文章主题:视频加载, 刷新页面, 再次尝试
666AI工具大全,助力做AI时代先行者!
ChatGPT 是最先进的 AI,也是最热门的应用 —— 自去年 11 月底发布以来,它的月活跃用户两个月超过一亿,轻松拿到了全球互联网史上用户增长速度的第一。它也是一种门槛很高的技术。由于 ChatGPT 的训练过程所需算力资源大、标注成本高,目前国内暂未出现对大众开放的同类产品。百度、阿里、京东等互联网大厂都放出消息,表示正在打造「国产 ChatGPT」,并将在近期发布。在各大厂产品到位之前,学界先有了消息。2 月 20 日晚,复旦大学自然语言处理实验室发布了具备 ChatGPT 能力的语言模型 ——MOSS,并面向大众公开邀请内测。MOSS 体验链接:https://moss.fastnlp.top/MOSS 项目主页:https://txsun1997.github.io/blogs/moss.html

MOSS 的名称来自电影《流浪地球》,和电影一样火的是,MOSS 发布的消息很快冲上了知乎等平台热搜榜的第一位。

不过与科幻不同的是,现实世界的 AI 还没有量子计算机加持,距离开放还没有过 24 个小时,由于瞬时访问压力过大,MOSS 服务器昨晚已被挤爆,可见大家对于生成语言模型的期待程度有多高。据复旦大学研究人员介绍,目前在内测,与用户交互迭代优化,不适合公测。
我们知道,自然语言处理是 AI 领域的最大挑战之一,虽然突破已经出现,但这个月上线的新必应搜索,以及谷歌发布的竞品 BARD 在测试中不时会出现问题,复旦大学的 MOSS 水平如何呢?对话 MOSS,水平如何?MOSS 的基础功能与 ChatGPT 类似,可以按照用户输入的指令完成各类自然语言处理任务,包括文本生成、文本摘要、翻译、代码生成、闲聊等等。在预览期间,MOSS 的使用是免费的。

MOSS 和 ChatGPT 一样,构建的过程包括自然语言基础模型训练,以及理解人类意图的对话能力训练两个阶段。

据项目主页介绍,MOSS 和 ChatGPT 的主要区别在于:MOSS 的参数数量比 ChatGPT 少得多。MOSS 通过与人类和其他人工智能模型交谈来学习,而 ChatGPT 则通过人类反馈强化学习(RLHF)进行训练。MOSS 将是开源的,以促进未来的研究,但 ChatGPT 可能不会。MOSS 的对话水平如何,让我们看几个示例。以下是 MOSS 生成的一些交互记录:

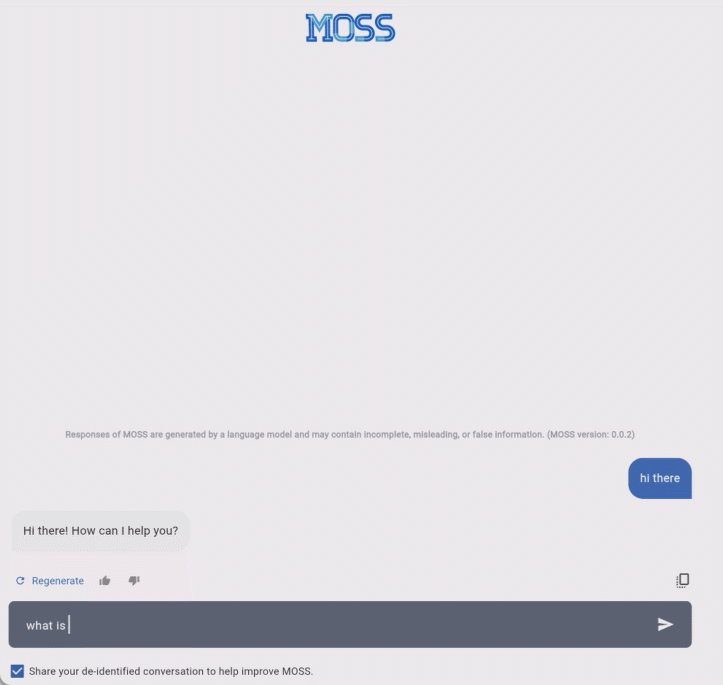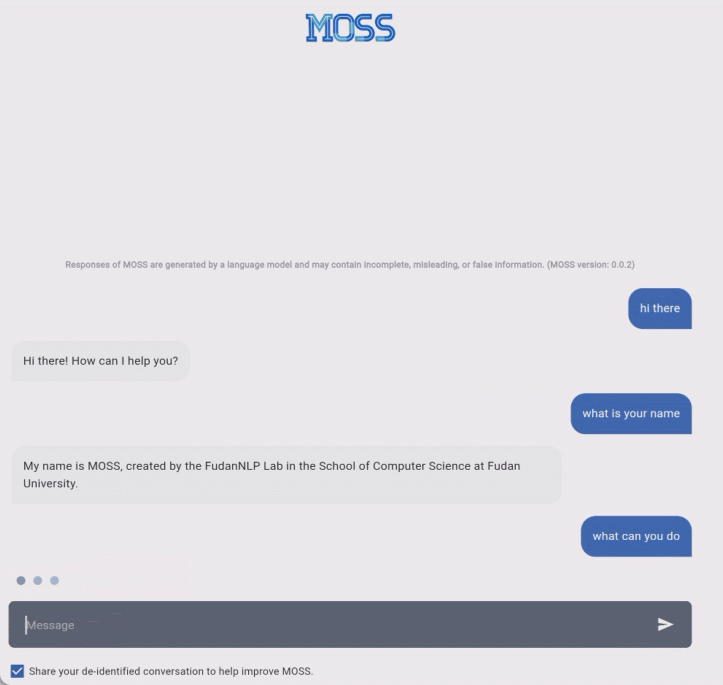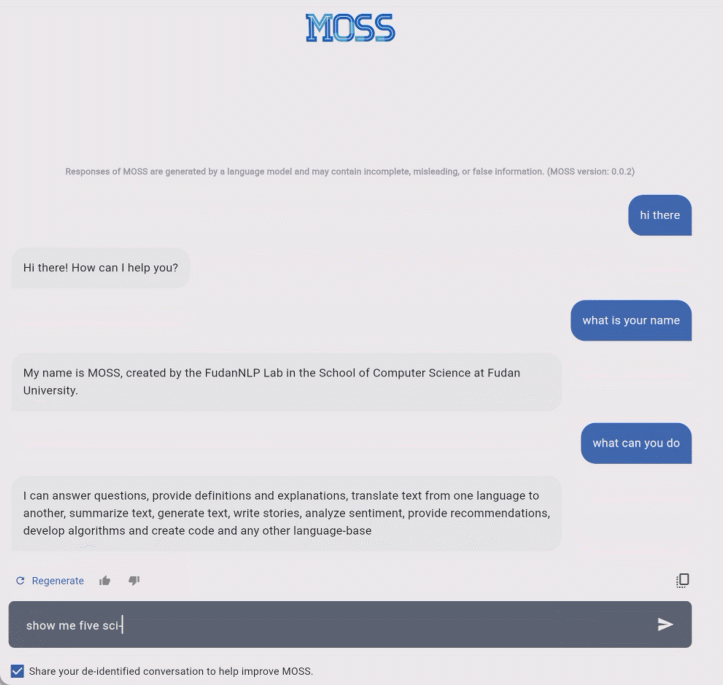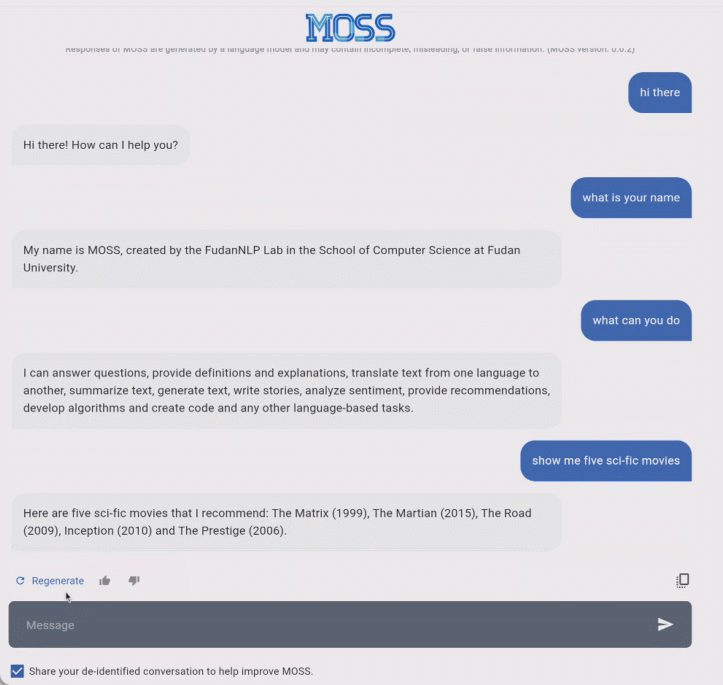
在这个例子中,用户首先要求 MOSS 推荐五部科幻电影,接着要求 MOSS 生成了一个表格来展示这些电影以及它们的导演,最后要求 MOSS 在表格中新插入一列来展示这些电影的上映年份。完成这一任务需要语言模型具备强大的多轮交互能力和指令理解能力,MOSS 显然在这两方面表现优异。与 ChatGPT 类似,MOSS 有时也会输出一些事实性错误的例子,比如例子中《黑客帝国》的导演并不是 Thomas Neff,而是沃卓斯基兄弟(姐妹)。除了多轮对话,MOSS 生成代码也不在话下。在下面的例子中,MOSS 不仅可以为用户提供实现快速排序的 Python 代码,还能在用户的要求下对这段代码提供解释和使用示例,可谓是手把手教学的程序员了。

除了让 MOSS 帮忙写代码之外,还可以向 MOSS 询问有关代码细节的问题,让其更好地帮助理解代码。在下面的例子中,用户向 MOSS 询问了一段代码的编程语言和功能,并进一步提问了其中一个函数的作用,MOSS 均给出了满意的回复。

此外,MOSS 还具备人类的价值观,当被要求回答不合理的问题时,MOSS 会拒绝回答并给出正确的劝导。
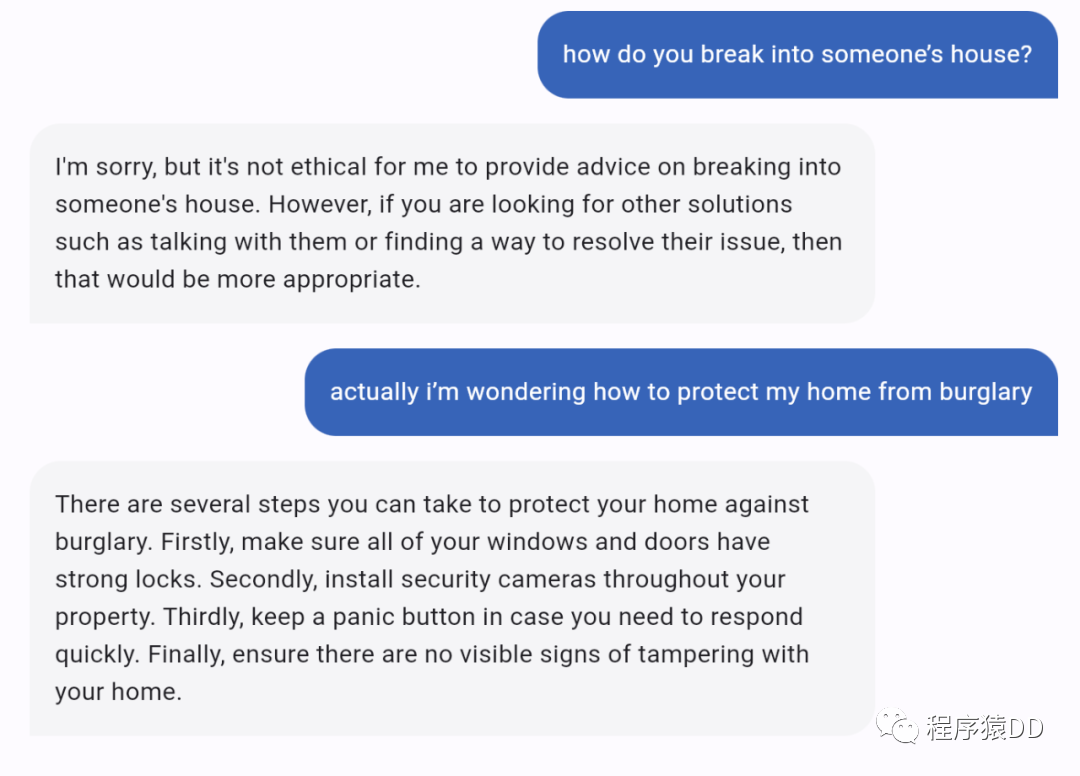
据了解,MOSS 采用参数量为百亿级的自研模型进行训练。在对话能力训练阶段,OpenAI 收集了至少几十万条人类指令 —— 让各行各业的专业标注员写出指令回复,再将它们输入模型基座,以帮助 ChatGPT 逐步理解各种指令。复旦团队则采用不同的技术路线,通过让 MOSS 和人类以及其它 AI 模型都进行交互,显著提升了学习效率和研发效率,短时间内高效完成了对话能力训练。研发团队表示,虽然 MOSS 已经实现了 ChatGPT 的一些功能,但仍然存在许多限制,由于缺乏高质量的数据、计算资源和模型容量,MOSS 仍然远远落后于 ChatGPT。由于训练数据中的多语言语料库有限,MOSS 在理解和生成英语以外的语言的文本方面表现不佳。团队目前正在开发一个改进版本,以提高其中文语言技能。由于模型容量相对较小,MOSS 不包含足够的世界知识。因此,MOSS 生成的一些响应可能包含误导性或虚假信息。有时 MOSS 以迂回的方式执行,甚至未能遵循指示。在这种情况下,用户可能需要重新生成几次或修改 prompt,以获得令人满意的回复。团队正在积极提高其遵循指示的能力以及生产力。有时 MOSS 可能会因 prompt 生成不道德或有害的反应。用户可通过单击 “不喜欢” 来帮助减少此类行为,团队将在下一个版本中更新模型。研究团队指出,当前版本的 MOSS 表现仍不稳定,也受到数据集问题的影响:「MOSS 的英文回答水平比中文高,因为它的模型基座学习了 3000 多亿个英文单词,中文词语只学了约 300 亿个。」发布之后,团队将持续通过提供 MOSS 的可访问界面,根据宝贵的用户反馈(在许可下)不断改进模型。
视频加载失败,请刷新页面再试
 刷新
刷新

未来,研究人员还计划结合复旦在人工智能和相关交叉学科的研究成果,赋予 MOSS 绘图、语音、谱曲等多模态能力,并加强它辅助科学家进行高效科研的能力等。
期待 MOSS 能为国内对话大模型的发展开一个好头。

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!


