手把手教你本地部署清华大学KEG的ChatGLM-6B模型(CPU/GPU)
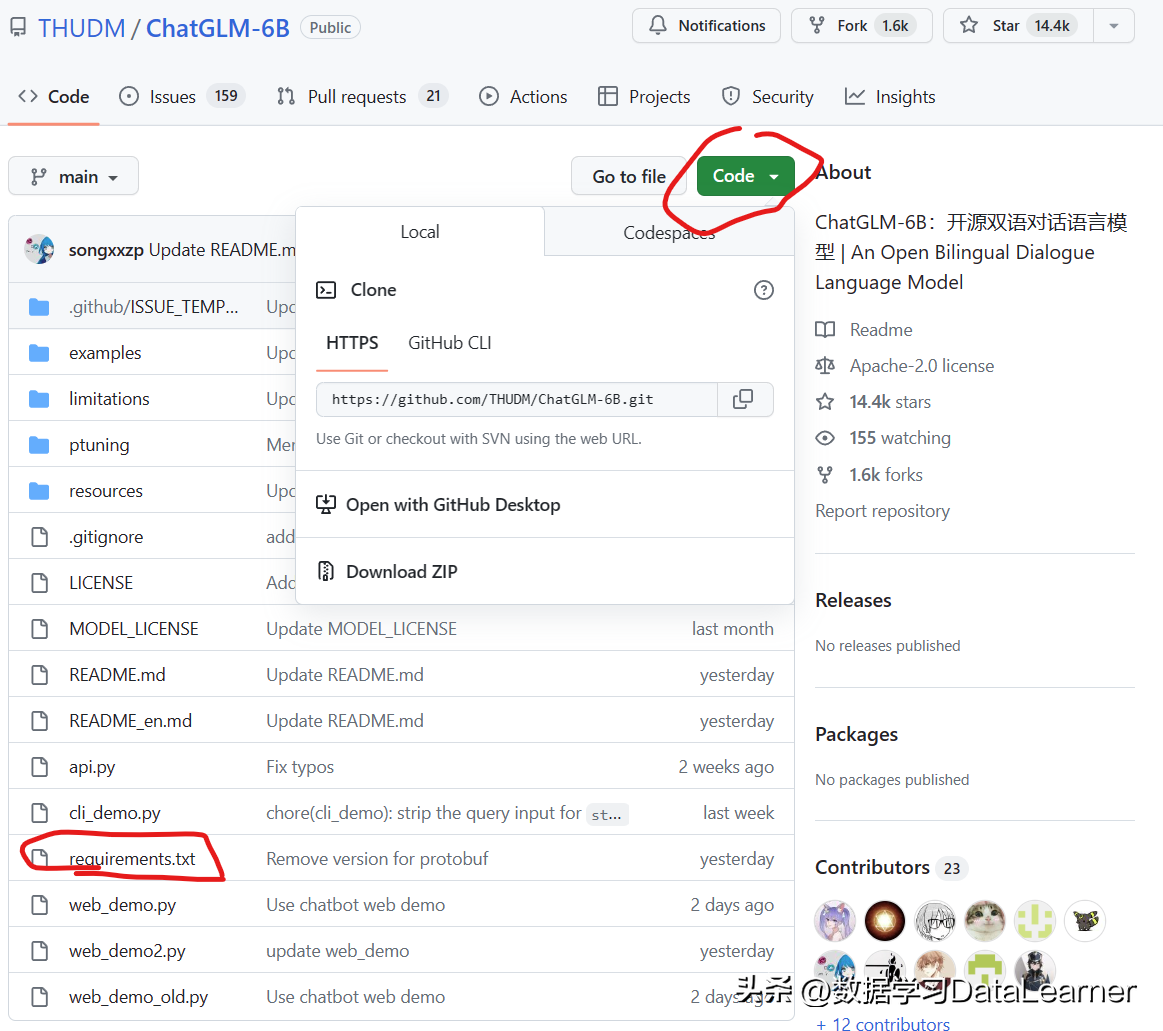
ChatGLM-6B是清华大学知识工程和数据挖掘小组发布的一个类似ChatGPT的开源对话机器人,由于该模型是经过约1T标识符的中英文训练,且大部分都是中文,因此十分适合国内使用。 本文来自DataLearner官方博客:手把手教你本地部署清华大学KEG的ChatGLM-6B模型——Windows+6GB显卡版本和CPU版本的本地部署 | 数据学习者官方网站(Datalearner) ChatGLM-6B在DataLearner官方的模型卡信息:ChatGLM-6B(ChatGLM-6B)详情 | 数据学习 (DataLearner) 根据GitHub开源项目公开的信息,ChatGLM-6B完整版本需要13GB显存做推理,但是INT4量化版本只需要6GB显存即可运行,因此对于个人本地部署来说十分友好。遗憾的是,官方的文档中缺少了一些内容导致大家本地部署会有很多问题,本文将详细记录如何在Windows环境下基于GPU和CPU两种方式部署使用ChatGLM-6B,并说明如何规避其中的问题。 安装前说明部署前安装环境1、下载官方代码,安装Python依赖的库2、下载INT4量化后的预训练结果文件Windows+GPU部署方案1、Windows+GPU方案的必备条件2、运行部署GPU版本的INT4量化的ChatGLM-6B模型Windows+CPU部署方案1、Windows+CPU方案的必备条件2、运行部署CPU版本的INT4量化的ChatGLM-6B模型总结 安装前说明 尽管ChatGLM-6B的GitHub上提供了安装部署的教程,但是由于其提供的代码、预训练模型、配置文件并不是统一在一个地方,因此对于一些新手来说很容易出现各种错误。 此外,由于大多数人可能只有较少内存的GPU,甚至是只有CPU,那么只能部署量化版本的模型,这里也会有不一样的。 最后,部署ChatGLM-6B目前涉及到从GitHub、HuggingFace以及清华云的地址,下面我们将详细说明如何操作。 部署前安装环境 在部署ChatGLM-6B之前,我们需要安装好运行的环境。下面2个步骤是不管你部署CPU还是GPU版本都需要做的。 1、下载官方代码,安装Python依赖的库 首先,我们需要从GitHub上下载ChatGLM的requirements.txt来帮助我们安装依赖的库。大家只需要在GitHub上下载requirements.txt即可。下载地址:https://github.com/THUDM/ChatGLM-6B 文件如下图所示: 这个文件记录了ChatGLM-6B依赖的Python库及版本,大家点击右上角Code里面有Download ZIP,下载到本地解压之后就能获取这个文件。然后执行如下命令即可 pip install -r requirements.txt 注意,这是从cmd进入到requirements.txt文件所在的目录执行的结果,这部分属于Python基础,就不赘述了。 需要注意的是,ChatGLM依赖HuggingFace的transformers库,尽管官方说: 使用 pip 安装依赖:pip install -r requirements.txt,其中 transformers 库版本推荐为 4.27.1,但理论上不低于 4.23.1 即可。 但是实际上,必须是4.27.1及以上的版本才可以,更低版本的transformers会出现如下错误: AttributeError: Logger object has no attribute “warning_once”...