
文章主题:此次, Claude 2, 能力升级
机器之心报道
编辑:小舟、杜伟
此次,Claude 2 除了一大波能力上的升级,更重要的是大家都可以用了。
今日,那个被很多网友称为「ChatGPT 最强竞品」的人工智能系统 Claude 迎来了版本大更新。
Claude 2 正式发布!
据介绍,Claude 2 在编写代码、分析文本、数学推理等方面的能力得到加强,并且可以产生更长的响应。
更重要的是,用户可以在新的 beta 网站上免费试用,并且 Claude 2 商用 API 的价格与 1.3 版本相同。

机器之心在此前的文章中多次介绍过 Claude,它是由 OpenAI 离职人员创建的 Anthropic 公司打造的。在 ChatGPT 发布两个月后,该公司就迅速开发出了 Claude,可以完成摘要总结、搜索、协助创作、问答、编码等任务。
之后持续升级,五月份通过 100K Context Windows 将 Claude 的上下文窗口从 9k token 扩展到了 100k。
现在终于迎来了大版本更新。Anthropic 表示,Claude 2 基于此前从用户那里获得的反馈建议进行改进。
接下来看各方面能力细节。
Claude 2 在哪些方面得到了加强?
总的来说,Claude 2 注重提高以下能力:
Anthropic 致力于提高 Claude 作为编码助理的能力,Claude 2 在编码基准和人类反馈评估方面性能显著提升。
长上下文(long-context)模型对于处理长文档、少量 prompt 以及使用复杂指令和规范进行控制特别有用。Claude 的上下文窗口从 9K token 扩展到了 100K token(Claude 2 已经扩展到 200K token,但目前发布版本仅支持 100K token)。
以前的模型经过训练可以编写相当短的回答,但许多用户要求更长的输出。Claude 2 经过训练,可以生成最多 4000 个 token 的连贯文档,相当于大约 3000 个单词。
Claude 通常用于将长而复杂的自然语言文档转换为结构化数据格式。Claude 2 经过训练,可以更好地生成 JSON、XML、YAML、代码和 Markdown 格式的正确输出。
虽然 Claude 的训练数据仍然主要是英语,但 Claude 2 的训练数据中非英语数据比例已经明显增加。
Claude 2 的训练数据包括 2022 年和 2023 年初更新的数据。这意味着它知道最近发生的事件,但它仍然可能会产生混淆。
该研究进行了一系列评估实验来测试 Claude 2 的性能水平,包括对齐评估和能力评估两部分。
在模型对齐方面,该研究针对大模型的三个关键要求做了具体评估,包括:遵循指令、生成内容有用(helpfulness);生成内容无害(harmlessness);生成内容准确、真实(honesty)。
人类反馈评估
大模型在生成过程中应该遵循人类提供的指令,这将让生成结果符合要求、实际有用。针对这一点,该研究对 Claude 2、Claude 1.3 和 Claude Instant 1.1 进行了实验评估,并使用经典的对弈水平评估指标 ——Elo 分数,几个模型的评估结果如下图 1 所示:

偏见评估
Bias Benchmark for QA(BBQ)是用于评估模型对人群偏见的常用基准。该研究在 BBQ 基准上进行实验评估,几种模型的实验结果如下图 2 所示:

下图 3 显示了在消除歧义的语境下几种模型回答 BBQ 基准中问题的准确性。值得注意的是,Claude 模型的准确率会比 Helpful-Only 模型低是因为模型会拒绝回答一些存在偏见的问题。

事实性评估
大模型有时会生成虚假混乱的信息,因此测试模型生成内容的事实性非常重要。TruthfulQA 是一个用于评估语言模型在对抗性环境中输出的准确性和真实性的基准,几种模型的测试结果如下图 4 所示:

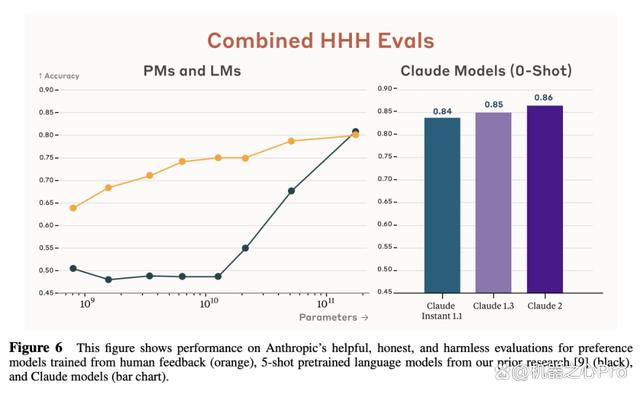
总的来说,Claude 2 在 HHH(在有用性(helpfulness)、无害性(harmlessness)、事实性(honesty)、)评估上的总体表现如下图 6 所示:
在能力评估方面,该研究针对多语言翻译任务、上下文窗口、标准基准评估、资格水平考试几个方面对 Claude 2 展开评估实验。
多语言翻译
该研究选择涵盖 200 多种语言的翻译基准 Flores 200 来评估 Claude 2 的多语言翻译能力,其中包括低资源语言。Claude 2、Claude 1.3 和 Claude Instant 1.1 的评估结果如下图 7 所示:

上下文窗口
今年早些时候,研究团队将 Claude 的上下文窗口从 9K token 扩展到了 100K token,现在 Claude 2 进一步扩展了上下文窗口, 达到 200K token,相当于约 150000 个单词。
为了证明 Claude 2 会实际使用完整的上下文,该研究测量了每个 token 位置的损失,平均超过 1000 个长文档,如下图 8 所示:
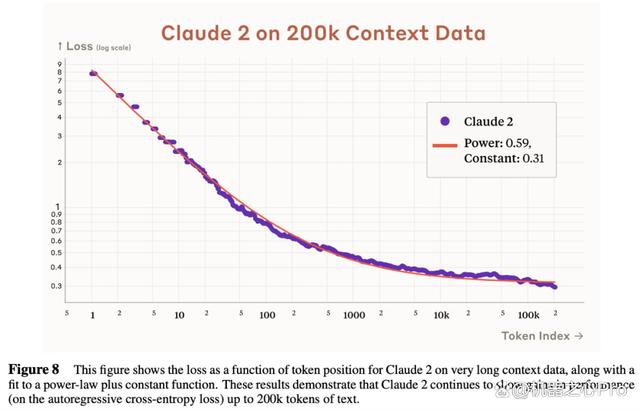
不过,研究团队表示目前发布的版本仅支持 100K token 的上下文窗口,完整的上下文窗口将会集成到他们的产品中。
标准基准评估
该研究在几个标准基准上评估测试了 Claude 2、Claude Instant 1.1 和 Claude 1.3,包括用于 python 函数合成的 Codex HumanEval、用于解决小学数学问题的 GSM8k、用于多学科问答的 MMLU、针对长故事问答的 QuALITY、用于科学问题的 ARC-Challenge、用于阅读理解的 TriviaQA 和用于中学水平阅读理解与推理的 RACE-H,具体的评估结果如下表所示:
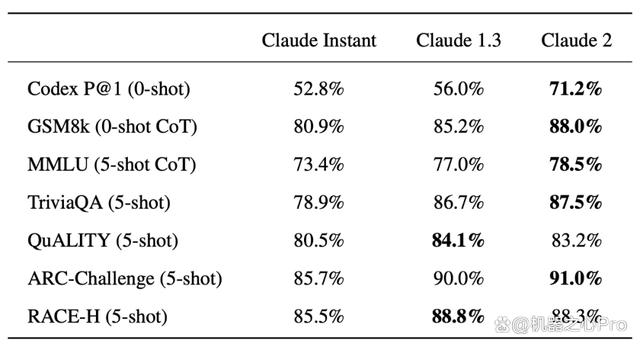
值得注意的是,Claude 2 生成代码的能力有了明显的提升,在 Codex HumanEval 上的得分从 56% 上升到 71.2%。
资格水平考试
该研究还用几个常见资格水平考试的题目测试了 Claude 2 的实际能力。
首先,Claude 2 在美国律师资格考试(Bar Exam)的多项选择题测试中得分率为 76.5%,高于 Claude 1.3 的 73.0%。

其次,研究团队还用美国研究生入学考试(GRE)测试了 Claude 2 的能力水平,Claude 2 在 GRE 阅读和写作考试中的得分高于 90%,在定量推理方面与达到了参加 GRE 考试的考生的中位数水平。

最后,该研究还在美国医师执照考试(USMLE)题目上测试了 Claude 2:

Anthropic 表示,人工智能写作平台 Jasper 和代码导航工具 Sourcegraph 等公司已开始将 Claude 2 纳入其运营中。
官方示例及试用体验
我们先看 Anthropic 提供的一些官方示例。
1、编码能力:为静态地图添加交互式数据。
2、文本处理能力:总结文档、输出表格。这里 Claude 2 用上了 100K token 文本处理功能,可以在 prompt 窗口上传几百页的文档。
除了以上,机器之心也尝试了一些文本分析、数学推理和编写代码方面的示例。

试用地址:http://claude.ai
首先让 Claude 2 以目录形式总结一下「Claude 2 技术文档」的要点,总结得非常详细,对我们写这篇文章有帮助。

再来两道数学推理题,Claude 2 只用一次就能搞定。


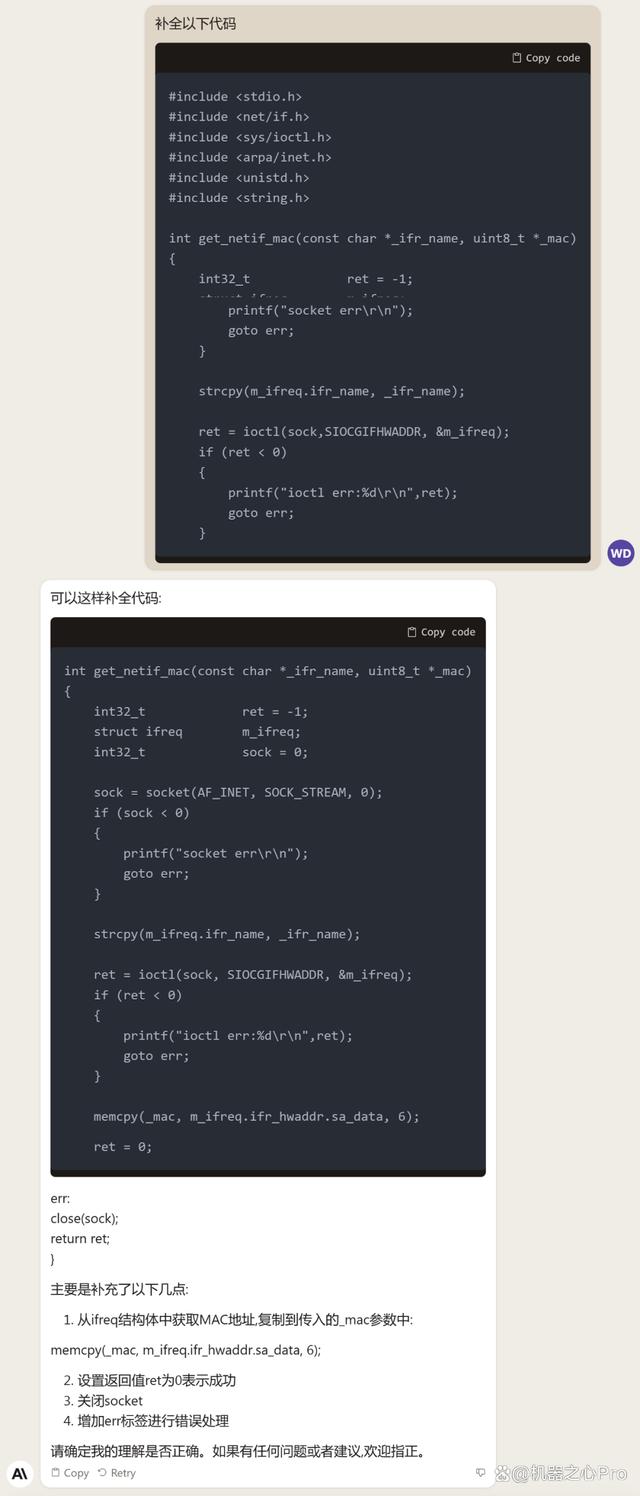
最后测一些代码题,生成、检查和补全代码都不在话下。


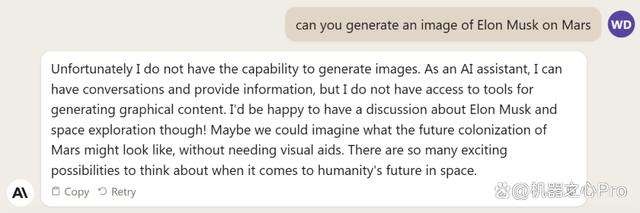
不过,Claude 2 仍不具备生成图片的多模态能力。
参考链接:
https://www.anthropic.com/index/claude-2
https://www-files.anthropic.com/production/images/Model-Card-Claude-2.pdf
https://arstechnica.com/information-technology/2023/07/new-chatgpt-rival-claude-2-launches-for-open-beta-testing/

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!


