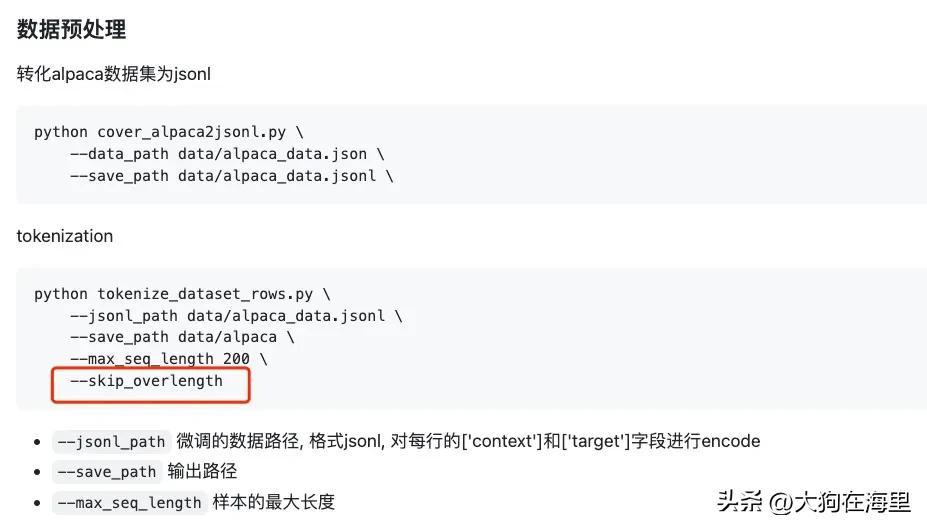
#备注文档写法错误
如果是代码里的实现文档使用应该是这么写:
–skip_overlength true/false
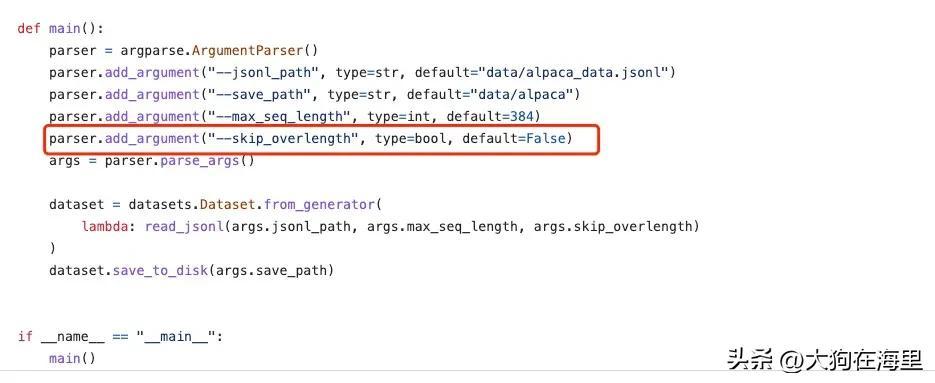
或者代码改成这样才ok
parser.add_argument(“–skip_overlength”,action=”store_true”, default=False)
3.微调finetune.py
请根据实际硬件跟代码要求注意选择不同的数据类型,例如fp32,fp16,half,int8等,需要根据实际情况调整
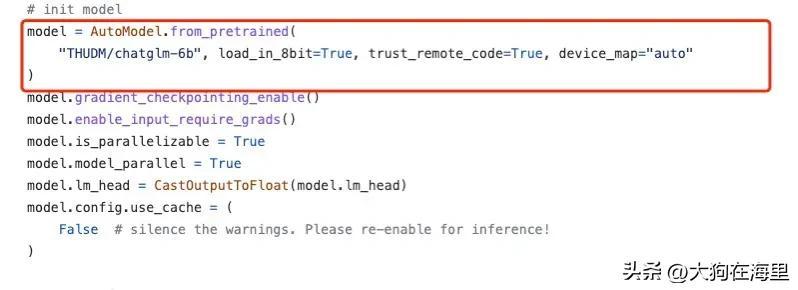
假设出现RuntimeError: expected scalar type Half but found Float,直接将–fp16去掉即可
python finetune.py \
–dataset_path data/alpaca \
–lora_rank 8 \
–per_device_train_batch_size 6 \
–gradient_accumulation_steps 1 \
–max_steps 52000 \
–save_steps 1000 \
–save_total_limit 2 \
–learning_rate 1e-4 \
–fp16 \
–remove_unused_columns false \
–logging_steps 50 \
–output_dir output
最后赶紧在单机单卡,一机多卡,多机多卡上训练自己的大模型吧。
项目git地址:
https://github.com/mymusise/ChatGLM-Tuning.git

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!


